Model-free控制详解:采样优化策略求解未知/大规模MDP问题
下载需积分: 0 | PDF格式 | 1.83MB |
更新于2024-08-05
| 28 浏览量 | 举报
在强化学习的高级阶段,"Model-free控制1"探讨了如何通过算法解决实际问题中的控制问题。控制问题的核心在于从给定的马尔可夫决策过程(MDP)中找到最优策略和价值函数,这与预测问题有所不同,后者仅关注基于策略的价值函数估算。
Model-free控制方法主要针对两类实际挑战:当MDP模型未知但可以通过环境采样获取数据时,或者模型已知但因问题规模过大无法高效计算时。这类控制方法无需提前知道MDP的具体形式,而是通过在线学习不断迭代优化策略。
在控制策略上,区分了同轨策略(On-policy)和异轨策略(Off-policy)。On-policy学习中,智能体使用当前策略进行采样,然后基于这些经验优化策略,以期望达到最优。这种方法依赖于现有策略,因此被称为同轨。
相比之下,Off-policy学习允许智能体使用与当前策略不同的策略进行采样,如使用专家策略。这种策略改进不会完全基于现有的策略,从而带来更广泛的学习范围,但可能导致策略和价值函数的更新不直接对应。
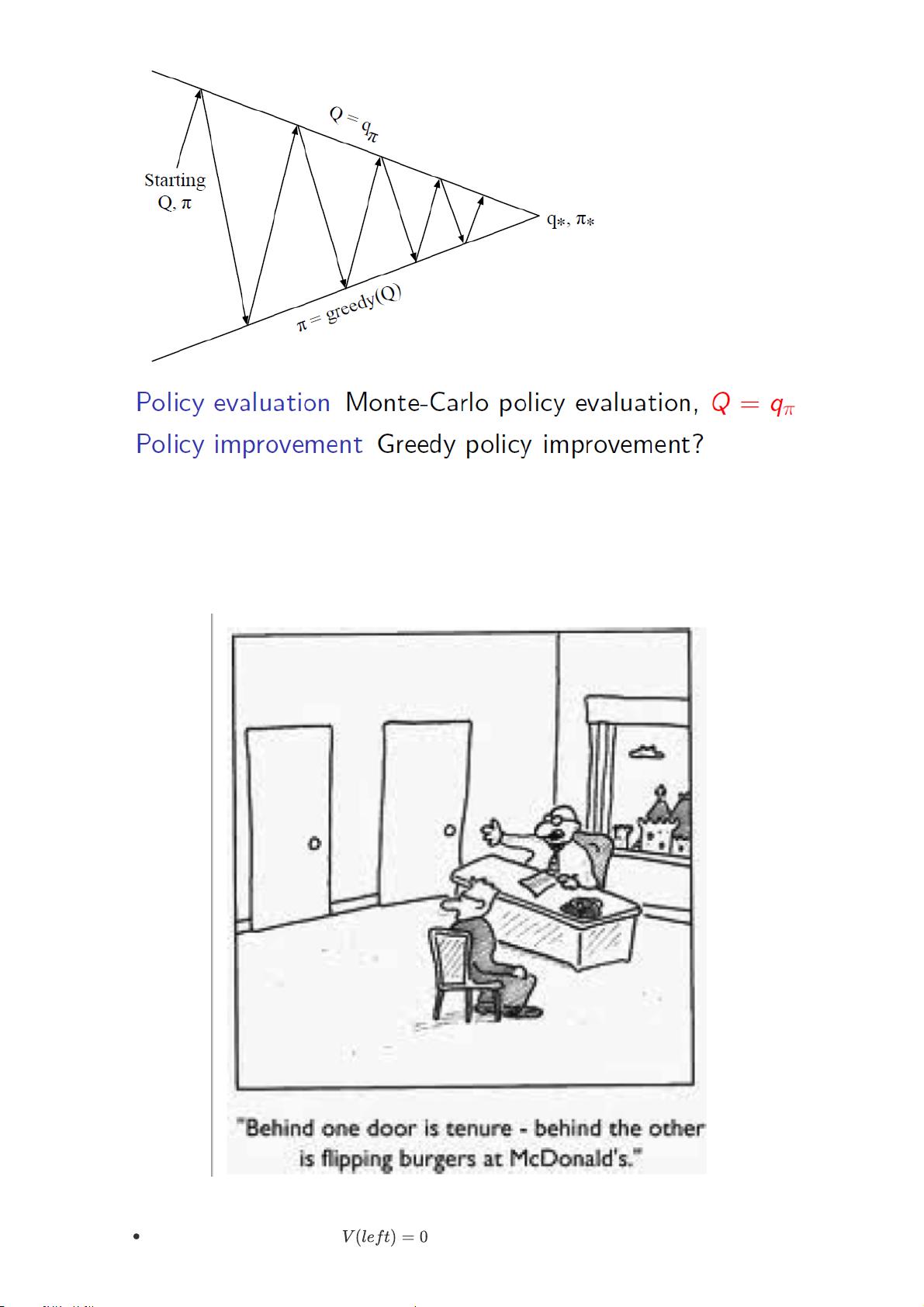
同轨蒙特卡洛控制(On-policy Monte Carlo Control)是GPI(广义策略迭代)的一个实例,这是一种通用框架,它允许策略评估和策略改进这两个过程协同工作,即使它们的执行粒度不同。GPI假设评估和改进过程稳定后,策略和价值函数将达到稳定状态,即最优状态。
总结来说,Model-free控制的关键在于通过不断试错和优化策略,利用采样数据,无论是在已知或未知MDP模型的场景下,目标都是找到适应环境的最佳行为策略。这两种策略学习方式提供了丰富的工具箱,使得强化学习能够在实际应用中解决复杂的决策问题。
剩余13页未读,继续阅读
相关推荐



高工-老罗
- 粉丝: 27
 我的内容管理
展开
我的内容管理
展开







最新资源
- 初学者指南:使用ASP.NET构建简单网站
- Ukelonn Web应用:简化周薪记录与支付流程
- Java常用算法解析与应用
- Oracle 11g & MySQL 5.1 JDBC驱动压缩包下载
- DELPHI窗体属性实例源码教程,新手入门快速掌握
- 图书销售系统毕业设计与ASP.NET SQL Server开发报告
- SWT表格管理类实现表头排序与隔行变色
- Sqlcipher.exe:轻松解锁微信EnMicroMsg.db加密数据库
- Zabbix与Nginx旧版本源码包及依赖管理
- 《CTL协议中文版》下载分享:项目清晰,完全免费
- Django开发的在线交易模拟器PyTrade
- 蓝牙功能实现:搜索、配对、连接及文件传输代码解析
- 2012年版QQ密码记录工具详细使用说明
- Discuz! v2.5 幻雪插件版社区论坛网站开源项目详解
- 南邮数据结构实验源码全解
- Linux环境下安装Oracle必用pdksh-5.2.14工具指南
