强化学习在分布式无线网络路由优化中的应用综述
需积分: 14 156 浏览量
更新于2024-07-16
收藏 2.54MB PDF 举报
"这篇PDF文献是关于在分布式无线网络中应用强化学习进行路由优化的综述,涵盖了传统和增强的RL模型在不同类型的无线网络中的应用及其带来的优势。"
在分布式无线网络中,由于节点的移动性、网络拓扑的动态变化等因素,路由优化一直是一个重大的挑战。传统的路由策略往往依赖预定义的路由规则,这些规则可能只适用于特定的网络条件。然而,强化学习(Reinforcement Learning, RL)作为一种机器学习方法,已被证明能够有效地应对这种挑战。
强化学习的基本思想是通过智能体与环境的交互,不断学习并优化其行为策略。在网络路由场景中,每个无线节点都可以视为一个智能体,它能够观察并收集其动态运行环境的信息,然后根据这些信息学习并实时做出高效的路由决策。这一过程涉及到了Q学习、SARSA(State-Action-Reward-State-Action)等经典的强化学习算法,它们允许节点根据接收的奖励信号调整其路由策略,以期望在未来获得更大的累积奖励。
文献中,作者们详细回顾了强化学习在不同类型的分布式无线网络中的应用,包括自组织网络(Ad Hoc Networks)、传感器网络(Sensor Networks)、移动Ad Hoc网络(MANETs)以及vehicular Ad Hoc网络(VANETs)等。对于每种网络类型,都分析了其特有的路由挑战,如节点间的不稳定连接、带宽限制、能量效率需求等,并讨论了强化学习如何帮助解决这些问题。
传统RL模型,如Q学习,主要关注长期奖励最大化,但在实际应用中可能存在收敛速度慢、易受环境变化影响等问题。因此,文献还探讨了一些增强的RL模型,如深度Q网络(Deep Q-Network, DQN)和经验回放缓冲区等技术,这些技术通过引入深度学习来处理高维度状态空间,以及利用经验回放提高学习效率和稳定性,从而在复杂网络环境中实现更优的路由决策。
此外,文章还讨论了强化学习在路由优化中的一些关键问题,如延迟优化、能源效率提升、安全性增强以及网络拥塞控制。通过这些强化学习的应用,无线网络的路由性能得到了显著提升,例如减少数据包丢失、增加吞吐量、延长网络生存时间以及增强网络的自适应性。
这篇综述提供了强化学习在路由优化领域的全面视角,对理解如何利用这种机器学习技术改进分布式无线网络的路由策略具有很高的参考价值。它不仅展示了强化学习的优势,也揭示了未来研究可能面临的挑战和潜在的发展方向。
Application of reinforcement learning 387
Table 1 Characteristics of distributed wireless networks
Wireless ad
hoc networks
Wireless
sensor networks
Cognitive
radio networks
Delay tolerant
networks
Examples of
applications
Vehicular
networks
Physical
environment
monitoring
Extension of
broadband
service to rural
communities
High-speed
vehicular
networks
Multiplayer games Security
surveillance
Emergency and
rescue
operations
Spacecraft
communications
Emergency and
rescue
operations
Health
applications
Emergency and
rescue operations
Main routing
challenge(s)
High mobility Limited energy
and processing
capabilities
Dynamicity of
channel
availability
Lack of end-to-end
routes between
any two nodes at
