NAS-BENCH-201:神经架构搜索的可重复性与扩展性研究
需积分: 21 74 浏览量
更新于2024-07-09
收藏 3.32MB PDF 举报
"NAS-BENCH-201是计算机视觉领域的一个开源论文,它扩展了可重复的神经架构搜索(Neural Architecture Search, NAS)的研究范围。该研究由Xuanyi Dong和Yi Yang共同发表在ICLR 2020会议上。NAS-BENCH-201的目标是解决NAS领域的可比性问题,通过提供一个固定搜索空间和统一的基准,以促进对最新NAS算法性能的比较。"
正文:
神经架构搜索(NAS)是近年来在计算机视觉等多个领域取得重大突破的技术。它通过自动化的方式寻找最优的神经网络结构,从而减少了人工设计的负担。然而,随着各种不同的NAS算法的出现,它们在不同的搜索空间下工作,并使用不同的训练设置(如超参数、数据增强、正则化),这导致了比较不同NAS算法性能时出现的可比性问题。
为了应对这个问题,NAS-BENCH-101被提出,它是第一个解决此类问题的基准,提供了标准化的环境以评估NAS算法。NAS-BENCH-201作为其扩展,进一步增强了这个概念,引入了新的搜索空间、多数据集的结果以及更全面的诊断信息。这使得几乎所有的最新NAS算法都可以在一个统一的平台上进行比较,促进了NAS领域的进步和深入理解。
NAS-BENCH-201的设计灵感来源于最受欢迎的细胞结构,这种结构被广泛应用于许多成功的NAS算法中。它的搜索空间是固定的,这意味着所有算法都将在相同的基础上进行搜索,消除了因搜索空间差异带来的不公。此外,它还提供了在多个数据集上的性能指标,如CIFAR-10、CIFAR-100和ImageNet-16-120,这允许研究人员在更广泛的背景下评估架构的泛化能力。
除了基本的性能比较,NAS-BENCH-201还包含了一些诊断信息,例如训练曲线、模型复杂度和计算效率等,这些信息有助于深入分析每个架构的优缺点,从而推动NAS算法的改进和发展。通过对这些数据的分析,研究者可以更好地理解哪些设计选择对性能有显著影响,以及如何优化搜索过程以获得更好的结果。
NAS-BENCH-201是推动计算机视觉领域NAS研究的重要工具,它为算法开发人员和研究者提供了一个公正、全面的平台,以评估和比较他们的方法,同时鼓励了更多的创新和发现。随着NAS技术的不断发展,这样的基准将继续发挥关键作用,确保研究的透明度和可重复性,从而推动整个领域向前发展。
Published as a conference paper at ICLR 2020
CIFAR-10: It is a standard image classification dataset and consists of 60K 32×32 colour images
in 10 classes. The original training set contains 50K images, with 5K images per class. The original
test set contains 10K images, with 1K images per class. Due to the need of validation set, we split
all 50K training images in CIFAR-10 into two groups. Each group contains 25K images with 10
classes. We regard the first group as the new training set and the second group as the validation set.
CIFAR-100: This dataset is just like CIFAR-10. It has the same images as CIFAR-10 but categorizes
each image into 100 fine-grained classes. The original training set on CIFAR-100 has 50K images,
and the original test set has 10K images. We randomly split the original test set into two group of
equal size — 5K images per group. One group is regarded as the validation set, and another one is
regarded as the new test set.
ImageNet-16-120: We build ImageNet-16-120 from the down-sampled variant of ImageNet
(ImageNet16×16). As indicated in Chrabaszcz et al. (2017), down-sampling images in ImageNet
can largely reduce the computation costs for optimal hyper-parameters of some classical models
while maintaining similar searching results. Chrabaszcz et al. (2017) down-sampled the original
ImageNet to 16×16 pixels to form ImageNet16×16, from which we select all images with label
∈ [1, 120] to construct ImageNet-16-120. In sum, ImageNet-16-120 contains 151.7K training im-
ages, 3K validation images, and 3K test images with 120 classes.
