Python网络爬虫设计:获取网上数据高效利用的方法
73 浏览量
更新于2024-01-15
收藏 3.14MB DOC 举报
近年来,随着网络应用的不断扩展和深入,如何高效地获取在线数据成为了许多公司和个人的追求。在大数据时代,掌握更多的数据意味着更高的利益,而网络爬虫成为了最常用的一种获取网络数据的手段。网络爬虫,即Web Spider,通过获取网页内容和链接地址的方式,实现对网站数据的抓取。Python作为一种高级程序设计语言,以其解释型、面向对象、带有动态语义等特点,在实现网络爬虫的过程中表现出了重大优势。
Python的优势不仅在于其易读易写的特性,还在于其丰富的库和模块。借助Python的强大库如Requests和BeautifulSoup等,可以方便地发起HTTP请求并且解析HTML文档。这意味着,在Python的生态系统下,网络爬虫的开发变得更加高效和简洁。在设计网络爬虫时,开发者们将从Python中受益良多。
在整个网络爬虫的设计中,有几个关键的步骤需要考虑。首先是确定抓取目标,也就是要爬取的网站和数据。然后需要构建爬取规则,即确定如何去发起爬取请求以及如何解析爬取到的数据。接下来是编写爬虫程序,这是依托Python的库和模块来实现的。同时,还需要注意爬取过程中的一些问题,例如网站的反爬虫机制等。最后,也需要对爬取到的数据进行存储和管理,这同样可以借助Python的相关库和技术来实现。
Python所提供的便捷性和灵活性,使得网络爬虫的设计变得更加高效和容易。其优秀的库和模块为网络爬虫的开发提供了强有力的支持,使得程序员们能够专注于爬虫系统的设计和开发,而不必为底层的HTTP请求和HTML解析等细节费心。因此,可以说基于Python的网络爬虫设计是非常有优势的。
总的来说,Python作为一种高级程序设计语言,以其易读易写的特性和丰富的库和模块,在网络爬虫的设计中发挥了重要作用。其解释型和面向对象的特点,使得开发者们可以用更清晰的方式编写程序;而其动态语义的特性,为网络爬虫的开发提供了更大的灵活性。此外,Python所提供的各种库和模块,也为网络爬虫的设计提供了强大的支持,使得整个开发过程更加高效和便捷。因此,基于Python的网络爬虫设计是非常有优势的,值得开发者们去尝试和应用。

