Lucene 3.1教程:性能提升与关键功能详解
本教程详细介绍了Lucene 3.1的最新特性及其应用,Lucene作为一款强大的全文搜索引擎库,3.1版本在性能、可扩展性和用户体验上做出了显著改进。以下是一些关键知识点:
1. **性能提升**:Lucene 3.1着重优化了搜索效率,可能是通过改进算法或数据结构,使得在大规模数据检索时表现出更好的速度和响应。
2. **ReusableAnalyzerBase**:引入了一个新的基础类,使得开发者能够更轻松地重用TokenStreams,提高代码复用性和可维护性。
3. **Unicode支持**:3.1版本增强了对Unicode 4的支持,确保在处理非ASCII字符集时的准确性。
4. **ConstantScoreQuery**:Query对象的封装得到了简化,用户可以直接创建ConstantScoreQuery,提高了查询构建的灵活性。
5. **配置IndexWriter**:IndexWriterConfig现在提供了更多的选项来调整索引的创建和更新行为,增强定制性。
6. **API变更**:IndexWriter.getReader()方法已被IndexReader.open()替代,反映了Lucene在API设计上的演进。
7. **MultiSearcher和ParallelMultiSearcher**:旧有的多线程搜索模块被整合到IndexReader,提升了并发性能。
8. **MMapDirectory**:在64位平台上,默认目录实现改为MMapDirectory,有助于内存映射和性能优化。
9. **TotalHitCountCollector**:新引入的Collectors用于获取索引的命中总数,方便统计搜索结果。
10. **ReaderFinishedListener**:提供了一种清理外部缓存的方法,有助于资源管理和性能管理。
在实际应用中,Lucene 3.1主要用于站内搜索,如论坛、博客文章或在线商店的商品搜索,而互联网搜索由于数据量大和管理复杂通常不在其主要应用场景内。学习并掌握Lucene 3.1能够帮助开发者构建高效、精确的文本搜索功能,尤其是在处理大量本地数据时。
本教程的价值在于帮助读者理解和实践Lucene 3.1的优化特性,从而在项目开发中更好地利用这个强大的搜索引擎库。通过理解并应用这些改进,开发者可以提升应用的搜索性能和用户体验。