By default, in this paper, “the training set”, “the validation set”, “the test set” indicate the new
training, validation, and test sets, respectively.
2.3 ARCHITECTURE PERFORMANCE
Training Architectures. In order to unify the performance of every architecture, we give the per-
formance of every architecture in our search space. In our NAS-Bench-201, we follow previous
Table 1: The training hyper-parameter set H
†
.
optimizer SGD initial LR 0.1
Nesterov X ending LR 0
momentum 0.9 LR schedule cosine
weight decay 0.0005 epoch 200
batch size 256 initial channel 16
V 4 N 5
random flip p=0.5 random crop X
normalization X
literature to set up the hyper-parameters and train-
ing strategies (Zoph et al., 2018; Loshchilov &
Hutter, 2017; He et al., 2016). We train each ar-
chitecture with the same strategy, which is shown
in Table 1. For simplification, we denote all hyper-
parameters for training a model as a set H, and we
use H
†
to denote the values of hyper-parameter that
we use. Specifically, we train each architecture via
Nesterov momentum SGD, using the cross-entropy
loss for 200 epochs in total. We set the weight de-
cay as 0.0005 and decay the learning rate from 0.1 to 0 with a cosine annealing (Loshchilov &
Hutter, 2017). We use the same H
†
on different datasets, except for the data augmentation which is
slightly different due to the image resolution. On CIFAR, we use the random flip with probability
of 0.5, the random crop 32×32 patch with 4 pixels padding on each border, and the normalization
over RGB channels. On ImageNet-16-120, we use a similar strategy but random crop 16×16 patch
with 2 pixels padding on each border. Apart from using H
†
for all datasets, we also use a different
hyper-parameter set H
‡
for CIFAR-10. It is similar to H
†
but its total number of training epochs
is 12. In this way, we could provide bandit-based algorithms (Falkner et al., 2018; Li et al., 2018)
