"Python机器学习实战:语音识别编程案例详解"
版权申诉
随着科技的迅速发展,语音识别技术逐渐成为人们生活中的重要组成部分。语音识别是指通过机器对口语进行识别和理解的过程。通过输入音频数据,语音识别器能够处理这些数据,并从中提取出有用的信息。这一技术在日常生活中有着广泛的应用,例如声音控制设备、将语音转换成文字、安全系统等。
然而,语音信号的多样性和复杂性给语音识别技术的研究和发展带来了挑战。在同一种语言中,人们的语音表达方式可能存在很多不同的变化,如语言、情绪、语调、噪声、口音等。这些因素使得很难定义一组固定的规则来构建语音识别系统。尽管如此,人类在日常交流中仍然可以很轻松地理解这些变化,使得语音识别技术成为研究者们关注的焦点。
在过去的几十年中,研究者们对语音识别的各个方面进行了研究,涉及识别说话者、理解单词、识别口音、翻译语音等。在所有的这些任务中,自动语音识别成为众多研究者的关注点。在这种背景下,本文将介绍如何构建一个语音识别器,帮助读者更深入地了解语音识别技术。
本文的第7章中介绍了一系列主题,包括读取和绘制音频数据、将音频信号转换为频域、自定义参数生成音频信号、合成音乐、提取频域特征、创建隐马尔科夫模型以及创建一个语音识别器。通过学习这些主题,读者可以逐步理解并掌握构建语音识别系统的关键技术和方法。
首先,本章讲述了如何读取音频文件并将信号进行可视化展示。这一步骤是构建语音识别系统的一个良好的开始,可以帮助我们更好地理解音频信号的特性和结构。接着,文中介绍了将音频信号转换为频域的方法,以及如何提取频域特征。这些技术对于从音频数据中提取有用信息和特征至关重要。
此外,本文还介绍了如何自定义参数生成音频信号,并探讨了如何合成音乐。这些内容为读者提供了更多关于音频数据处理和分析的实际操作经验。最后,文中讨论了如何使用隐马尔科夫模型构建一个语音识别器。隐马尔科夫模型是一种用于建模时序数据的重要方法,对于语音识别领域具有重要的应用价值。
总的来说,通过本文的学习,读者可以了解语音识别技术的基本原理和方法,并掌握构建一个语音识别器所需的关键技术。语音识别技术虽然面临着各种挑战,但随着科技的不断进步和研究的深入,我们相信这一技术将会在未来得到更广泛的应用和发展。希望本文能够为读者在语音识别领域的学习和研究提供一些帮助和启发。
134 第7 章 语音识别
plt.ylabel('Amplitude')
plt.title('Audio signal')
plt.show()
