深度Q学习网络(DQN)详解:强化学习的高效解决方案
需积分: 10 42 浏览量
更新于2024-08-26
收藏 642KB PDF 举报
深度Q学习网络综述
深度Q学习网络(DQN, Deep Q-learning Network)是强化学习领域的一项重要进展,它解决了经典Q-learning在处理高维状态和动作空间时面临的计算复杂性和存储挑战。Q-learning是一种基于离线策略的学习算法,通过构建和更新Q值表来指导智能体在环境中选择最优动作。然而,随着状态和动作空间的增长,Q-learning的计算负担迅速增加,传统的表格存储方式难以应对。
DQN引入了深度神经网络来替代Q值表,将Q值的计算转变为非线性函数估计。这种方法的优势在于,神经网络能够自动学习复杂的特征表示,减少了手动特征工程的需求。在DQN中,智能体通过与环境的交互,不断调整神经网络的权重,从而优化Q值估计,并逐步找到最佳策略。通过经验回放机制,DQN可以利用之前的学习样本,避免了过拟合问题,并提高了学习效率。
强化学习的核心在于智能体如何通过与环境的互动,根据即时的奖励(如图1.1所示)以及未来累积奖励(由公式(1.1)定义)来优化其行为策略。智能体的目标是最大化长期累积奖励,这需要在不确定性和随机性的环境中进行探索和学习。通过使用期望作为随机过程的平均描述,强化学习算法如DQN能够在无法预知每个状态所有后续奖励的情况下,通过不断迭代优化策略,实现长期的最优决策。
总结来说,DQN的关键点包括:
1. 将Q-learning与深度学习结合,利用神经网络进行非线性函数逼近,减少对大量存储空间的需求。
2. 引入经验回放,稳定训练过程并提高学习效率。
3. 通过探索-利用策略,平衡当前奖励与长期累积奖励的关系。
4. 面对随机过程,采用期望值作为优化目标的数学工具。
DQN在游戏控制、机器人操作和自动化决策等领域取得了显著的成功,是现代强化学习研究中的基石之一。理解并掌握DQN的原理和技术,对于深入探究和应用强化学习至关重要。
N
sV
N
][]10000[]1000[]100[
)(
321
0
其中 N 为回合次数。值
得一提的是回合大多数应用于存在终止状态的任务中,因为一旦达到终止状态智
能体会回到初始位置,无法继续探索环境,这样试错一次也无法正确的衡量每一
个状态的价值,因此需要多次‘试错’。每一回合相当于一次从初始状态到终止
状态的试错过程,当回合次数足够多时智能体可以“遍历”所有的状态达到终止
状态。回合次数越多,计算的状态值函数越精确,但具体的回合次数依据实际任
务确定,不能设定“过大”的次数否则会导致计算量巨大,存储空间不够。
状态值函数除了式(1.2)外可以转化迭代形式:
SssVrasrspsa
