社区发现算法:从Web1.0到SocialWeb的演进与应用
需积分: 20 136 浏览量
更新于2024-07-18
收藏 7.96MB PDF 举报
"社区发现算法工作简介"
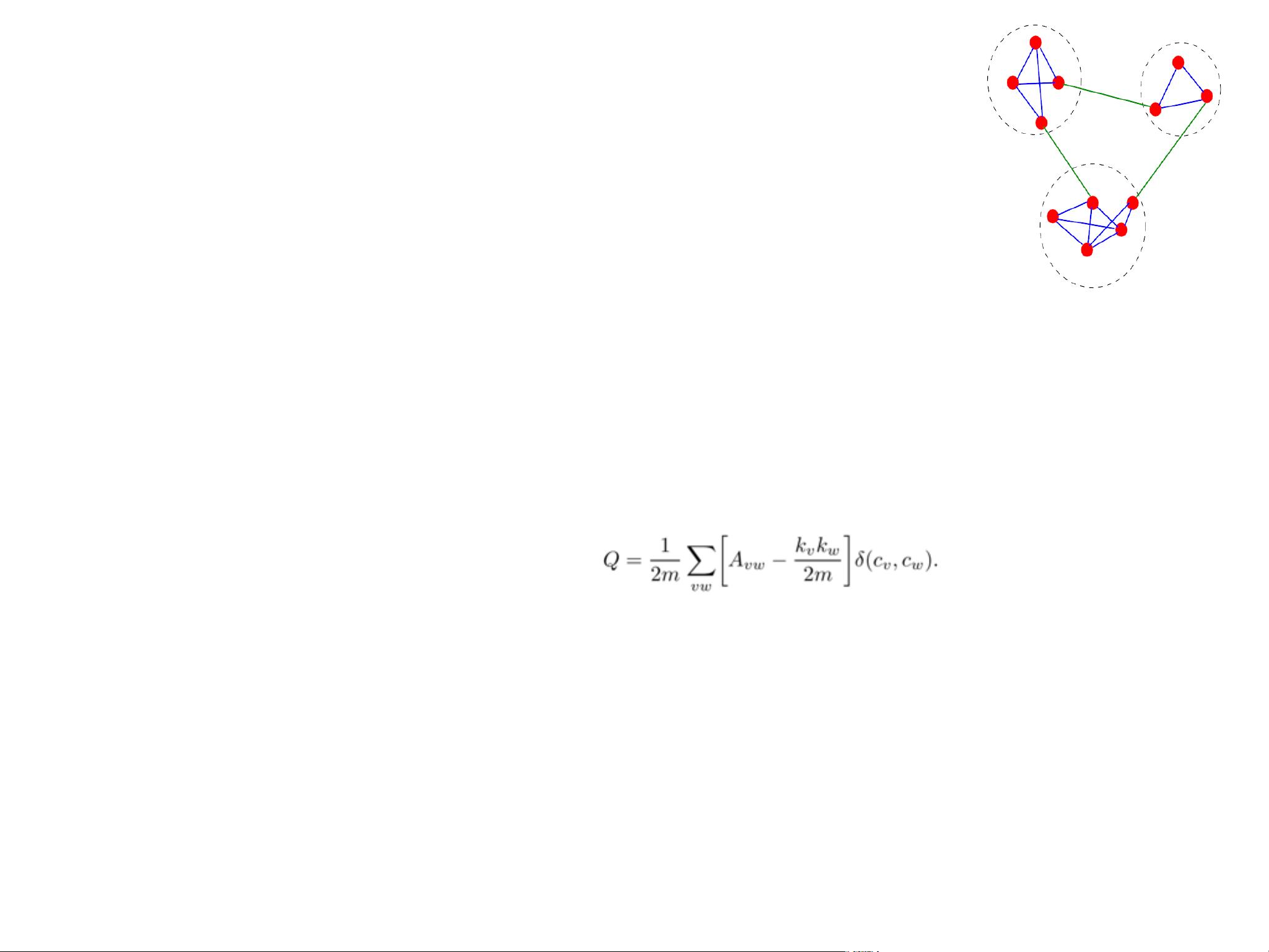
社区发现算法是一种用于识别网络中具有紧密内部联系和相对隔离的子集,即“社区”的方法。这些算法广泛应用于社交网络、信息网络和各种复杂网络的分析中。社区结构是复杂网络的一个普遍特征,通过揭示网络中的社区,我们可以更好地理解和解释网络的组织方式。
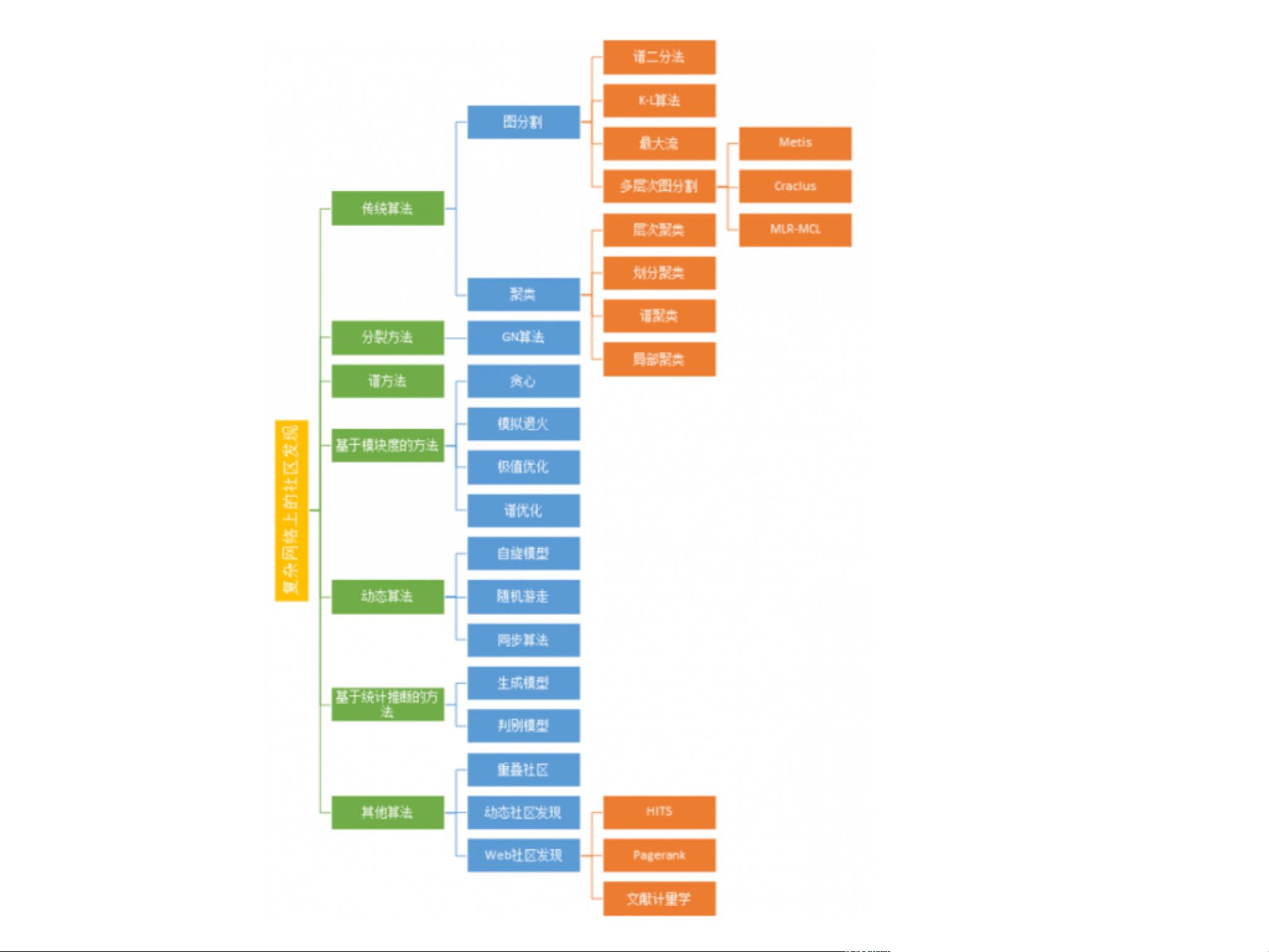
社区发现算法的发展经历了多个阶段,从早期的基于图论的方法到现代的机器学习和深度学习技术。早期的算法主要包括模ularity优化、谱聚类和层次聚类等。随着Web的发展,社区发现也从Web 1.0时代的静态信息处理,发展到Web 2.0的用户生成内容和交互性,再到Web 3.0的语义网,使得算法能够理解网络上的数据和内容含义。
研究社区发现算法具有重要的现实意义。在社交媒体中,准确地发现社区可以帮助进行精准广告投放、商品推荐和朋友推荐,提高用户体验。在异构网络中,如学术网络和商务网络,社区发现可以找到权威作者、营销群体,以及在多类型人际关系中分析朋友圈。此外,社区发现还被应用于小世界网络和无标度网络的研究。
小世界网络是具有短特征路径长度和高集聚系数的网络,如瓦茨-斯特罗加茨模型所示,它揭示了六度分割理论,即大部分人在网络中只需通过5到6个人就能联系到其他人。而在Facebook等现代社交网络中,这一理论已经演变为“四度”分隔。无标度网络则具有幂律分布的度分布,这意味着网络中存在一些高度连接的节点,这些节点在网络中起着关键作用。