more options for the usage of short training budget (see more details in appendix).
Metrics. We train each architecture with different random seeds on different datasets. We evaluate
each architecture A after every training epoch. NAS-Bench-201 provides the training, validation,
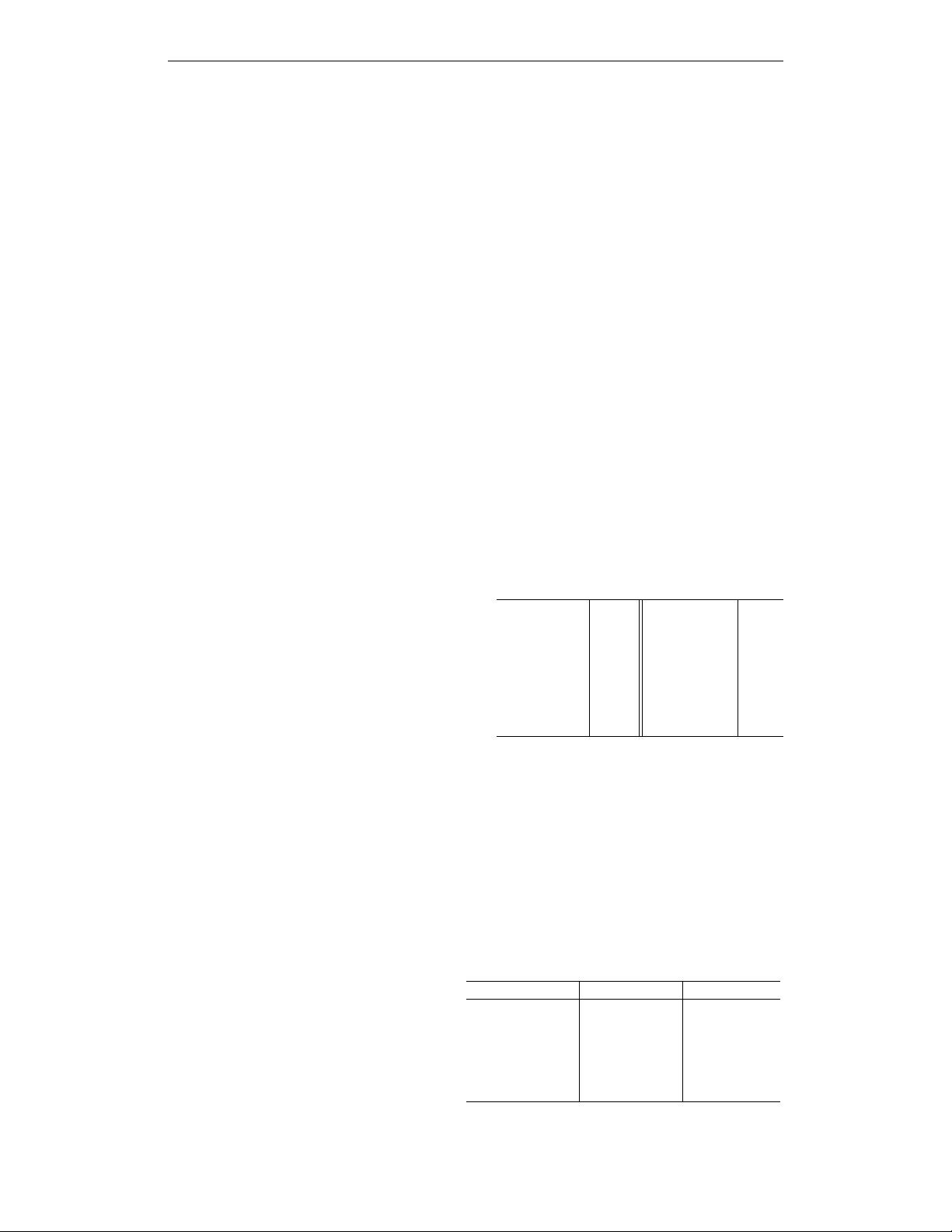
Table 2: NAS-Bench-201 provides the following
metrics with H
†
. ‘Acc.’ means accuracy.
Dataset Train Loss/Acc. Eval Loss/Acc.
CIFAR-10 train set valid set
CIFAR-10 train+valid set test set
CIFAR-100 train set valid set
CIFAR-100 train set test set
ImageNet-16-120 train set valid set
ImageNet-16-120 train set test set
and test loss as well as accuracy. We show the
supported metrics on different datasets in Ta-
ble 2. Users can easily use our API to query
the results of each trial of A, which has neg-
ligible computational costs. In this way, re-
searchers could significantly speed up their
searching algorithm on these datasets and fo-
cus solely on the essence of NAS.
We list the training/test loss/accuracies over
different split sets on four datasets in Table 2. On CIFAR-10, we train the model on the training set
and evaluate it on the validation set. We also train the model on the training and validation set and
4
剩余15页未读,继续阅读
2021-05-10 上传
2021-03-28 上传
2021-06-11 上传
2021-09-29 上传
2021-07-01 上传
2024-02-07 上传
2021-02-21 上传
2021-02-16 上传

潜夙
- 粉丝: 0
- 资源: 40
 我的内容管理
展开
我的内容管理
展开







最新资源
- Aspose资源包:转PDF无水印学习工具
- Go语言控制台输入输出操作教程
- 红外遥控报警器原理及应用详解下载
- 控制卷筒纸侧面位置的先进装置技术解析
- 易语言加解密例程源码详解与实践
- SpringMVC客户管理系统:Hibernate与Bootstrap集成实践
- 深入理解JavaScript Set与WeakSet的使用
- 深入解析接收存储及发送装置的广播技术方法
- zyString模块1.0源码公开-易语言编程利器
- Android记分板UI设计:SimpleScoreboard的简洁与高效
- 量子网格列设置存储组件:开源解决方案
- 全面技术源码合集:CcVita Php Check v1.1
- 中军创易语言抢购软件:付款功能解析
- Python手动实现图像滤波教程
- MATLAB源代码实现基于DFT的量子传输分析
- 开源程序Hukoch.exe:简化食谱管理与导入功能
