Google大数据分布式系统设计:经验与优化策略
在"Google构建大规模分布式系统的设计、教训和建议"这篇论文中,作者Jeff Dean作为Google Fellow,分享了Google在设计和运行大规模分布式系统方面的经验和洞察。随着计算技术向小型设备和大型数据中心转移,Google的数据中心如位于俄勒冈州达勒斯的设施,展示了其基础设施的核心组件,包括服务器、CPU、内存(DRAM)、硬盘以及网络架构。
服务器是基础单元,每个服务器可能包含40到80台机器,每台配备有高性能的16GB DRAM,具有低延迟的100ns访问速度和20GB/s的带宽,以及2TB的硬盘,虽然速度稍慢但能满足长期存储需求。为了提高效率,数据在不同层级的存储层次结构中被组织,从本地内存(L1)到远程存储(L2),通过Rack Switch进行连接,确保数据快速访问。
在更高层次的架构中,一个服务器所在的机架(Rack)通常有80台服务器,每台都配备了1TB的快速内存和160TB的硬盘,带宽达到100MB/s。这样的设计考虑了内存和存储性能的平衡,以便在处理大量数据时实现高效和可靠性。
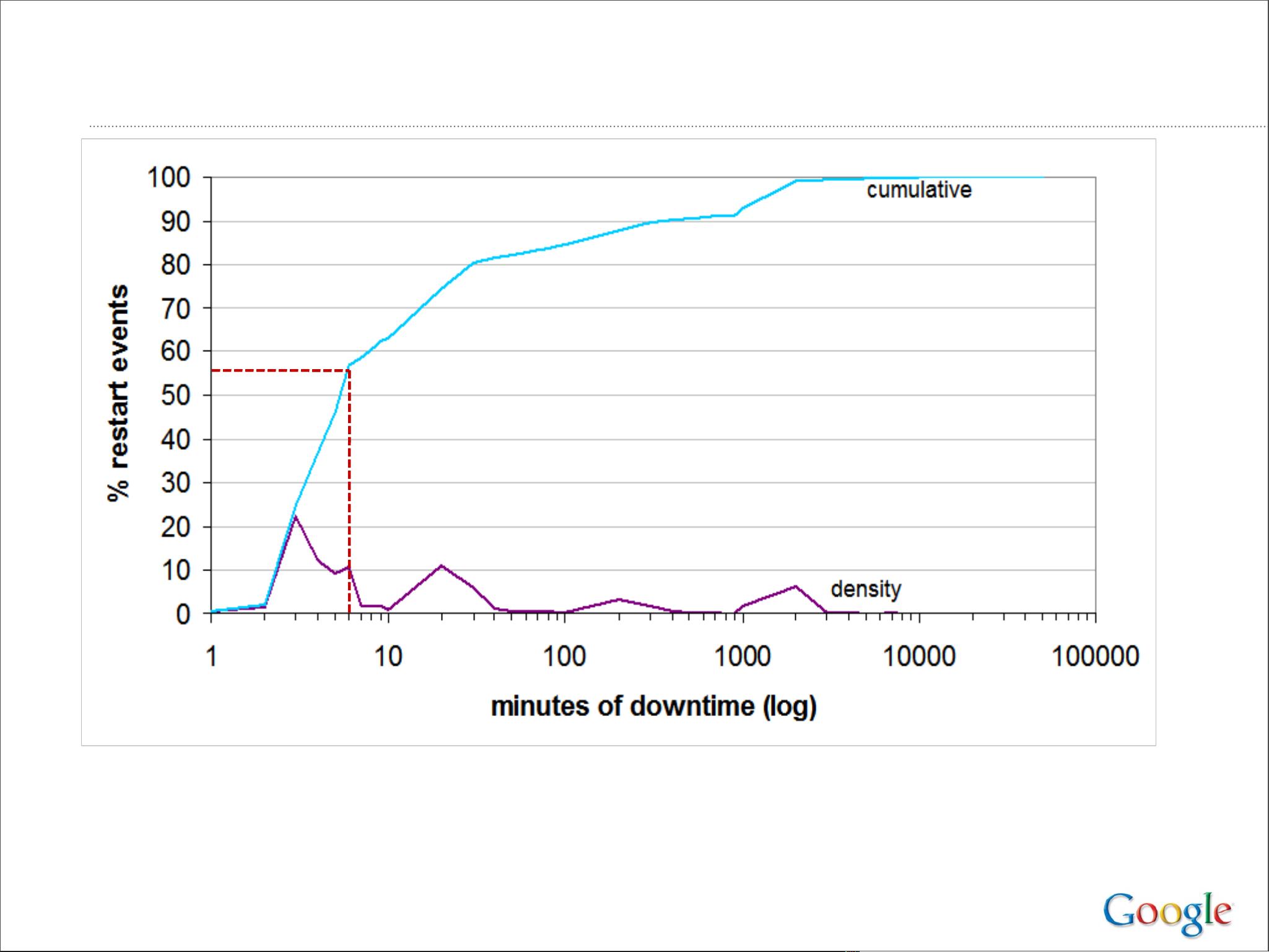
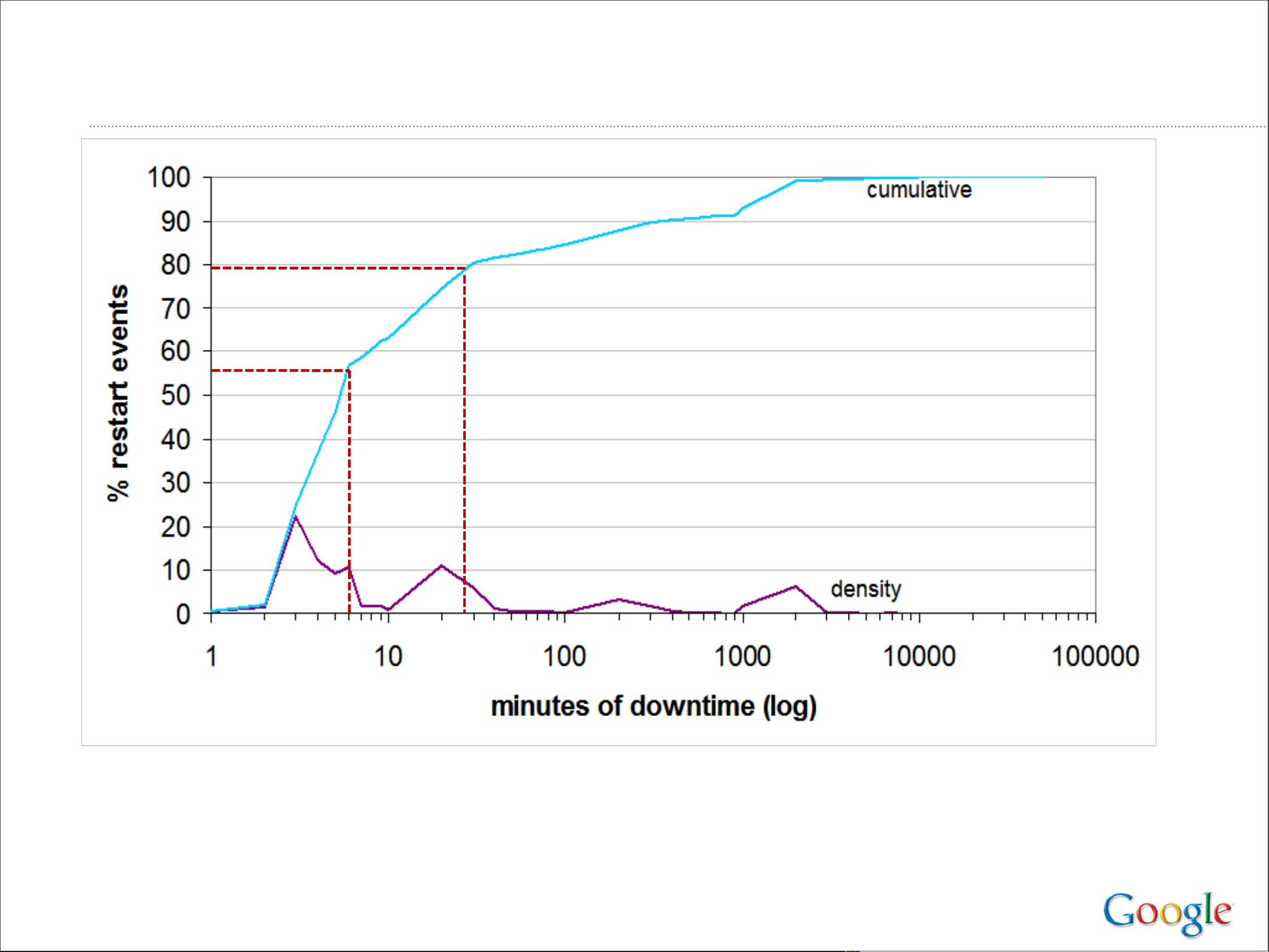
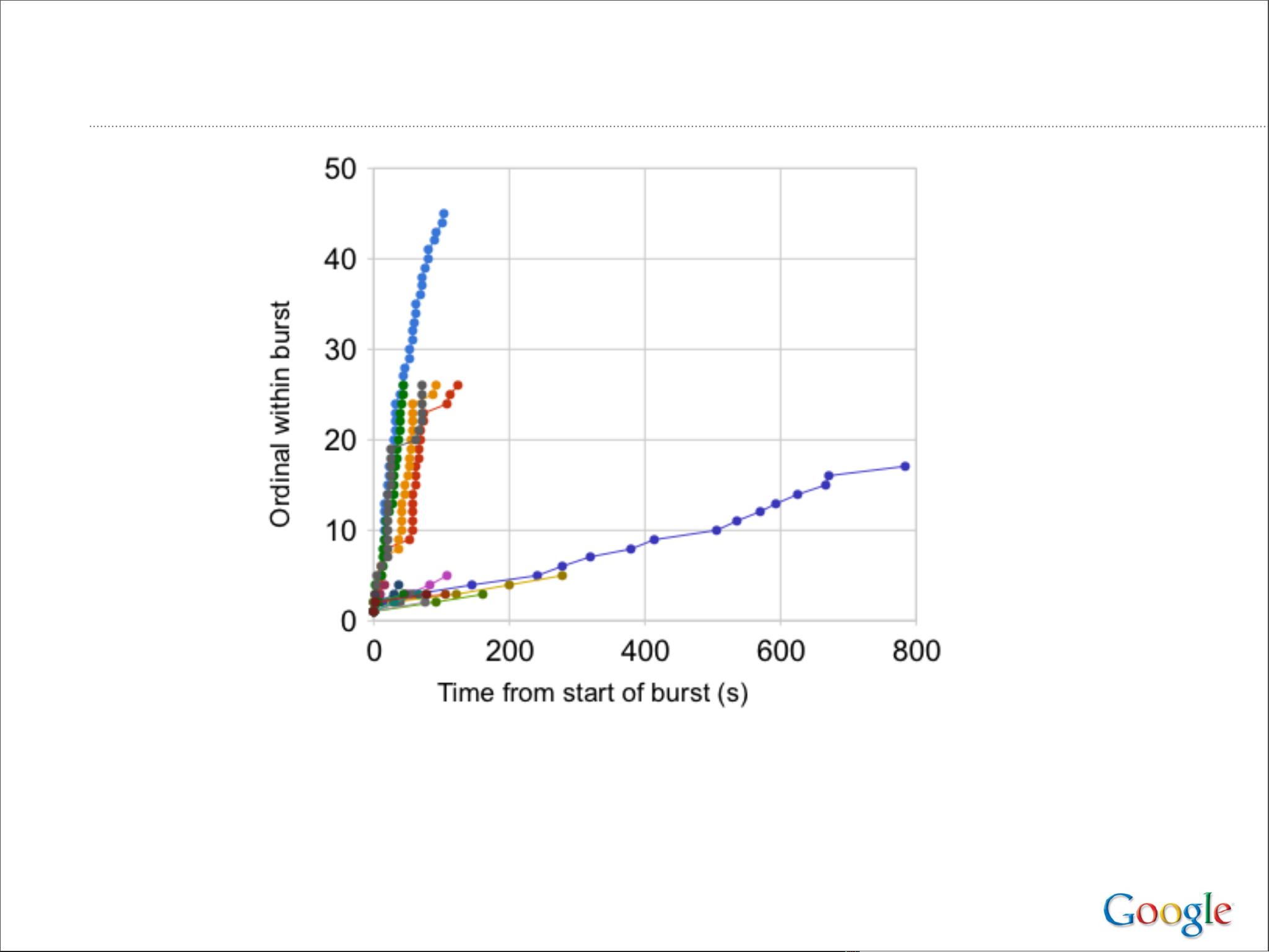
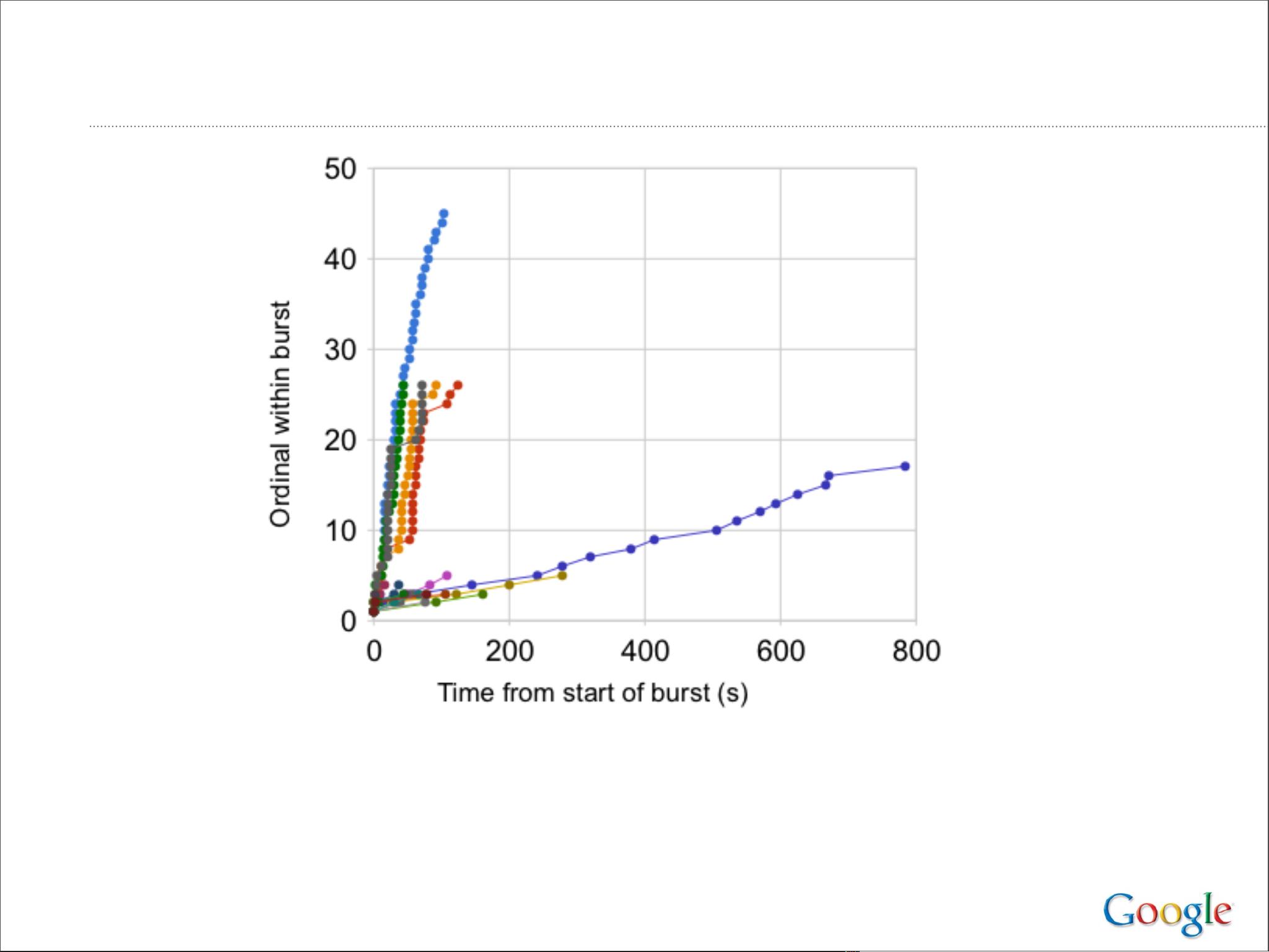