sSRrasrspsa
sSRRE
sSREsV
a rs
a rs k
tkt
k
k
tkt
k
t
k
tkt
k
,)'(),|,'()|(
'|),|,'()|(
|
|)(
,'
,' 0
12
0
21
0
1
(1.3)
其中
)|( sa
为随机性策略,
),|,'( asrsp
为状态转移概率,即在状态 s 采取动作 a
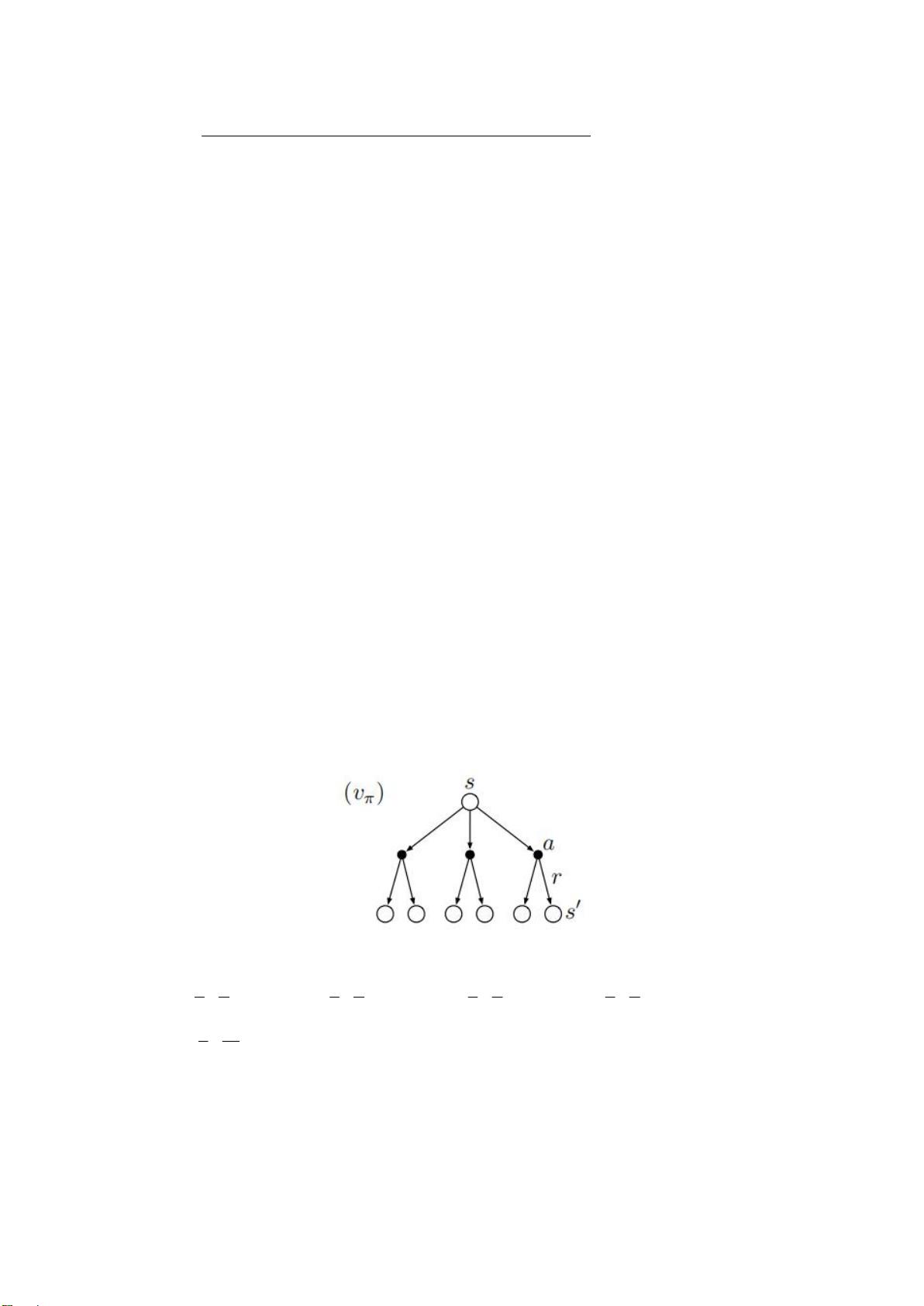
转移到下一状态 s’概率。图 1.3 展示了状态值函数的迭代计算过程,其中
说明公式。的数值是任取的,仅为),|,'(),|( asrspsa
图 1.3 状态值函数树形图
)]([
10
7
3
1
)]([
4
3
3
1
)]([
4
1
3
1
)]([
2
1
3
1
)]([
2
1
3
1
)(
'
6
'
4
'
3
'
2
'
1
'
6
'
4
'
3
'
2
'
1
sVr
sVrsVrsVrsVrsV
s
ssss
在状态值函数中,智能体采取的是随机策略
)|( sa
表示智能体在状态 s 所能
采取的动作的概率,且
1)|(
sa
,例如石头剪刀布游戏中选取石头的几率为
剩余11页未读,继续阅读
2020-06-20 上传
2021-08-12 上传
2021-06-11 上传
2019-11-21 上传
2023-08-25 上传
2023-11-03 上传
2020-09-01 上传
2024-09-27 上传
2021-08-12 上传

oldxacorn
- 粉丝: 1
- 资源: 2
 我的内容管理
展开
我的内容管理
展开







最新资源
- 新代数控API接口实现CNC数据采集技术解析
- Java版Window任务管理器的设计与实现
- 响应式网页模板及前端源码合集:HTML、CSS、JS与H5
- 可爱贪吃蛇动画特效的Canvas实现教程
- 微信小程序婚礼邀请函教程
- SOCR UCLA WebGis修改:整合世界银行数据
- BUPT计网课程设计:实现具有中继转发功能的DNS服务器
- C# Winform记事本工具开发教程与功能介绍
- 移动端自适应H5网页模板与前端源码包
- Logadm日志管理工具:创建与删除日志条目的详细指南
- 双日记微信小程序开源项目-百度地图集成
- ThreeJS天空盒素材集锦 35+ 优质效果
- 百度地图Java源码深度解析:GoogleDapper中文翻译与应用
- Linux系统调查工具:BashScripts脚本集合
- Kubernetes v1.20 完整二进制安装指南与脚本
- 百度地图开发java源码-KSYMediaPlayerKit_Android库更新与使用说明
