ChatGPT训练资源全解析:语料、模型与代码库指南
版权申诉
训练ChatGPT,一个基于大规模语言模型技术的人工智能聊天工具,需要一系列关键的资源支持,包括模型参数、语料和代码库。本指南提供了详细的资源列表和介绍,旨在帮助用户高效地进行模型训练和定制。
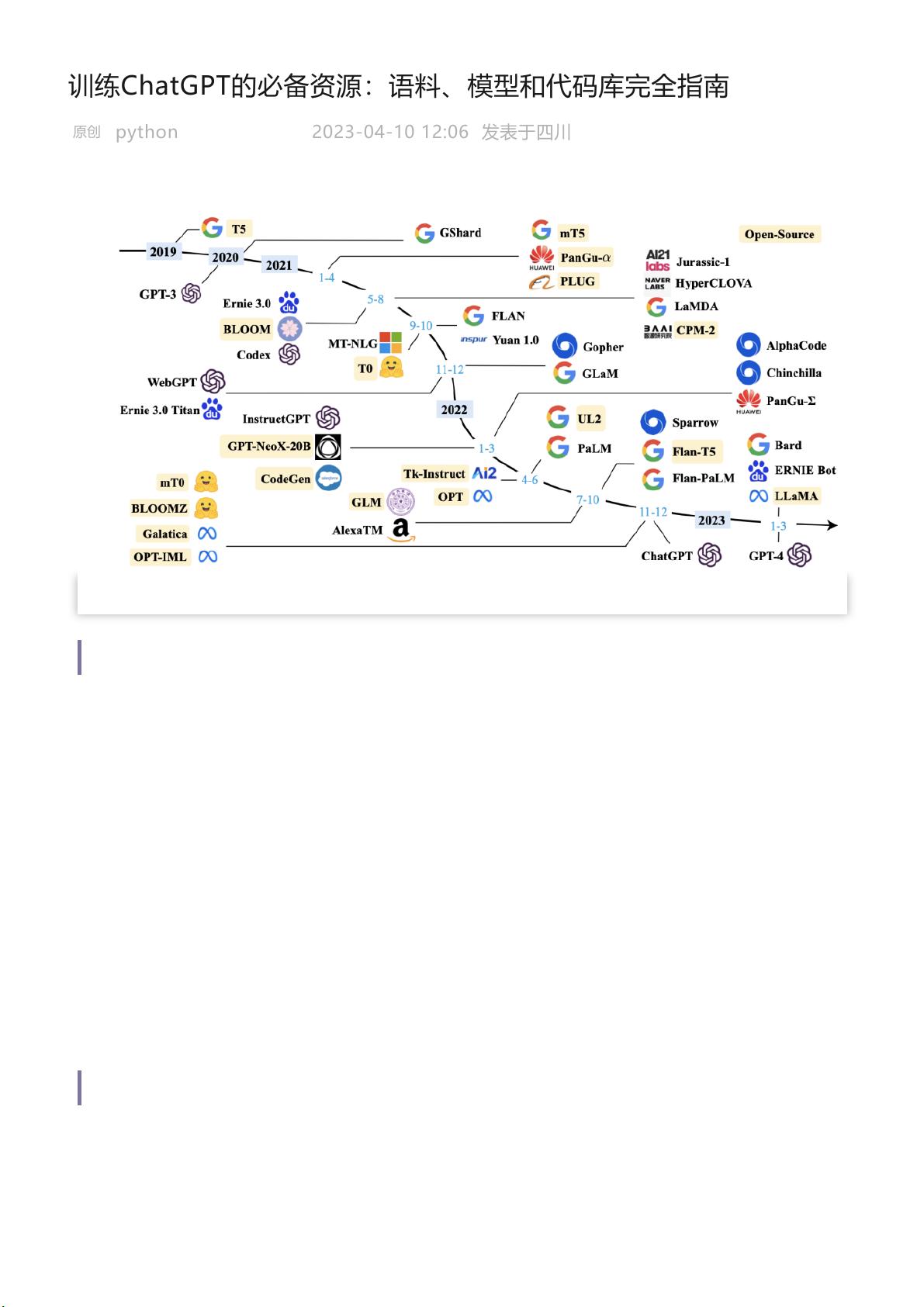
1. **模型参数**:开源的大规模语言模型参数是降低成本的关键。当前可用的模型参数主要分为两类:
- **100亿至1000亿参数模型**:这类模型如LLaMA (650亿参数)、mT5、T0、GPT-NeoX-20B、CodeGen、UL2、Flan-T5、mT0和PanGu-α。它们各自具有特色,例如Flan-T5进行了指令调优,适合多语言交互;CodeGen专注于代码生成;而PanGu-α在中文任务中表现出色,拥有大模型版本。
- **超过1000亿参数模型**:尽管这类模型数量较少,但仍有OPT、OPT-IML、BLOOM、BLOOMZ、GLM和Galactica等,参数量在1000亿至2000亿之间,特别提到的是OPT,它被设计为开源且适用于大型模型训练。
2. **语料**:训练大规模语言模型需要大量的高质量文本数据,这些语料应涵盖广泛的主题和语言风格,以便模型学习到丰富的语言表达和上下文理解。获取合适的语料可以通过爬虫、公开数据集或者自己创建来实现,但确保数据的版权合规性和质量是非常重要的。
3. **代码库**:GitHub上的开源代码库,如RUCAIBox的LLMSurvey项目,提供了训练和微调模型的示例代码,这些代码库可以帮助开发者快速入门和优化模型。这些代码可能包含预处理语料、模型加载、训练策略以及评估指标等组件。
4. **参考资料**:除了上述资源,论文《LLM Survey》(https://arxiv.org/pdf/2303.18223.pdf)提供了对大规模语言模型的全面综述,包括训练方法、性能比较和最佳实践,对于深入理解技术背景和改进模型性能非常有价值。
训练ChatGPT需要选好合适的模型参数作为基础,利用丰富的语料库进行训练,同时参考社区的开源代码库和学术论文,确保遵循最佳实践,才能有效地构建和优化自己的语言模型。
2023/6/28 11:16
训练ChatGPT的必备资源:语料、模型和代码库完全指南
https://mp.weixin.qq.com/s/6enOkW7pZsMeTpc4SODwSQ
1/7
训练ChatGPT的必备资源:语料、模型和代码库完全指南
文 | python
前言
近 期, ChatGPT 成 为 了全 网 热议 的 话题。 ChatGPT 是 一 种基 于 大规 模 语言 模 型技术 ( LLM ,
large language model)实现的人机对话工具。但是,如果我们想要训练自己的大规模语言模
型,有哪些公开的资源可以提供帮助呢?在这个github项目中,人民大学的老师同学们从模型
参数(Checkpoints)、语料和代码库三个方面,为大家整理并介绍这些资源。接下来,让我
们一起来看看吧。
资 源 链 接 :
https://github.com/RUCAIBox/LLMSurvey
论 文 地 址 :
https://arxiv.org/pdf/2303.18223.pdf
模型参数
从已经训练好的模型参数做精调、继续训练,无疑可以极大地降低计算成本。那目前有哪些开
源的大模型参数,可以供我们选择呢?
python 2023-04-10 12:06 发表于四川
原创
夕小瑶科技说
下载后可阅读完整内容,剩余6页未读,立即下载
2023-10-11 上传
2024-03-14 上传
2023-05-12 上传
2023-06-06 上传
2024-10-18 上传
2023-06-06 上传
2023-06-06 上传
2023-06-06 上传

普通网友
- 粉丝: 1272
- 资源: 5619
 我的内容管理
展开
我的内容管理
展开







