Kettle数据同步策略详解
"kettle同步涉及到了数据同步的各种场景,包括只增加、只更新、增加+更新以及增加+更新+删除四种类型。Repository是kettle存储元数据的地方,它由多张数据表组成,用于在资源库模式下保存transformation和job。在处理不同的数据同步需求时,kettle提供了多种步骤,如‘表输入’、‘更新’、‘插入/更新’和‘合并记录’等。"
在数据同步的过程中,kettle扮演着重要的角色,它能够有效地处理各种数据迁移和转换任务。Repository是kettle的核心组件之一,它是一个存储元数据的数据库,用于保存用户在设计transformation和job时的所有信息。通过Repository,用户可以方便地管理和版本控制自己的数据处理流程。
针对只增加数据的场景,如果基表存在更新字段,可以通过"表输入"步骤结合SQL查询条件来读取新增数据;若基表不存在更新字段,可以利用"插入/更新"步骤来确保数据仅被插入而不会覆盖已有数据。
对于只更新的情况,可以使用"更新"步骤来针对性地更新目标表中的数据,而不会引入新的记录。在增加+更新的场景下,"插入/更新"步骤可以同时处理新增和更新的操作,只需取消"不执行任何更新"的选项。
当需要处理增加、更新和删除的复杂情况时,kettle提供了两种策略。如果源库保留了增删改信息,可以直接通过条件判断执行相应的操作;如果源库没有这样的信息,"合并记录"步骤就派上用场,它比较新旧两个数据源的关键字和域值,根据结果标记出"Identical"、"changed"、"new"和"deleted"四种状态,从而实现增量更新。
以上内容展示了kettle如何灵活应对各种数据同步需求,通过Repository管理元数据,并利用特定步骤进行数据处理,确保数据的一致性和完整性。在实际应用中,用户可以根据具体业务需求选择合适的方法来实现数据同步,确保数据仓库或数据湖的准确性和时效性。
同步数据常见的应用场景包括以下 4 个种类型:
Ø只增加、无更新、无删除
Ø只更新、无增加、无删除
Ø增加+更新、无删除
Ø增加+更新+删除