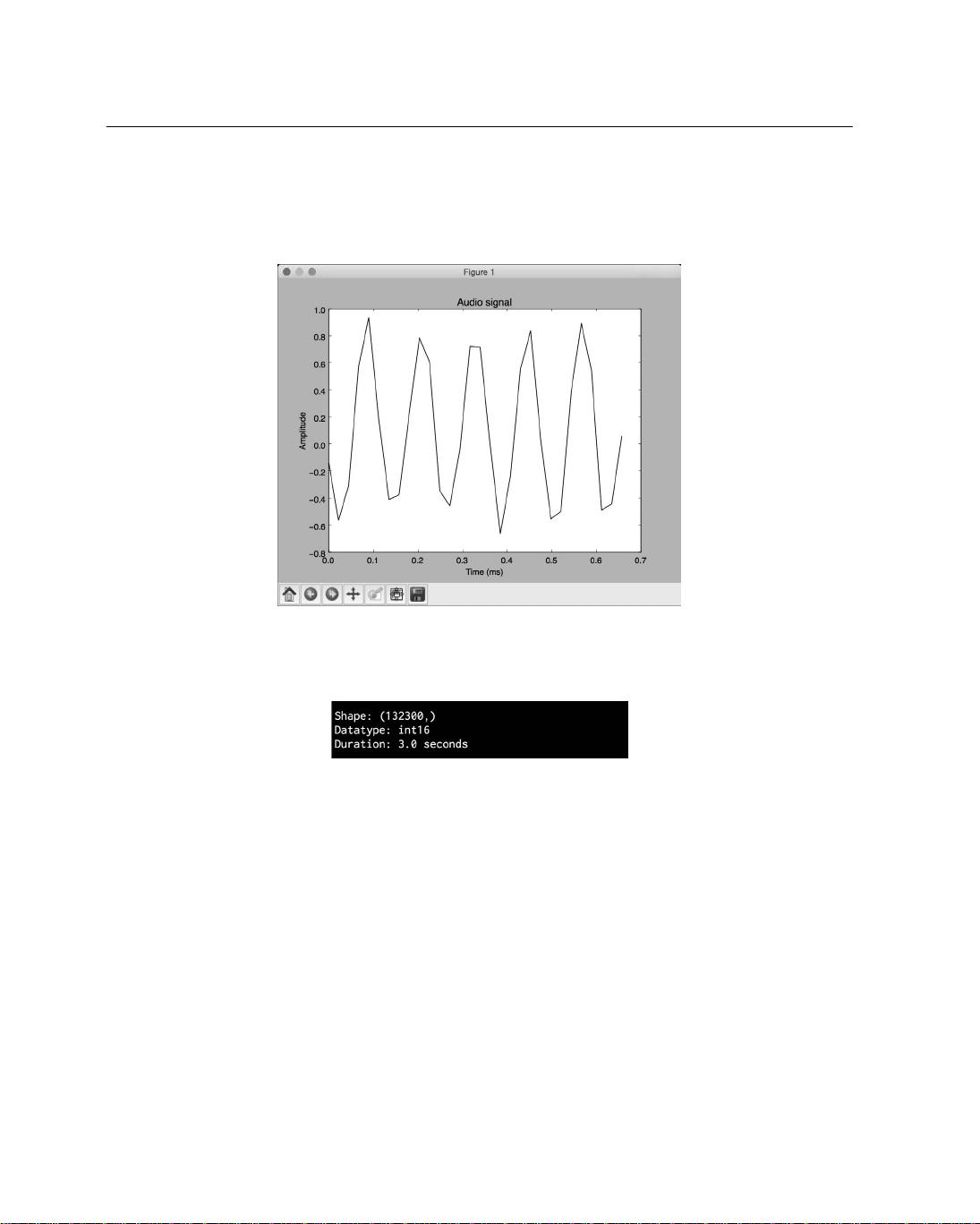
(9) 全部代码已经包含在read_plot.py文件中。运行该代码,可以看到如图7-1所示的信号。
图 7-1
(10) 可以看到终端打印出如图7-2所示的结果。
图 7-2
7.3 将音频信号转换为频域
音频信号是不同频率、幅度和相位的正弦波的复杂混合。正弦波也称作正弦曲线。音频信号
的频率内容中隐藏了很多信息。事实上,一个音频信号的性质由其频率内容决定。世界上的语音
和音乐都是基于这个事实的。在进行接下来的学习之前,你需要了解一些傅里叶变换(Fourier
transforms)的知识,可以在http://www.thefouriertransform.com中找到快速入门介绍。下面来学习
如何将音频信号转换为频域。
详细步骤
(1) 创建一个Python文件,并导入以下程序包:
剩余14页未读,继续阅读
1369 浏览量
564 浏览量
573 浏览量
2024-11-12 上传
309 浏览量
2024-11-08 上传
2024-10-27 上传
2025-01-01 上传
2024-10-27 上传

好知识传播者
- 粉丝: 1685
 我的内容管理
展开
我的内容管理
展开







最新资源
- EhLib 9.4.019 完整源码包支持Delphi 7至XE10.3
- 深度解析Meteor中的DDP实时有线协议
- C#仿制Win7资源管理器TreeView控件与源码发布
- AB152xP实验室测试工具V2.1.4版本发布
- backports.zoneinfo-feedstock:conda-smithy存储库支持Python反向移植
- H5抽奖活动与Java后端实现技术参考
- 掌握JavaScript中的分支测试技巧
- Excel辅助DCM文件标定量查询与核对工具
- Delphi实现TcxDBTreeList与数据集关联的Check功能
- Floodlight 0.9版本源码发布:开源控制器的二次开发指南
- Fastcopy:碎文件快速拷贝神器
- 安全测试报告:ListInfo.SafetyTest分析
- 提升移动网页性能的测试工具MobileWebPerformanceTest
- SpringBoot与XXL-JOB集成实践指南
- NetSurveyor 3.0: 无线网络诊断与数据记录工具
- Node.js基础实践:搭建Hello World HTTP服务器
