SPSS变量级别数据管理实战指南
32 浏览量
更新于2024-06-28
收藏 990KB PPT 举报
"该PPT主要讲解了变量级别的数据管理,包括计算新变量、变量转换、专用过程以及如何使用SPSS进行数据处理。"
在数据分析和管理中,变量级别的数据管理是一个关键环节,它涉及到对已有数据进行操作,以生成新的信息或者改进数据质量。在SPSS(Statistical Package for the Social Sciences)这一统计分析软件中,提供了多种工具来进行这样的操作。
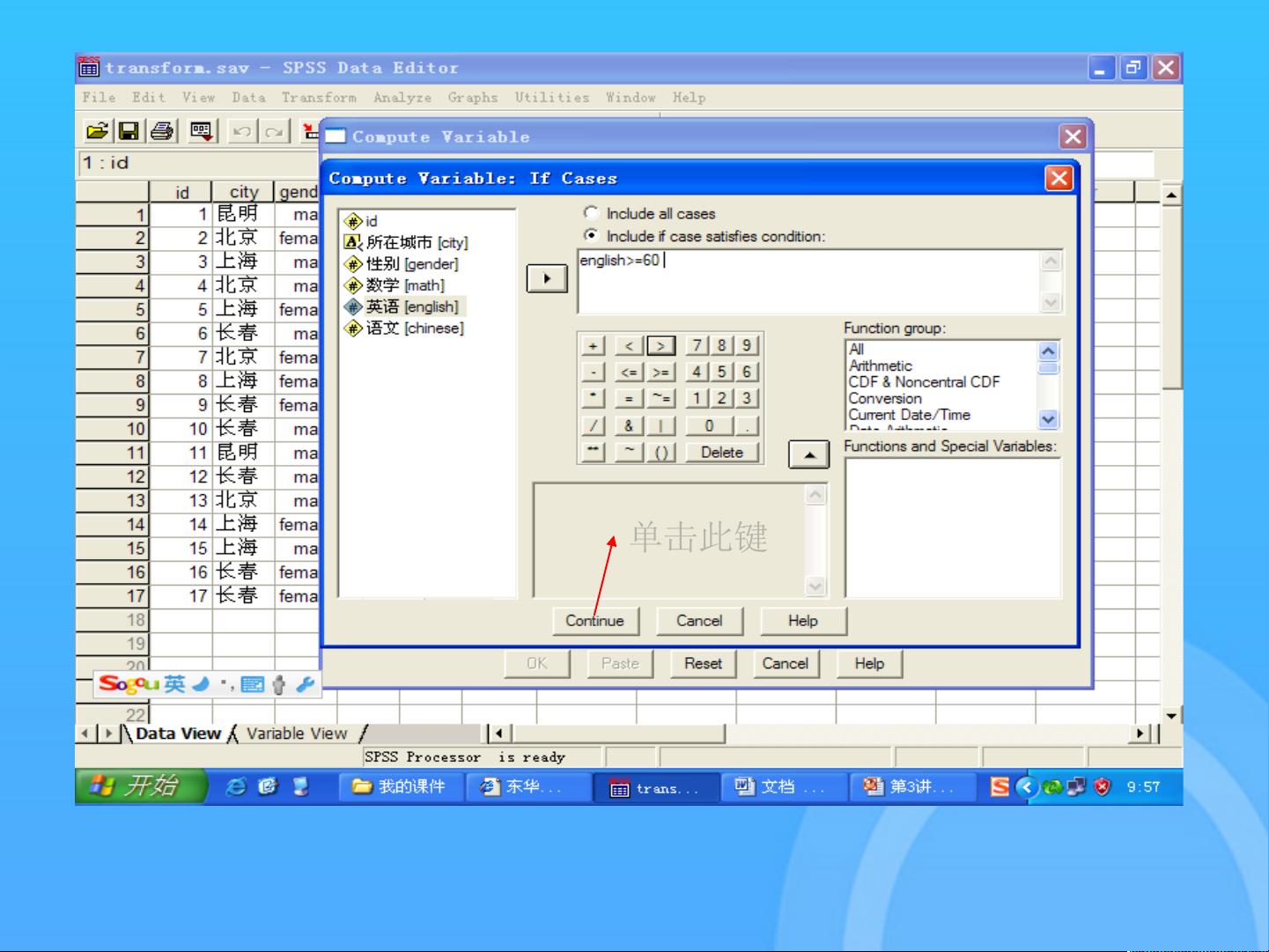
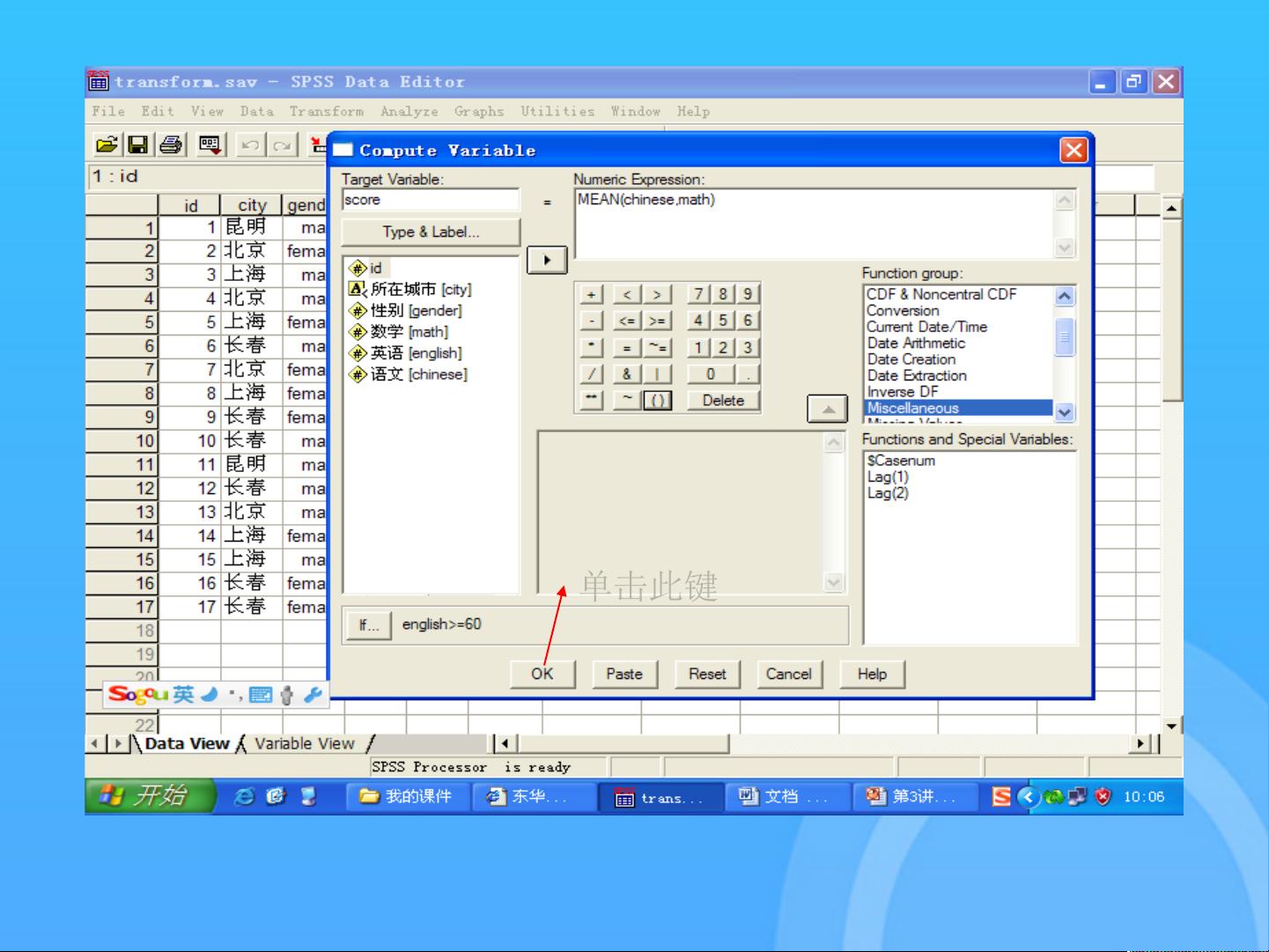
首先,计算新变量是数据管理的核心任务之一。通过`Compute Variable`过程,用户可以定义新的变量,这通常涉及到使用SPSS表达式和函数对现有数据进行计算。例如,如果需要基于现有变量创建一个新的统计指标,或者对满足特定条件的记录进行特定计算,都可以通过这个过程实现。新变量既可以是全新的,也可以重用现有的变量空间。
变量转换则是数据预处理的重要步骤。`Visual Bander`允许用户对数据进行分组,比如可以将数值变量按照一定的区间划分,形成新的类别变量。此外,`Record`、`Count`、`Rank`等过程则分别用于记录处理、计数和排序。例如,`RankCases`可以按某个变量的值对所有记录进行排序,这对于数据分析和后续建模尤其有用。
专用过程则涉及更复杂的数据处理,如建立时间序列模型,这在处理具有时间依赖性的数据时非常关键。同时,处理缺失值是数据清洗的常规步骤,可以使用各种方法进行替换,如平均值、中位数等。此外,设定随机种子能确保每次运行相同代码时得到可重复的结果,这对于实验设计和模拟研究非常重要。
在实际操作中,掌握如何编写和运用这些语句能够极大地提高数据处理的效率和精度。例如,`AutomaticRecode`可以自动化地将某些变量的特定值重新编码,比如在示例中,将`grade`中的"优秀"、"良好"和"及格"合并为"PASS",而"及格"转化为"NOPASS"。
