DETR:Transformer在端到端目标检测中的应用
需积分: 3 85 浏览量
更新于2024-06-27
收藏 9.33MB PDF 举报
"这篇论文《End-to-End Object Detection with Transformers》是Facebook AI团队提出的一种新的对象检测方法,它将目标检测视为直接的集合预测问题,摒弃了传统的手工设计组件,如非极大值抑制和锚框生成。这种方法的核心是DEtection TRansformer (DETR),它采用基于集合的全局损失和Transformer编码器-解码器架构,通过学习到的对象查询来推理物体之间的关系和全局图像上下文,从而并行地直接输出最终预测结果。DETR模型在概念上简洁,不需要专门的库,与许多现代检测器相比,其准确性和运行时性能相当,并且与高度优化的Faster R-CNN基准进行了比较。"
在深度学习领域,目标检测是一个关键任务,用于识别和定位图像中的特定对象。传统的目标检测算法,如Faster R-CNN,通常包括多个步骤:特征提取、区域提议、分类和回归等,这些步骤往往包含许多手工设计的组件,如锚框(Anchor Boxes)用于生成可能的物体框,以及非极大值抑制(Non-Maximum Suppression, NMS)用于去除重叠的检测框。
论文《End-to-End Object Detection with Transformers》引入了一种创新的方法,即DETR,它通过Transformer架构实现端到端的目标检测。Transformer最早在自然语言处理中被提出,因其强大的序列建模能力而受到广泛关注。DETR借鉴了Transformer的思想,但将其应用于视觉任务,特别是目标检测。
DETR的核心在于它的Transformer编码器-解码器结构。编码器负责从输入图像中提取特征,这通常由预训练的卷积神经网络(如ResNet)完成。解码器则接收这些特征,并与一组固定数量的学习对象查询(Object Queries)交互。这些查询可以看作是待检测物体的潜在表示,解码器通过多头自注意力机制和交叉注意力机制来理解图像中的物体关系和全局上下文。
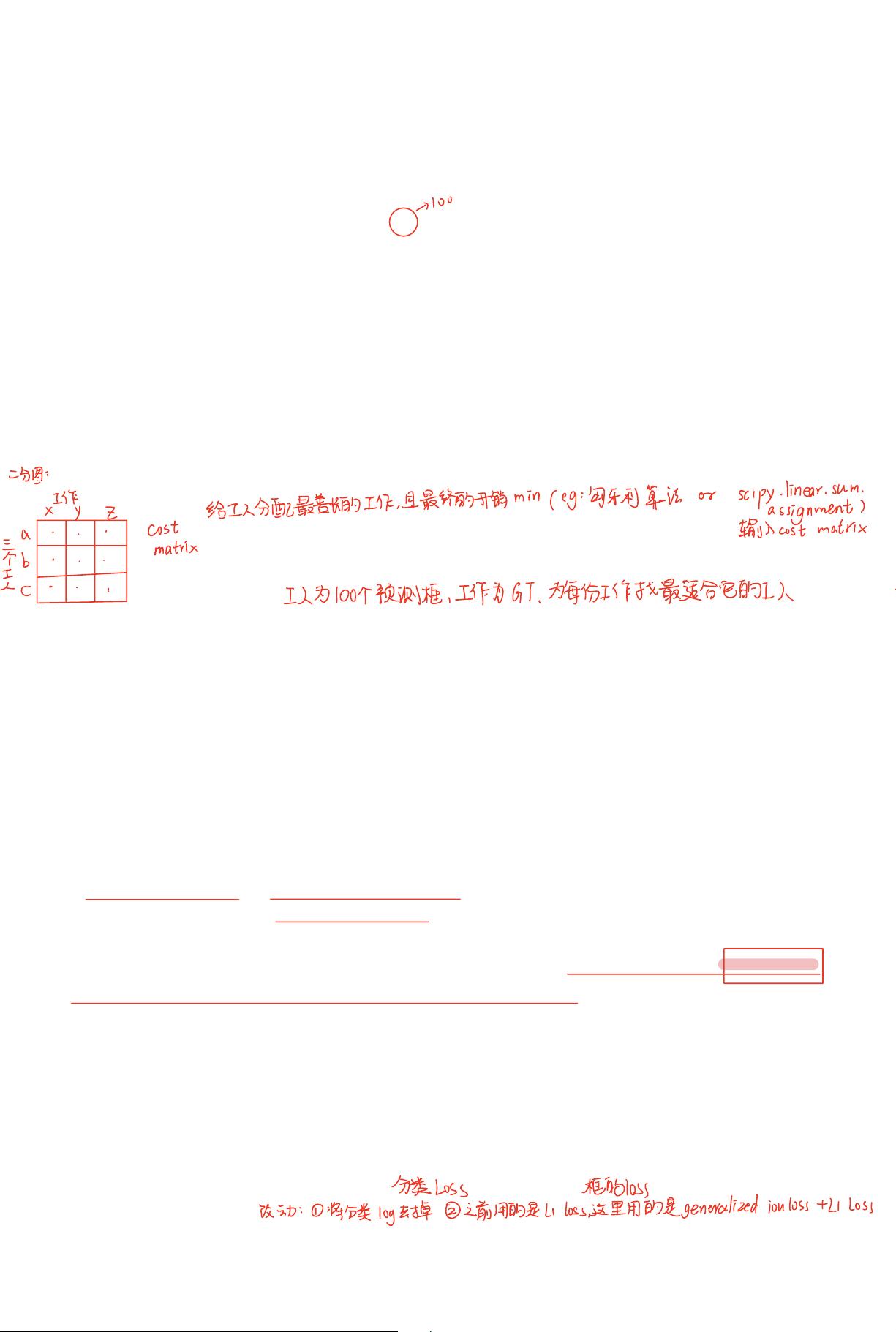
论文中的“基于集合的全局损失”是另一个关键点,它通过 bipartite matching(二分匹配)强制唯一预测。这意味着DETR能够直接预测出不重复的物体框和类别,而无需NMS这样的后处理步骤。这种简化不仅减少了计算复杂性,也使得模型更加透明和易于理解。
DETR的另一个优点是其模块化设计。它不需要专门的库或者特定的优化技巧,这使得它更容易被其他研究者复现和扩展。尽管DETR在性能上与Faster R-CNN相当,但其端到端的特性可能为未来的目标检测算法提供新的研究方向,尤其是在简化模型结构和提高效率方面。
《End-to-End Object Detection with Transformers》为深度学习目标检测提供了一个全新的视角,将Transformer的强大学习能力应用到视觉任务中,挑战了传统检测框架的设计,有望推动目标检测领域的进一步发展。
End-to-End Object Detection with Transformers 5
boxes; (2) an architecture that predicts (in a single pass) a set of objects and
models their relation. We describe our archite ct u re in detai l in Figure 2.
3.1 Object detection set prediction l oss
DETR infers a fixed-size set of N predictions, in a sin gl e pass through the
decoder, where N is set to be significantly larger than the typical number of
objects in an image. One of t he main difficulties of training is to score predicted
objects (cl as s, position, size) w it h respect to the ground truth. O ur loss produces
an optimal bipartite matching between predicted and ground t r ut h objects, and
then optimize object-specific (bounding box) losses.
Let us denote by y the ground truth set of objects, and ˆy = {ˆy
i
}
N
i=1
the
set of N predictions. Assuming N is l ar ger than the number of objects in the
image, we consider y also as a set of size N padded with ? (no object). To find
a b i par t i t e matching between these two sets we search for a permutation of N
elements 2 S
N
