HashMap演进与JDK11源码解析
185 浏览量
更新于2024-09-01
收藏 441KB PDF 举报
HashMap是Java中常用的一种散列表实现,它提供了高效的键值对存储和查找功能。在JDK 1.8之前,HashMap的底层数据结构由数组和链表组成,这种结构被称为“拉链法”或“开放寻址法”。数组中的每个元素实际上是一个链表的头部,当多个键映射到同一个索引时,这些键值对会在同一个链表中按顺序存储。由于HashMap是非线程安全的,所以在多线程环境下可能会出现数据不一致的情况。
JDK 1.8引入了性能优化,将部分链表转化为红黑树,使得在高冲突情况下查找、插入和删除的效率显著提升。红黑树是一种自平衡的二叉查找树,它的特性使得在平均情况下查找、插入和删除的时间复杂度保持在O(log n)。当链表长度超过一定阈值(通常是8)时,HashMap会将链表转换为红黑树;当树的节点数量减少到一定程度(通常是6)时,又会将红黑树转换回链表。这种优化减少了遍历长链表的时间,提高了整体性能。
HashMap中的主要数据结构有以下两个:
1. Node:这是HashMap的基本存储单元,它实现了Map.Entry接口,包含key的哈希码、key、value以及指向下一个Node的引用。在JDK 1.8之前,Node仅用于链表结构。每个Node都有一个`next`指针,用于连接下一个Node,形成链表。
2. TreeNode:在JDK 1.8及之后版本,当链表达到一定长度时,Node会升级为TreeNode,成为红黑树的一部分。TreeNode不仅包含Node的所有属性,还额外包含了红黑树的结构信息,如父节点、左孩子、右孩子以及前继节点。TreeNode的`red`属性用于维护红黑树的性质,保证其平衡。
HashMap的存储过程大致如下:
- 当插入新的键值对时,首先计算key的哈希值,然后通过哈希函数确定其在数组中的位置。
- 如果该位置为空,新键值对直接存入;如果已有节点,根据JDK版本不同,可能形成链表或触发树化。
- 在链表中,新节点会被添加到已存在节点的末尾。
- 在红黑树中,新节点会被插入到正确的位置,以保持树的平衡。
在遍历HashMap时,有两种方式:
- 遍历数组,访问每个链表或红黑树的头节点,然后沿着链表或树进行遍历。
- 使用迭代器(Iterator),HashMap提供了entrySet()方法,返回一个Set视图,可以按插入顺序或按键值排序进行遍历。
HashMap的设计和实现是基于高效查找和存储的目标,通过动态调整数据结构(链表或红黑树)来平衡空间和时间复杂度,从而在大多数情况下提供优秀的性能。然而,由于非线程安全性,如果在多线程环境中使用,应考虑使用ConcurrentHashMap以保证并发安全。
HashMap 源码分析源码分析
基于jdk11
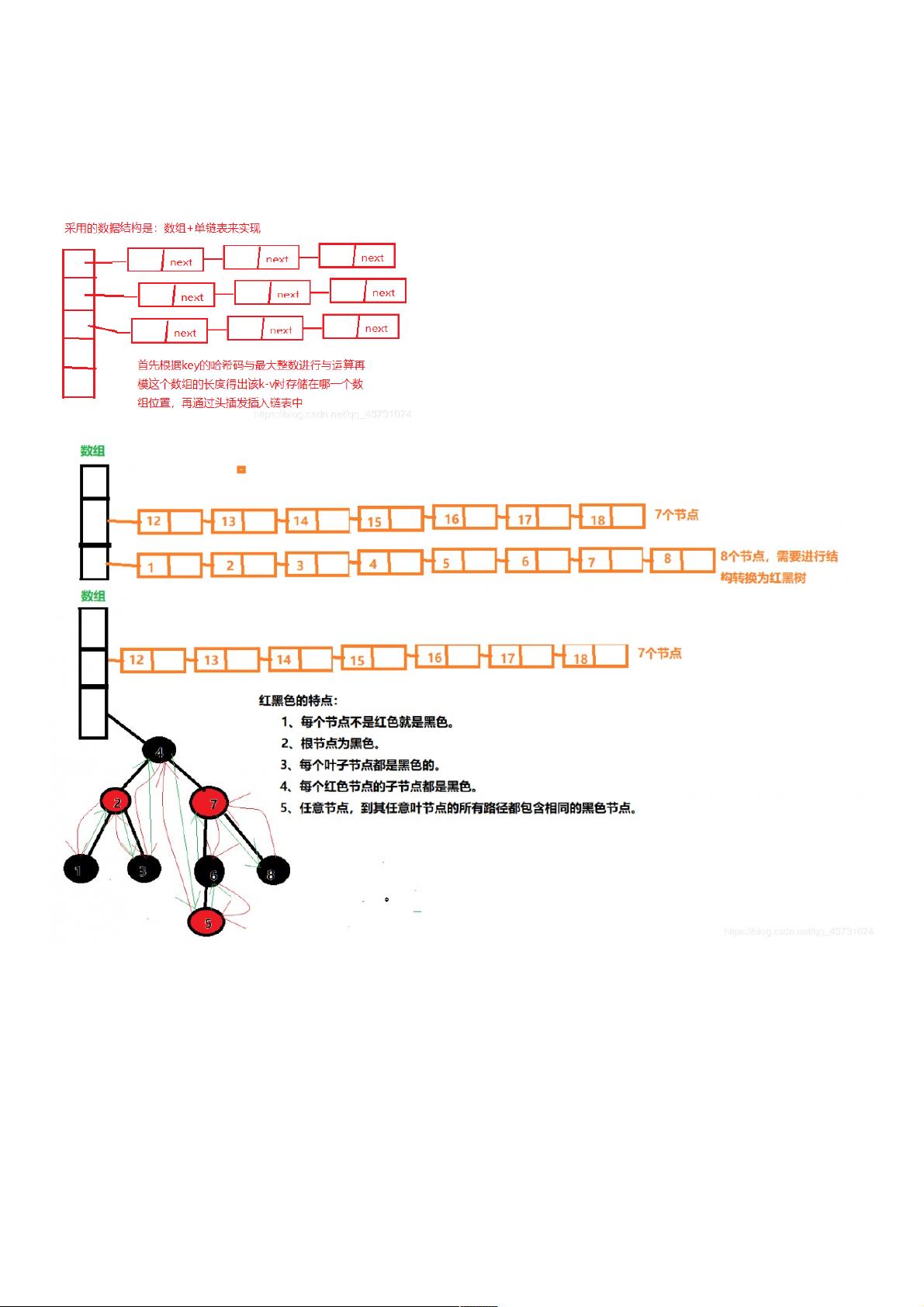