论文深入探讨了这些设计背后的策略,包括如何处理数据复制、故障恢复、负载均衡以及数据一致性等问题。Google的经验教训强调了对系统可用性、可扩展性和容错性的重视,同时也提出了如下几点关键建议:
1. **模块化和标准化**:通过标准化硬件和软件组件,简化系统的复杂性,降低维护成本。
2. **分层存储**:利用不同层级的存储满足不同性能需求,提高整体性能。
3. **分布式缓存**:利用本地内存加速访问,减少对远程存储的依赖。
4. **自动扩展**:灵活的架构设计,允许根据负载自动调整资源,避免过载。
5. **容错机制**:通过冗余和备份系统设计,确保即使在部分组件故障时,服务仍能继续运行。
6. **监控和日志**:持续监控系统健康状况,收集数据用于性能优化和问题排查。
总结来说,这篇文章深入剖析了Google在构建大规模分布式系统中的实战经验,包括硬件配置、架构设计原则以及在实际运营中面临并解决的问题,为其他企业和开发者提供了宝贵的参考和学习材料。
2021-08-10 上传
2018-08-22 上传
2023-10-30 上传
2023-04-24 上传
2023-03-30 上传
2023-05-17 上传
2024-01-21 上传
2023-06-11 上传

孟子E章
- 粉丝: 1w+
- 资源: 9
 我的内容管理
展开
我的内容管理
展开







最新资源
- Postman安装与功能详解:适用于API测试与HTTP请求
- Dart打造简易Web服务器教程:simple-server-dart
- FFmpeg 4.4 快速搭建与环境变量配置教程
- 牛顿井在围棋中的应用:利用牛顿多项式求根技术
- SpringBoot结合MySQL实现MQTT消息持久化教程
- C语言实现水仙花数输出方法详解
- Avatar_Utils库1.0.10版本发布,Python开发者必备工具
- Python爬虫实现漫画榜单数据处理与可视化分析
- 解压缩教材程序文件的正确方法
- 快速搭建Spring Boot Web项目实战指南
- Avatar Utils 1.8.1 工具包的安装与使用指南
- GatewayWorker扩展包压缩文件的下载与使用指南
- 实现饮食目标的开源Visual Basic编码程序
- 打造个性化O'RLY动物封面生成器
- Avatar_Utils库打包文件安装与使用指南
- Python端口扫描工具的设计与实现要点解析