1 只增加、无更新、无删除
对于这种只增加数据的情况,可细分为以下 2 种类型:
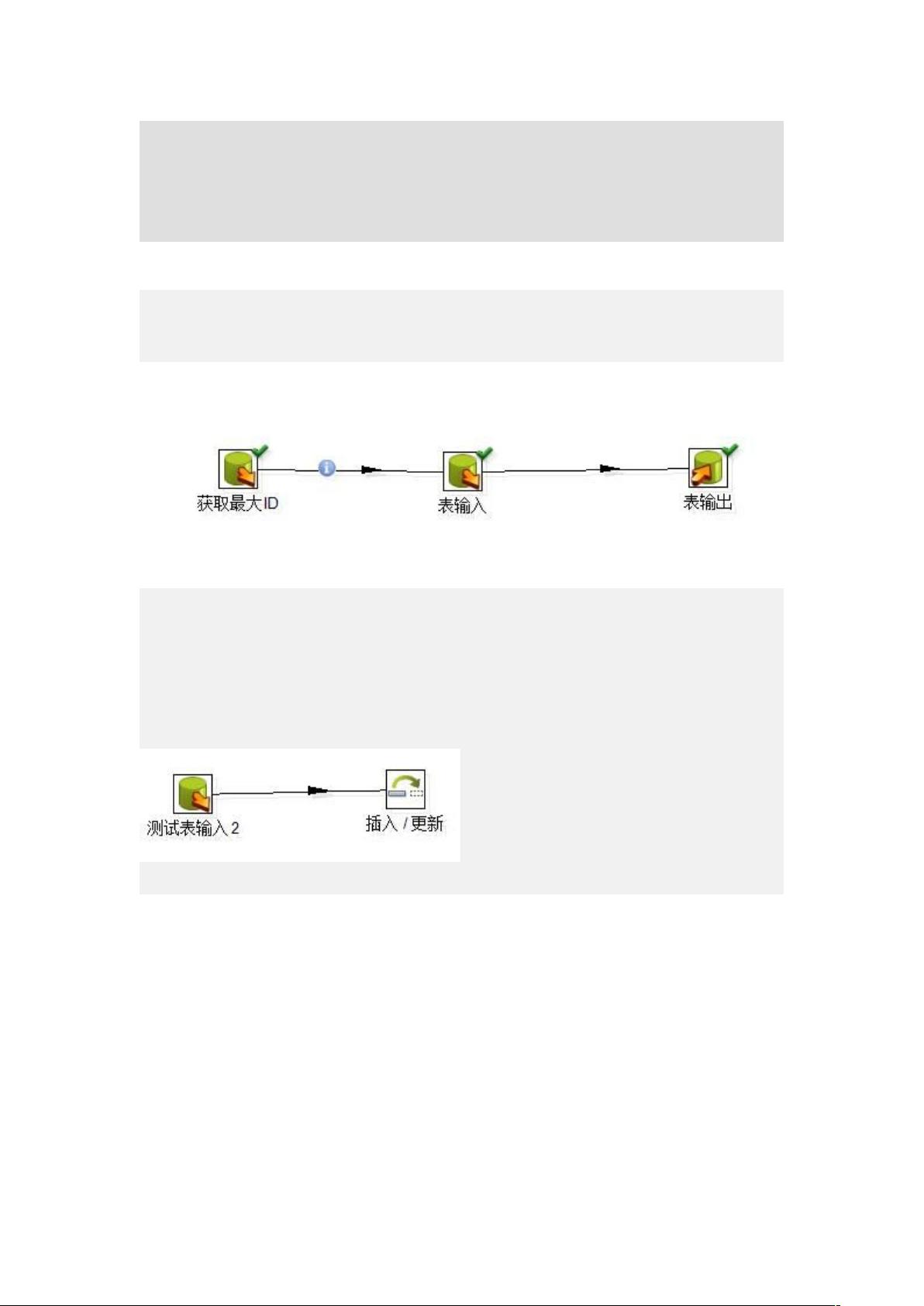
1) 基表存在更新字段。
通过获取目标表上最大的更新时间或最大 ID,在“表输入”步骤中加入条件限制只读取新增的数据。
这里要注意的是,获取最大更新时间或最大 ID 时,如果目标表还没有数据,最大值会获取不了。其中的
一个解决方法是在“获取最大 ID”步骤的 SQL 中,加入最小日期或 ID 的联合查询即可,如:
SELECT MAX(ID) FROM
(SELECT MAX(ID) AS ID FROM T1 UNION ALL SELECT 0 AS ID FROM DUAL)
2) 基表不存在更新字段。
通过“插入/更新”步骤进行插入。
插入/更新步骤选项:
下载后可阅读完整内容,剩余6页未读,立即下载
点击了解资源详情
点击了解资源详情
点击了解资源详情
172 浏览量
2024-06-25 上传
2024-06-25 上传
2023-04-05 上传
2024-03-02 上传
2019-10-24 上传

qq_25322853
- 粉丝: 0
- 资源: 7
 我的内容管理
展开
我的内容管理
展开







最新资源
- matlab教程关于命令方面
- SQL2005语句详解
- ASP.net中md5加密码的方法
- 内存调试技巧:C 语言最大难点揭秘
- 随着计算机的发展和普及,计算机系统数量与日俱增,为了保证计算机系统安全可靠工作,网络监控系统的应用也日渐广泛。本文主要介绍机房网络监控系统的现状和发展。
- ORACLE财务讲解.pdf
- 计算机外文翻译基于J2EE
- 所有的网络协议关系(ip,udp,tcp)
- 高质量C、C++编程指南
- 动态抓取网页内容,蜘蛛程序
- 会话初始协议(SIP)第三方呼叫控制的研究
- 网络工程师必懂的十五大专业术语
- 高质量C_C编程指南
- 浅谈E1线路维护技术与应用.doc
- java试题及答案下载
- Delphi 7 程序设计与开发技术大全