社区发现算法的研究涵盖了多种方法,包括基于随机游走、矩阵分解、图神经网络等。这些方法各有优势,适用于不同类型的网络和社区结构。例如,基于概率模型的算法如Louvain方法和Infomap,它们通过迭代优化过程来最大化模块质量,以找到最优社区结构。而图神经网络则结合深度学习技术,通过学习节点的特征来识别社区。
在未来,社区发现算法将进一步发展,结合更先进的机器学习技术和大数据分析,以应对日益复杂和大规模的网络挑战。这不仅将提升社区发现的准确性,还将推动新的应用领域,如网络安全、疾病传播预测和社会行为分析等。

108 浏览量
293 浏览量
160 浏览量
1283 浏览量
7423 浏览量
2077 浏览量
381 浏览量

weixin_42627083
- 粉丝: 0
 我的内容管理
展开
我的内容管理
展开







最新资源
- 支付宝订单监控免签工具:实时监控与信息通知
- 一键永久删除QQ空间说说的绿色软件
- Appleseeds训练营第4周JavaScript练习
- 免费HTML转CHM工具:将网页文档化简成章
- 奇热剧集站SEO优化模板下载
- Python xlrd库:实用指南与Excel文件读取
- Genegraph:通过GraphQL API使用Apache Jena展示RDF基因数据
- CRRedist2008与CRRedist2005压缩包文件对比分析
- SDB交流伺服驱动系统选型指南与性能解析
- Android平台简易PDF阅读器的实现与应用
- Mybatis实现数据库物理分页的插件源码解析
- Docker Swarm实例解析与操作指南
- iOS平台GTMBase64文件的使用及解密
- 实现jQuery自定义右键菜单的代码示例
- PDF处理必备:掌握pdfbox与fontbox jar包
- Java推箱子游戏完整源代码分享
