Spark实验:SparkSQL,SparkStreaming与JDBC连接MySQL
需积分: 0 124 浏览量
更新于2024-06-30
收藏 2.26MB DOCX 举报
"本实验是关于SparkSQL、SparkStreaming的实践操作,旨在让学习者掌握RDD编程、SparkSQL与MySQL数据库的交互以及SparkStreaming通过Kafka处理实时数据的基本技能。实验在预配置的Hadoop、Spark、Scala、JDBC、MySQL、Kafka环境中进行,涉及数据去重、数据库读写和流处理等核心概念。"
Spark是大数据处理领域的重要工具,其提供了高效、灵活的数据处理框架。在本实验中,学习者将深入理解以下几个关键知识点:
1. **Spark RDD(弹性分布式数据集)**:RDD是Spark的基础数据结构,它是不可变、分区的记录集合。实验中的数据去重任务就基于RDD进行,通过转换和行动操作,实现对两个输入文件的数据合并并去除重复项。
2. **Scala编程**:作为Spark的主要编程语言,Scala提供了强大的函数式编程特性,使得Spark程序简洁且高效。实验中要求使用Scala编写Spark独立应用程序,这将加深对Scala特性和Spark API的理解。
3. **SparkSQL**:SparkSQL是Spark用于结构化数据处理的模块,它可以与Hive兼容,支持SQL查询。在实验的第二部分,学习者需要在Spark中通过JDBC连接MySQL数据库,这涉及到数据的读取和写入操作,如`DataFrame`的创建、查询和保存。
4. **Spark与数据库的交互**:SparkSQL通过JDBC接口可以与多种关系型数据库进行交互,实验中要求安装MySQL并配置JDBC连接,这对于数据集成和分析至关重要。
5. **SparkStreaming**:SparkStreaming是Spark处理实时数据流的组件,它基于微批处理。实验要求利用Kafka作为数据源,编写SparkStreaming程序。Kafka是一个高吞吐量的分布式消息系统,常用于构建实时数据管道。
6. **Kafka配置**:Kafka是实时数据流处理的关键组件,它提供发布/订阅模式的消息传递。了解如何配置Kafka,以及如何在SparkStreaming中使用Kafka数据源,是实现流处理应用的基础。