with the lowest cost:
ˆ = arg min
2S
N
N
X
i
L
match
(y
i
, ˆy
(i)
), (1)
where L
match
(y
i
, ˆy
(i)
) is a pair-wise matching cost between ground truth y
i
and
a pr ed i ct i on with index (i ) . This optimal assignment is computed efficiently
with the Hungarian algorithm, following prior work (e.g.[43]).
The matching cost takes into account both the class prediction and the sim-
ilarity of pr ed i ct e d and gr oun d truth boxes. Each element i of the ground truth
set can be seen as a y
i
=(c
i
,b
i
)wherec
i
is the target class label (which
may be ?) and b
i
2 [0, 1]
4
is a vector t hat defines ground tr ut h box cen-
ter coordinates and its height and width relative to the image size. For the
prediction with index (i) we define probability of class c
i
as ˆp
(i)
(c
i
) and
the predicted box as
ˆ
b
(i)
. With these notations we define L
match
(y
i
, ˆy
(i)
) as
1
{c
i
6=?}
ˆp
(i)
(c
i
)+1
{c
i
6=?}
L
box
(b
i
,
ˆ
b
(i)
).
This pro ce du re of finding matching plays the same role as the heuristic assign-
ment rules used to match proposal [37] or anchors [22] to ground truth objects
in moder n detectors. The main di↵erence is that we need to find one-to-one
matching for direct set predi ct i on wit h out dup li c ate s.
The second step is to compu t e the loss function, the Hungarian loss for all
pairs matched in the p re vi ou s step. We define the loss similarly to the losses of
common object d et ec t ors , i.e. a linear combination of a negative log-likelihood
for class prediction and a box loss defined later:
L
Hungarian
(y, ˆy)=
N
X
i=1
h
log ˆp
ˆ(i)
(c
i
)+1
{c
i
6=?}
L
box
(b
i
,
ˆ
b
ˆ
(i))
i
, (2)
where ˆ is the optimal assignment computed in the first step (1). In practice, we
down-weight the log-probability term when c
i
= ? by a factor 10 to account for

剩余25页未读,继续阅读
2023-11-25 上传
2023-10-24 上传
2020-06-14 上传
2023-03-17 上传
2022-04-25 上传
2022-01-03 上传
2024-06-17 上传
2023-11-16 上传
2023-10-31 上传

Mrwei_418
- 粉丝: 165
- 资源: 4
 我的内容管理
展开
我的内容管理
展开







最新资源
- IEEE 14总线系统Simulink模型开发指南与案例研究
- STLinkV2.J16.S4固件更新与应用指南
- Java并发处理的实用示例分析
- Linux下简化部署与日志查看的Shell脚本工具
- Maven增量编译技术详解及应用示例
- MyEclipse 2021.5.24a最新版本发布
- Indore探索前端代码库使用指南与开发环境搭建
- 电子技术基础数字部分PPT课件第六版康华光
- MySQL 8.0.25版本可视化安装包详细介绍
- 易语言实现主流搜索引擎快速集成
- 使用asyncio-sse包装器实现服务器事件推送简易指南
- Java高级开发工程师面试要点总结
- R语言项目ClearningData-Proj1的数据处理
- VFP成本费用计算系统源码及论文全面解析
- Qt5与C++打造书籍管理系统教程
- React 应用入门:开发、测试及生产部署教程