most of the times
Minimizing
interference to
licensed users
Main advantage(s)
brought about
by RL
Adaptive to
dynamic
topology
Has lower
computational
cost
Adaptive to
dynamic
channel
availability
Adaptive to
dynamic topology
Incurs lower
routing overhead
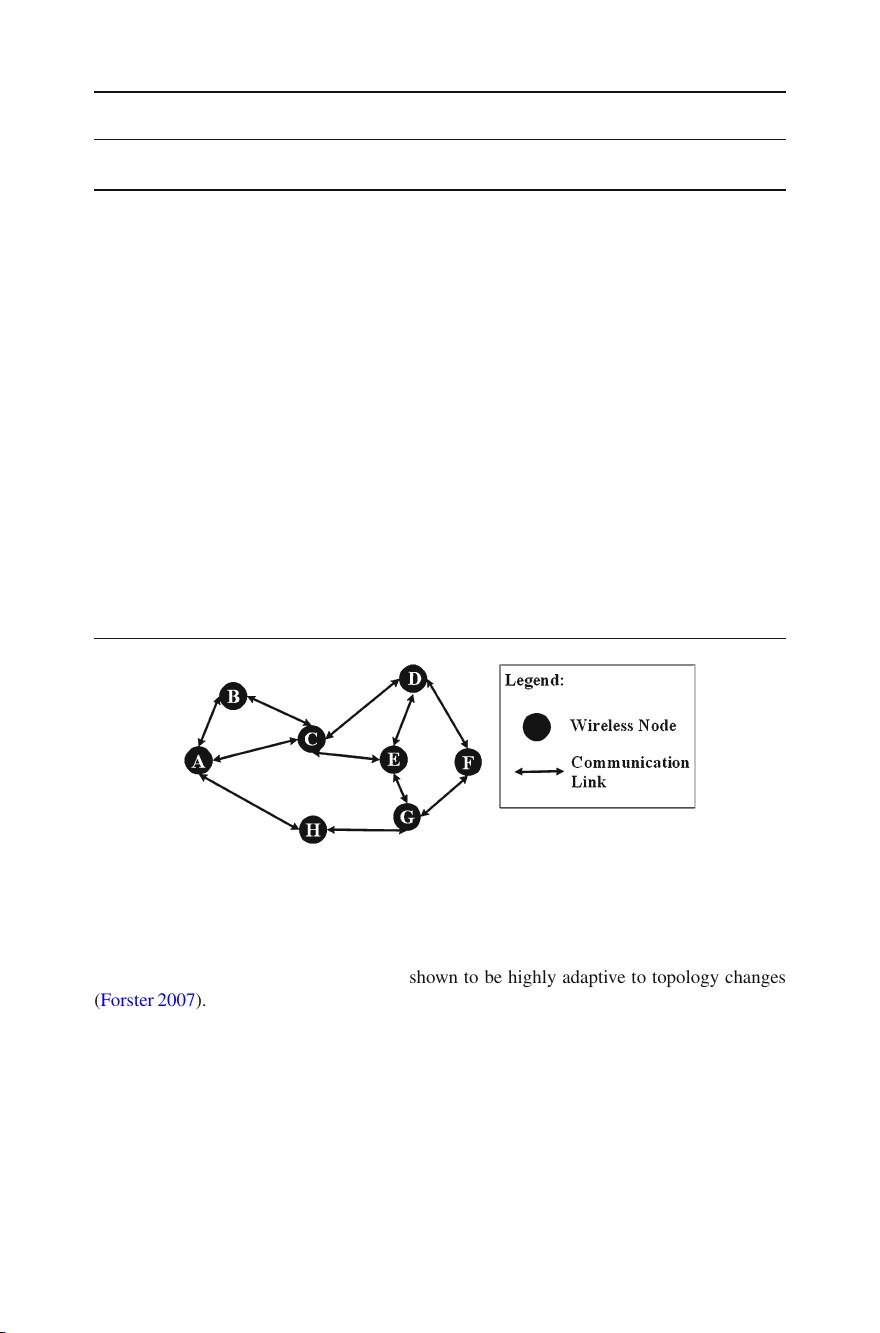
Fig. 2 Wireless ad hoc network scenario
In highly mobile networks, the OLSR constantly updates these routes due to link breakages,
causing high computing cost a nd routing overhead.
RL-based routing schemes have been shown to be highly adaptive to topology changes
(Forster 2007). For example, RL enables a node to observe its neighbor nodes’ mobility char-
acteristics, and to learn how to improve the end-to-end delay and throughput performances of
routes. Subsequently, the node selects a next-hop node that can satisfy the Quality of Service
(QoS) requirements imposed on the route.
3.1.2 Wireless sensor networks
Wireless Sensor Networks (WSNs) are comprised of sensor nodes with sensing, computing,
storing, and short-range wireless communication capabilities commonly used for monitoring
the operating environment. WSNs share similar characteristics with wireless ad hoc networks
123

剩余35页未读,继续阅读
2018-08-13 上传
2018-09-26 上传
2020-01-20 上传
2019-09-25 上传
2019-07-24 上传
2023-08-28 上传
2019-07-20 上传
2020-12-08 上传

Swaggy_xu
- 粉丝: 8
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- 前端面试必问:真实项目经验大揭秘
- 永磁同步电机二阶自抗扰神经网络控制技术与实践
- 基于HAL库的LoRa通讯与SHT30温湿度测量项目
- avaWeb-mast推荐系统开发实战指南
- 慧鱼SolidWorks零件模型库:设计与创新的强大工具
- MATLAB实现稀疏傅里叶变换(SFFT)代码及测试
- ChatGPT联网模式亮相,体验智能压缩技术.zip
- 掌握进程保护的HOOK API技术
- 基于.Net的日用品网站开发:设计、实现与分析
- MyBatis-Spring 1.3.2版本下载指南
- 开源全能媒体播放器:小戴媒体播放器2 5.1-3
- 华为eNSP参考文档:DHCP与VRP操作指南
- SpringMyBatis实现疫苗接种预约系统
- VHDL实现倒车雷达系统源码免费提供
- 掌握软件测评师考试要点:历年真题解析
- 轻松下载微信视频号内容的新工具介绍