首先,我们了解一下首先,我们了解一下HashMap的底层结构历史,在的底层结构历史,在JDK1.8之前采用的是数组之前采用的是数组+链表的数据结构来存储数据,是不是觉得很熟悉,没错这玩意在链表的数据结构来存储数据,是不是觉得很熟悉,没错这玩意在1.8之前的结构就和之前的结构就和HashTable一样都一样都
是采用数组是采用数组+链表,同样也是通过链地址法链表,同样也是通过链地址法(这里简称拉链法这里简称拉链法)来解决冲突,但是来解决冲突,但是HashMap和和HashTable的区别是一个是线程安全的,一个是非线程安全的。然后知道的区别是一个是线程安全的,一个是非线程安全的。然后知道jdk1.8出来以出来以
后,后,HashMap做性能优化修改,底层数据结构变成了数组做性能优化修改,底层数据结构变成了数组+链表链表+红黑树,性能上也有了很大改变(但还是并发问题,可能这也是为了追求性能而不改的,因为在红黑树,性能上也有了很大改变(但还是并发问题,可能这也是为了追求性能而不改的,因为在JUC包下已经有了包下已经有了
可以支持并发的可以支持并发的HashMap-(ConcurrentHashMap)这个这个Map是支持并发操作的)。是支持并发操作的)。
两种版本的数据结构:
jdk1.8之前:
jdk1.8之后:
了解完上图后是否有疑惑但无所谓,只有看一下HashMap内部的真正数据结构就很容易理解为什么红黑树还有前后继节点
下面是HashMap存储的数据结构:
//这是数组结构,用来存储每个Node及其子类的头接节点的。
transient Node[] table;
//单链表结构
static class Node implements Map.Entry {
//key的哈希码,并非节点Node的哈希码
final int hash;
final K key;
V value;
//后继节点
Node next;
Node(int hash, K key, V value, Node next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
}
//这是红黑树的树结构
static final class TreeNode extends LinkedHashMap.Entry {
TreeNode parent; // 父母节点
TreeNode left;//左孩子
TreeNode right;//右孩子
TreeNode prev; // 该节点的前继节点,然后你发现Node里面有个后继节点,这样一来这个TreeNode既是红黑树结构也是双链表结构。
下载后可阅读完整内容,剩余8页未读,立即下载
点击了解资源详情
点击了解资源详情
点击了解资源详情
2013-03-11 上传
2023-03-30 上传
2020-08-27 上传
2018-03-01 上传
2021-10-26 上传

weixin_38597970
- 粉丝: 4
- 资源: 919
 我的内容管理
展开
我的内容管理
展开







