Scala中的极致智能:函数式数据结构实现
需积分: 7 183 浏览量
更新于2024-07-29
收藏 3.87MB PDF 举报
“ExtremeCleverness Functional Data Structures in Scala”是一份关于在Scala中实现高效功能数据结构的演讲稿,源自Strange Loop 2011会议,由Daniel Spiewak主讲。
在这篇文档中,作者强调了使用不可变数据结构(Immutable, immutable, immutable)的重要性,这是函数式编程的核心原则之一。不可变数据结构的优势在于它们可以提供线程安全、易于理解和测试的代码,同时避免了副作用。然而,仅靠不可变性还不够,我们还需要在性能方面达到与可变数据结构相当的水平,同时保持完全持久性(full persistence),这意味着对数据结构进行修改时,旧版本仍然可用。
文档讨论了如何实现一系列功能数据结构来满足这些需求:
1. **Sequential Data Structures**:这些数据结构主要用于线性操作,如列表。例如:
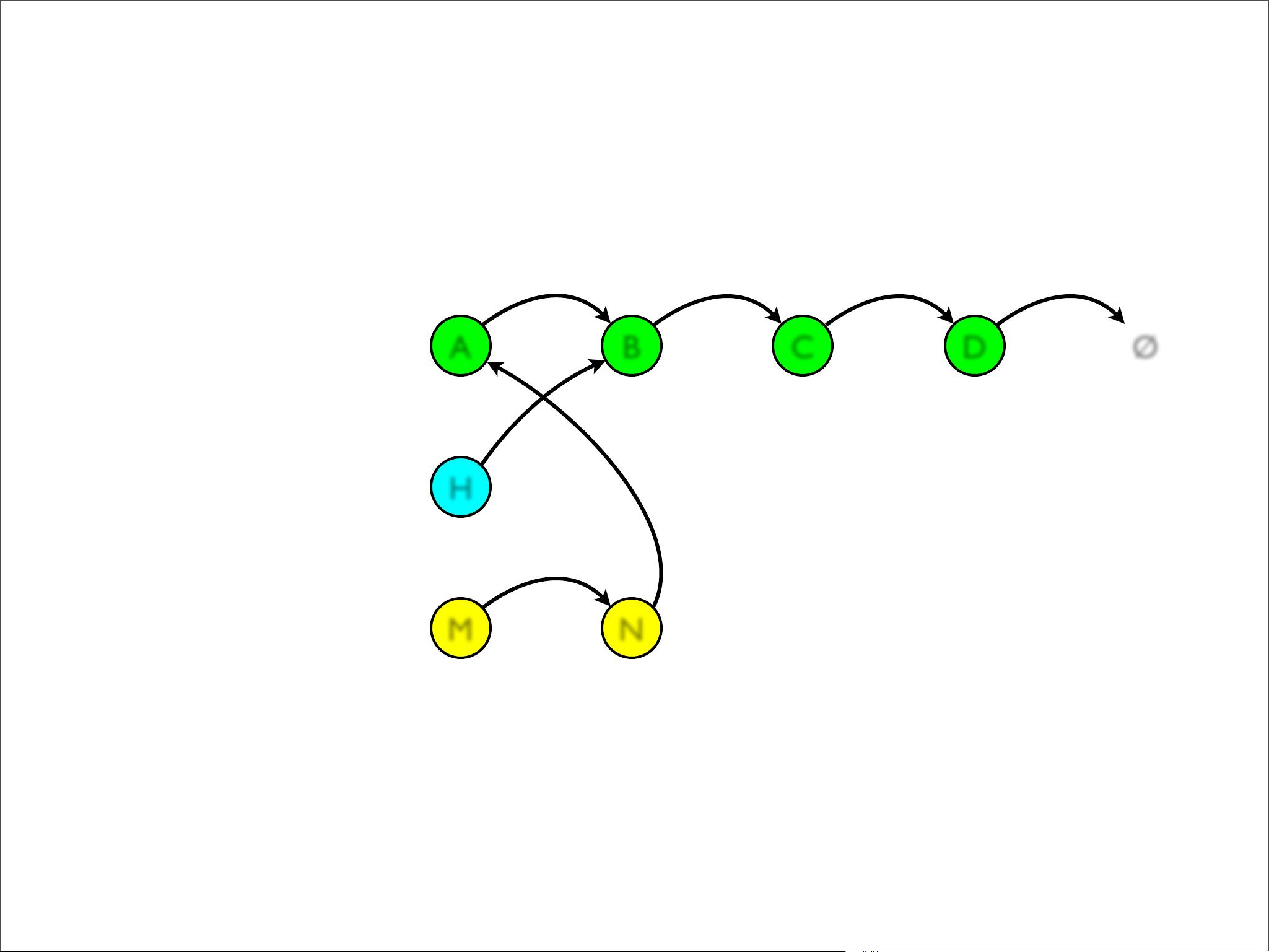
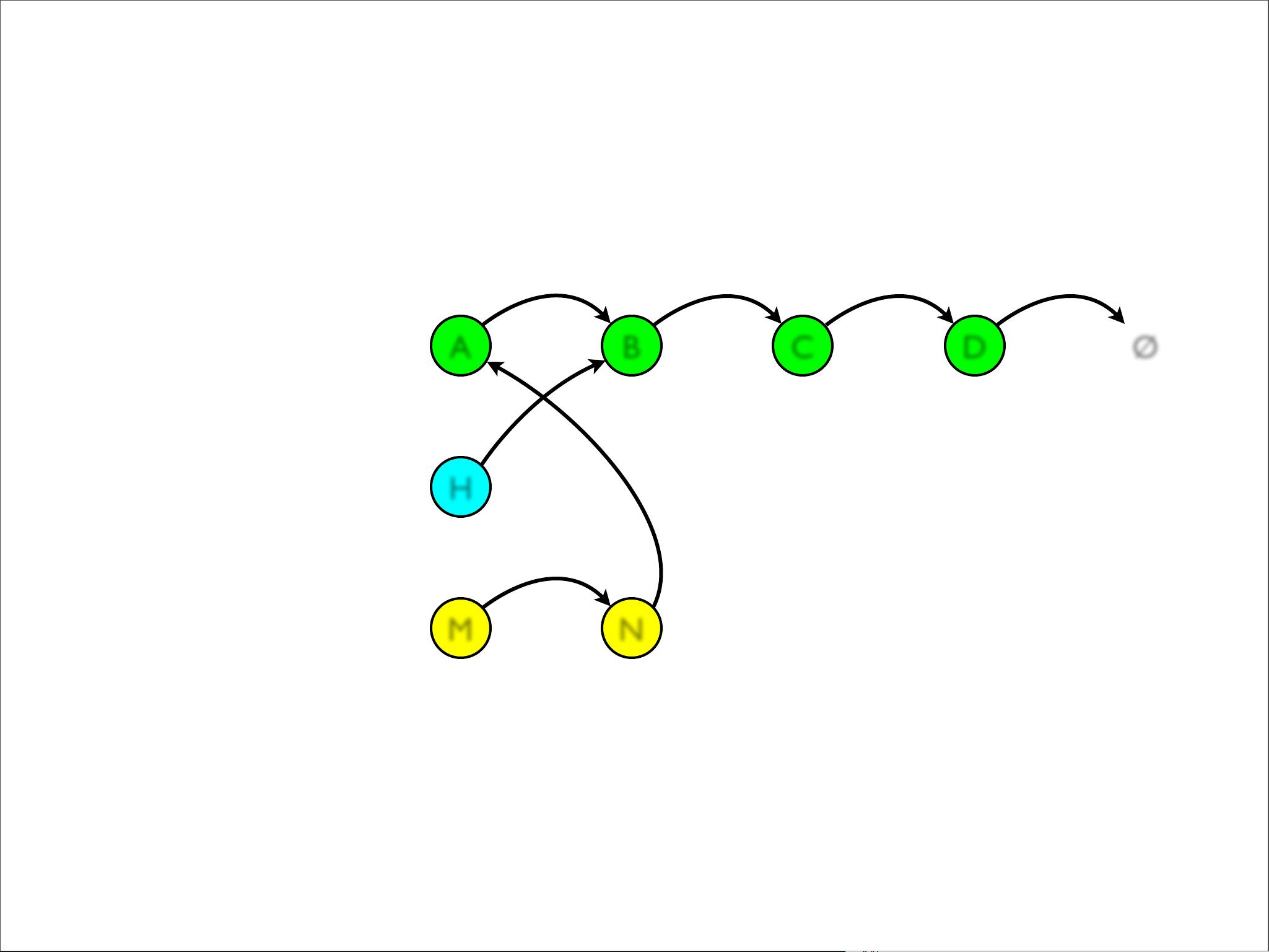
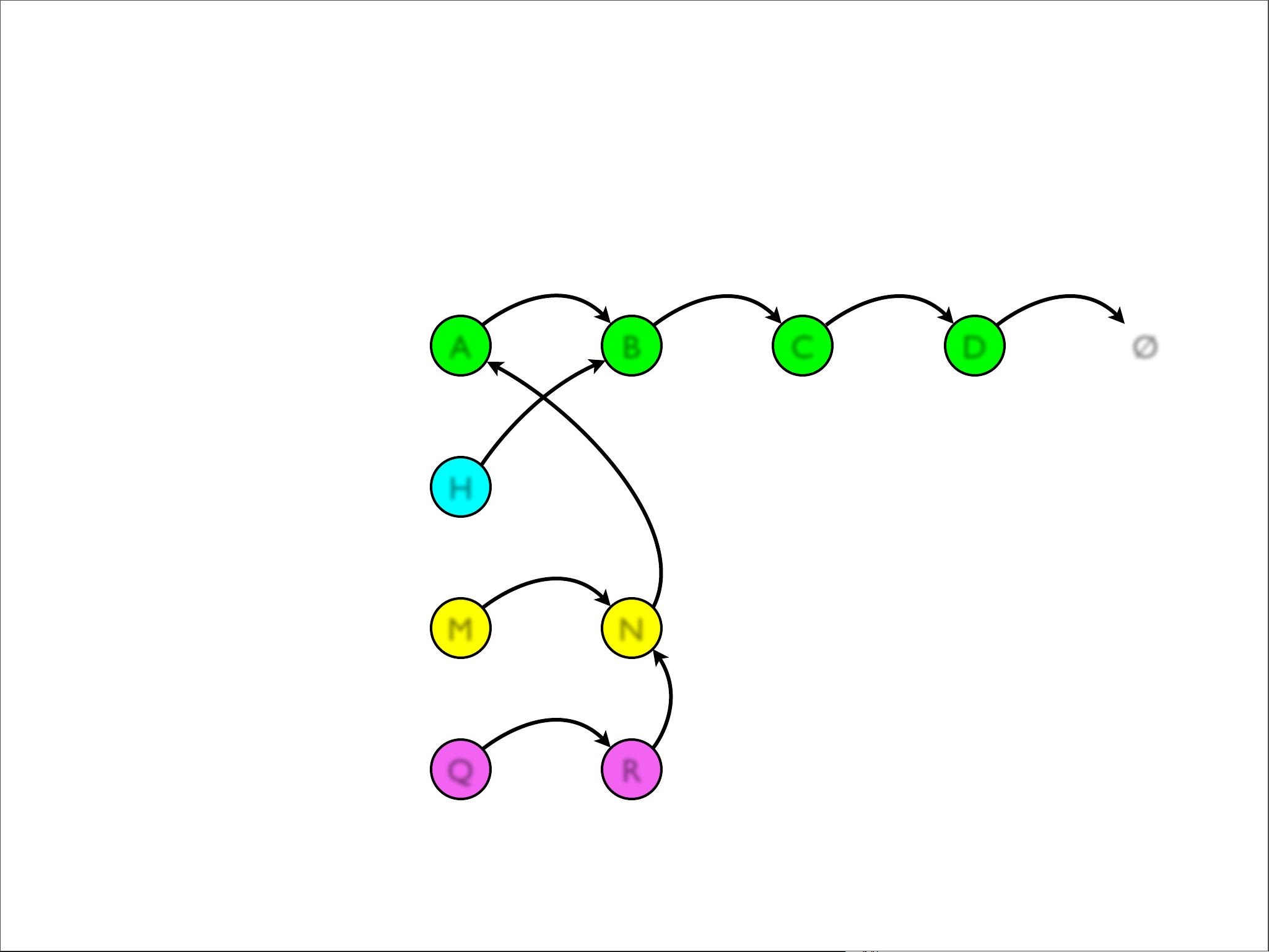
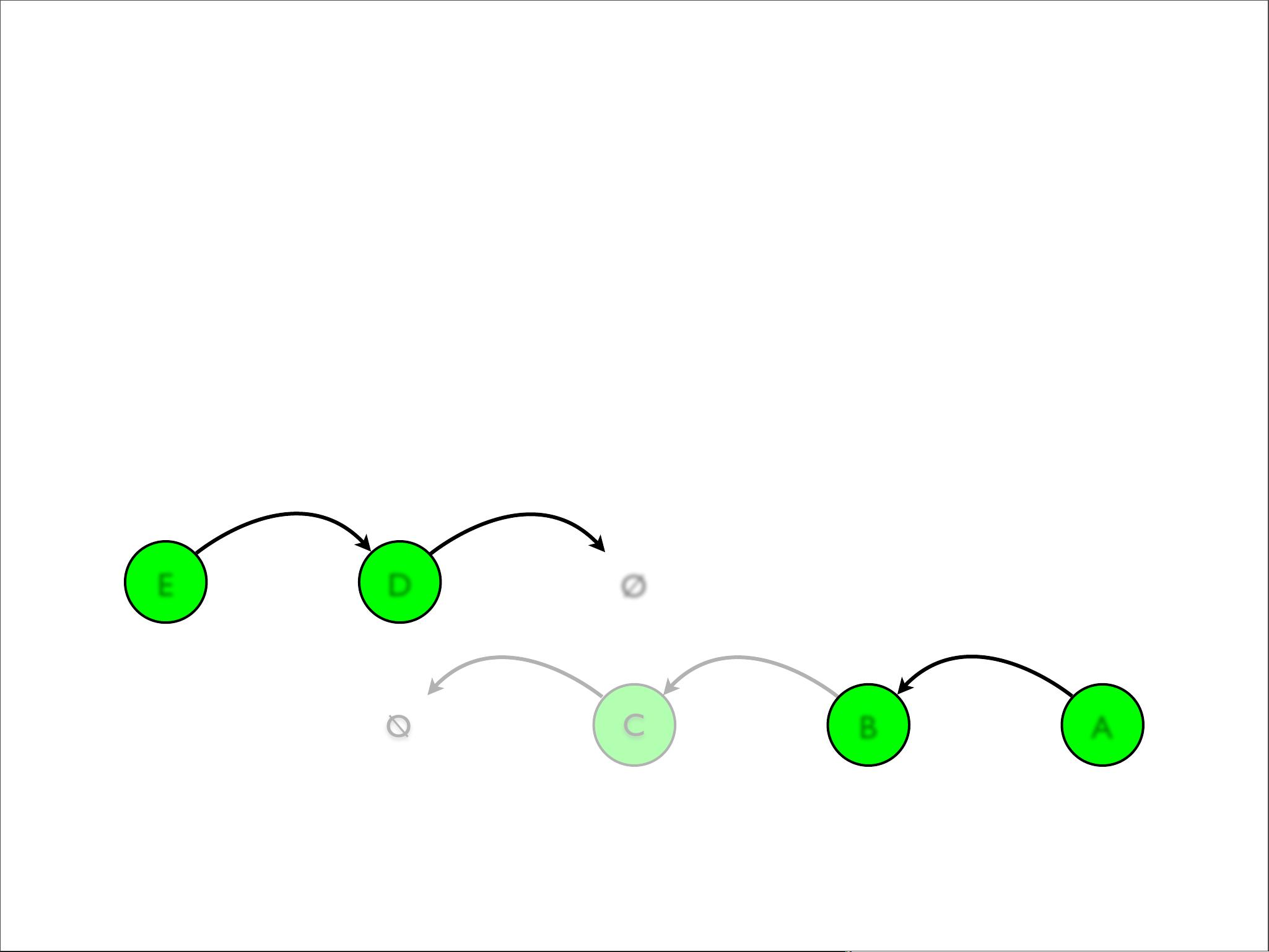
- **Singly-Linked List**:一个简单的链表,由头节点(hd)和尾节点(tail)组成,可以快速地进行头部插入(prepend)和尾部追加(append)。