实验环境包括了多台CentOS服务器、特定版本的Hadoop、Spark、JDK、Scala、IDEA、MySQL和Kafka,这些组件的选择和版本匹配是成功运行实验的前提。在实验步骤中,除了编写和运行程序,还需要提供运行截图和代码,以验证实验结果。
这个实验覆盖了Spark的核心功能,包括批处理、SQL查询和流处理,是学习和掌握大数据处理技术的重要实践环节。通过这个实验,学习者将能够更好地理解和应用Spark在实际场景中的功能。
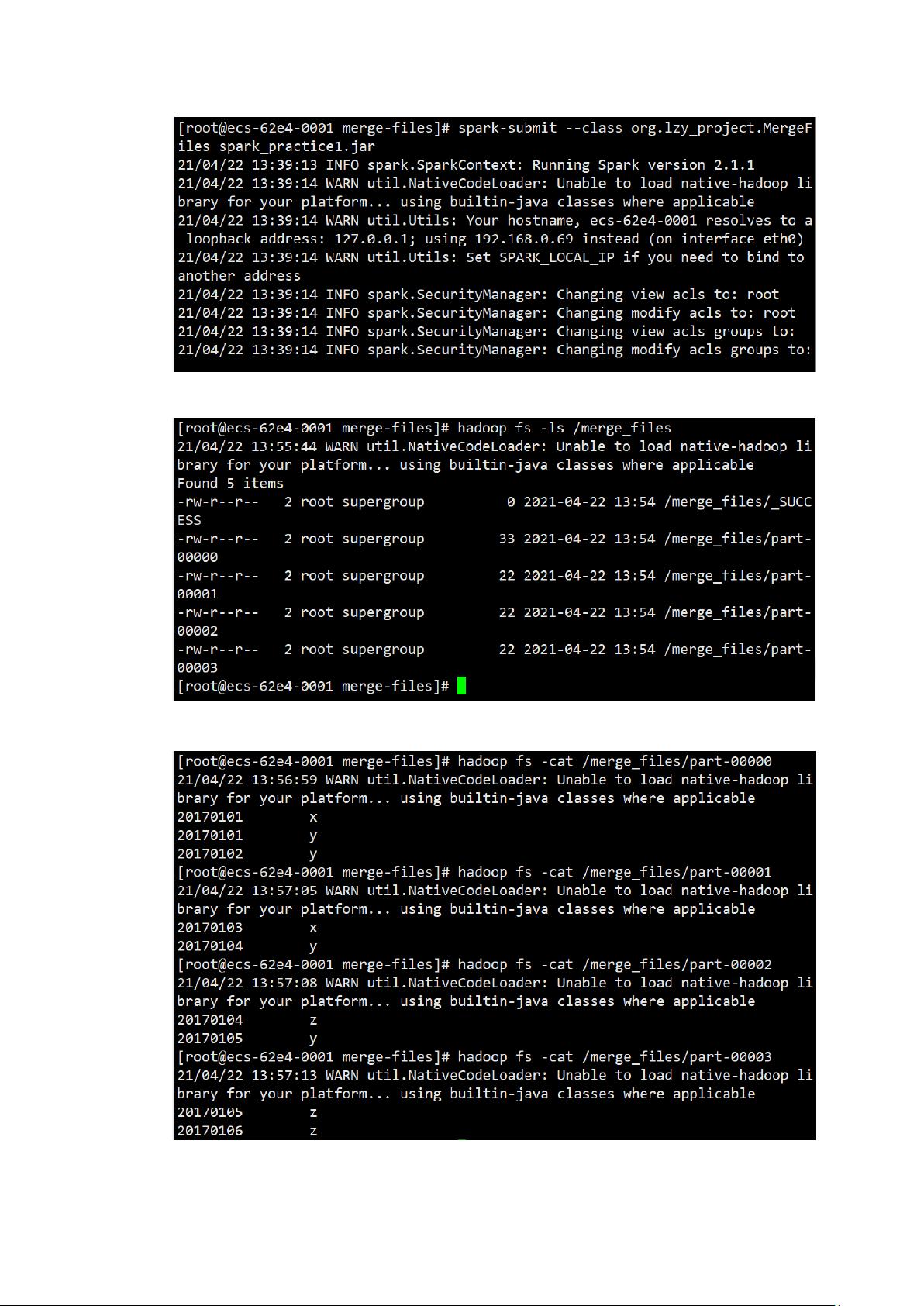
运行完成后,用 hadoop fs -ls /输出文件夹命令查看 hdfs 中的输出结果。
用 cat 命令分别查看输出文件中的内容。
可以看到两个文件被成功合并。
剩余15页未读,继续阅读
2022-08-08 上传
2012-12-10 上传
点击了解资源详情
2015-06-30 上传
2021-09-27 上传
2021-09-21 上传
2011-06-08 上传

无声远望
- 粉丝: 1127
- 资源: 298
 我的内容管理
展开
我的内容管理
展开







最新资源
- Java毕业设计项目:校园二手交易网站开发指南
- Blaseball Plus插件开发与构建教程
- Deno Express:模仿Node.js Express的Deno Web服务器解决方案
- coc-snippets: 强化coc.nvim代码片段体验
- Java面向对象编程语言特性解析与学生信息管理系统开发
- 掌握Java实现硬盘链接技术:LinkDisks深度解析
- 基于Springboot和Vue的Java网盘系统开发
- jMonkeyEngine3 SDK:Netbeans集成的3D应用开发利器
- Python家庭作业指南与实践技巧
- Java企业级Web项目实践指南
- Eureka注册中心与Go客户端使用指南
- TsinghuaNet客户端:跨平台校园网联网解决方案
- 掌握lazycsv:C++中高效解析CSV文件的单头库
- FSDAF遥感影像时空融合python实现教程
- Envato Markets分析工具扩展:监控销售与评论
- Kotlin实现NumPy绑定:提升数组数据处理性能