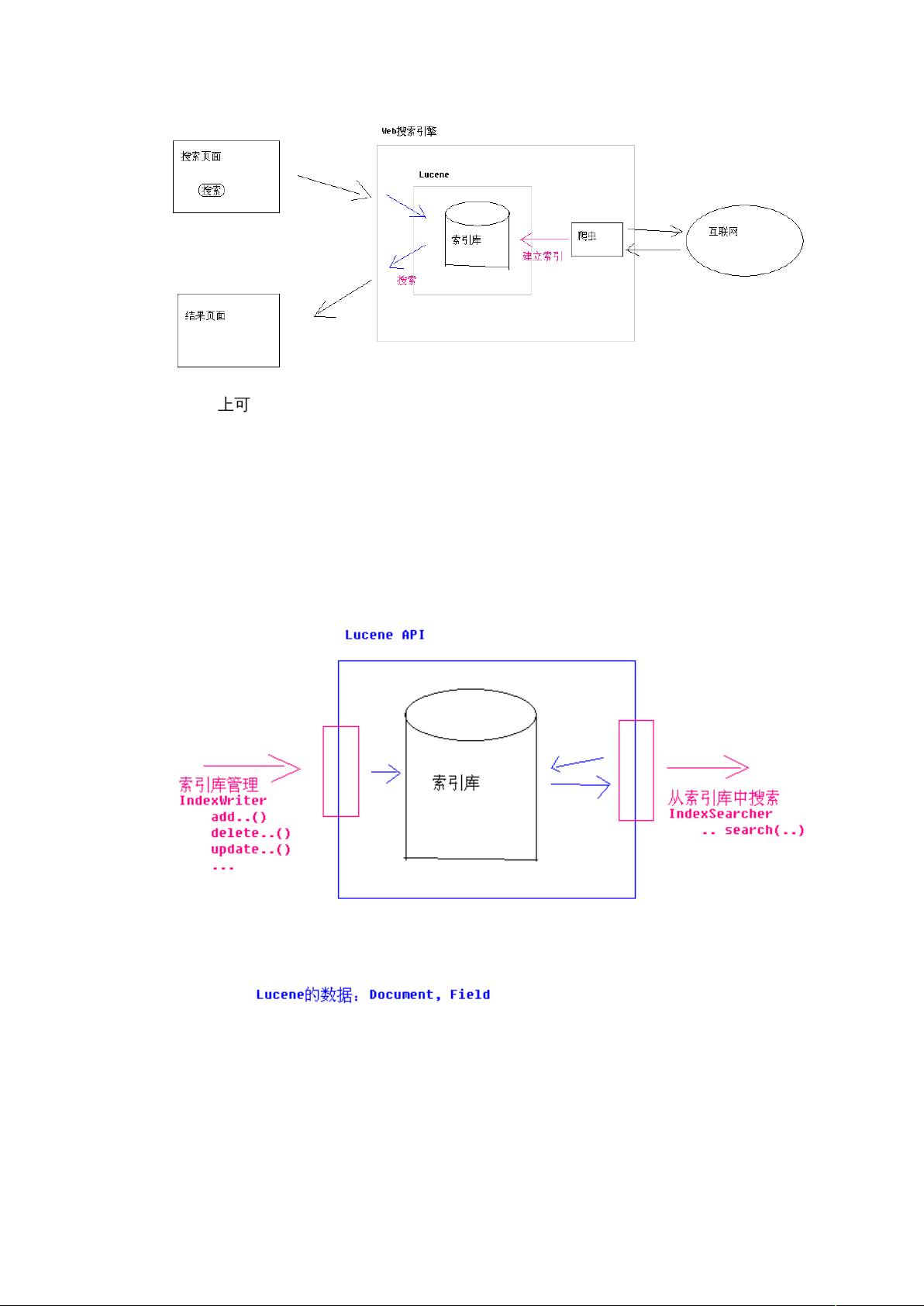
从图片上可以看出,我们不仅要搜索,还要保证数据集合与索引库的一致性。所以对
于全文检索功能的开发,要做的有两个方面:索引库管理(维护索引库中的数据)、在索
引库中进行搜索。而 Lucene 就是操作索引库的工具。
1.2. 使用 Lucene 的 API 操作索引库
索引库是一个目录,里面是一些二进制文件,就如同数据库,所有的数据也是以文件
的形式存在文件系统中的。我们不能直接操作这些二进制文件,而是使用 Lucene 提供的
API 完成相应的操作,就像操作数据库应使用 SQL 语句一样。
对索引库的操作可以分为两种:管理与查询。管理索引库使用 IndexWriter,从索引
库 中 查 询 使 用 IndexSearcher 。 Lucene 的 数 据 结 构 为 Document 与
剩余18页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2024-06-27 上传
2019-03-21 上传
2017-03-26 上传
2012-10-10 上传
2018-04-22 上传
2024-03-26 上传

shanshu12
- 粉丝: 17
- 资源: 16
 我的内容管理
展开
我的内容管理
展开







最新资源
- 王珊 高等教育出版社 数据库第四版答案
- .net 软件自动化测试之道 pdf (.net平台下自动化测试必备之资料,精!!)
- 基于模糊预测算法的ATO仿真研究
- 3g技术讲解通信工程
- c#各种排序算法大全
- Cognos8.4新增功能优势说明
- JAVA基础面试题部分参考
- 段程序保存为文件名为Test.java的文件
- 影碟出租管理信息系统
- JAVA的学习笔记及开发模式
- Learning Oracle PL-SQL [O'Reilly, 524s, 2001r].pdf
- flash 适合于初学者的程序设计教程
- Visual C++开发工具与调试技巧整理
- 操作系统中的银行家算法
- Redhat Linux 9教学讲义
- RSVP协议端到端QOS控制机制的研究