但其他操作,如中间插入(insert)、获取中间元素(nth)和连接两个列表(concat)的效率较低。
- **Banker's Queue**:一种优化的队列实现,通过避免尾部的移动来提高性能。
- **2-3 Finger Tree**:一种更复杂的数据结构,它提供了高效的顺序访问和插入操作,同时支持多种操作,如查找和分割。
2. **Associative Data Structures**:这类数据结构通常用于存储键值对,如哈希表或树。虽然文档未详细描述,但通常会涉及平衡树结构(如AVL或红黑树)来保证在平均情况下的常数时间复杂度。
为了优化不可变数据结构,文档提到了**结构性共享(Structural Sharing)**的概念。这种技术允许在不创建全新数据结构的情况下,通过共享大部分不变的部分来实现修改。例如,当在列表中插入一个元素时,只需要创建一个新的头节点,而旧列表的其余部分则可以被引用,从而减少内存开销。
此外,文档还考虑了现代计算机架构的影响,特别是缓存局部性和多核处理。功能数据结构设计时必须考虑这些因素,以确保在并行计算环境中也能保持高性能。
这份文档深入探讨了如何在Scala中利用不可变性、结构性共享和其他技巧来构建高效的功能数据结构,同时也关注了这些结构在现代硬件环境中的表现。对于想要深入理解Scala和函数式编程的开发者来说,这是一个宝贵的资源。

2024-12-03 上传

cxzav
- 粉丝: 4
- 资源: 83
 我的内容管理
展开
我的内容管理
展开







最新资源
- Angular程序高效加载与展示海量Excel数据技巧
- Argos客户端开发流程及Vue配置指南
- 基于源码的PHP Webshell审查工具介绍
- Mina任务部署Rpush教程与实践指南
- 密歇根大学主题新标签页壁纸与多功能扩展
- Golang编程入门:基础代码学习教程
- Aplysia吸引子分析MATLAB代码套件解读
- 程序性竞争问题解决实践指南
- lyra: Rust语言实现的特征提取POC功能
- Chrome扩展:NBA全明星新标签壁纸
- 探索通用Lisp用户空间文件系统clufs_0.7
- dheap: Haxe实现的高效D-ary堆算法
- 利用BladeRF实现简易VNA频率响应分析工具
- 深度解析Amazon SQS在C#中的应用实践
- 正义联盟计划管理系统:udemy-heroes-demo-09
- JavaScript语法jsonpointer替代实现介绍