最后,`RunPendingTransform`是一个实用的功能,它能执行在编程过程中被挂起的数据文件转换,确保所有预定义的转换都能在适当的时间点得以实施。
变量级别的数据管理涵盖了从基础的变量创建到复杂的预处理步骤,熟练掌握这些技巧对于提升数据质量和分析的有效性至关重要。通过SPSS提供的工具和过程,用户可以更加灵活且高效地管理和操作数据。
单
单
击
击
此
此
键
键
剩余35页未读,继续阅读
2022-12-02 上传
2022-12-01 上传
2022-12-01 上传
2022-12-01 上传
2022-12-01 上传
2022-11-30 上传

xinkai1688
- 粉丝: 389
- 资源: 8万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- kubernetes-kms:for适用于Kubernetes的Azure Key Vault KMS插件
- Data_Explore_py_pandas_Professional_nanodegree_program:具有一些基本描述性统计信息的用户交互式数据探索程序
- IntelligentAgentsAssignment:第一次尝试在非常简单的环境中实现信念-愿望-意图模型
- flash元件批量改名命令(jsfl)
- fullstackopen:赫尔辛基大学
- Calendar2.rar
- vscode-mono-debug:一个简单的VS Code调试适配器,用于单声道
- packtools:用于处理SciELO PS XML文件的Python库和命令行实用程序
- 使用 MATLAB 进行信用风险建模:这些是 MathWorks 网络研讨会的同名 MATLAB 支持文件。-matlab开发
- 采购管理工程招投标流程
- CBB-Stats
- 12.XGBoost_data.rar
- 电子功用-基于电压跟踪的锂电池剩余电量的计量方法
- 皇家型
- android:android相关代码和示例
- 采购与仓储管理