目 录
1 引言 1
1.1 网络教学系统的技术 1
1。2 本系统的特点和意义 2
2 系统核心技术特点 2
2。1 web 系统应用研究 2
2.1。1 N 层体系结构 2
2.1.2 基于组件开发 3
2.2 JSP/Servlet 对 web 应用系统的支持 3
3 系统分析 4
3。1 用例分析 4
3.2 用例建模 5
3。2.1 标识参与者 6
3.2。2 用例图 6
3。2。3 顺序图 7
3.2.4 活动图 8
3.3 分析类 10
3。3.1 边界类 10
3.3。2 实体类 10
3。3。3 控制类 11
4 系统设计 12
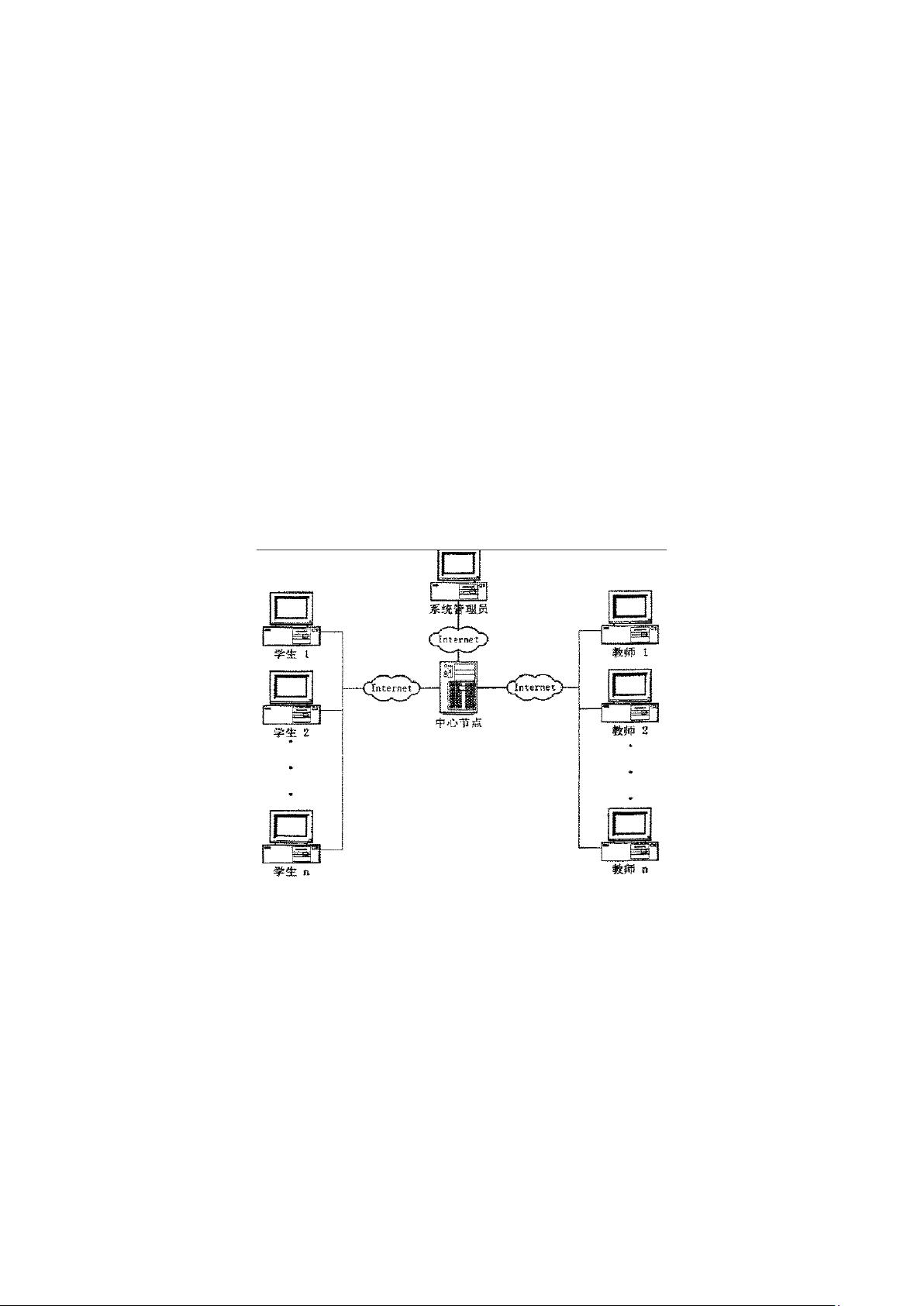
4.1 体系结构设计 12
4。2 系统功能设计 13
4.2.1 功能模块划分 13
4。2。2 功能实现设计 15
4。2.3 用例设计 18
4.3 数据库设计 19
4.3.1 数据库设计原则 19
4.3.2 系统数据库设计 20
5 关键技术及实现 22
5.1 用户身份鉴别 22
5.2 对会话的跟踪和处理 23
5.3 数据库连接池的实现 24
5.4 数据访问优化实现 26
5。5 系统安全实现 27
5.5。1 网络层安全 27
5.5。2 数据层安全 28
6 结束语 28
参考文献 29

剩余68页未读,继续阅读
2022-07-06 上传
2021-09-24 上传
2021-09-25 上传
2021-09-25 上传
132 浏览量
29064 浏览量
235 浏览量

yyyyyyhhh222
- 粉丝: 464
- 资源: 6万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- Simple Simon Game in JavaScript Free Source Code.zip
- 西门子工控软件PCS7电子学习解决方案.rar
- wc-marquee:具有派对模式的香草Web组件字幕横幅
- ansible-configurations:ansible配置
- 2,UCOS学习资料.rar
- Mancala Online-开源
- irddvpgp.zip_电机 振动
- aiopg:aiopg是用于从asyncio访问PostgreSQL数据库的库
- fist_springboot:第一个构建的springboot项目
- DataGo:这是我的数据科学页面
- WPE Pro 0.9a 中文版
- 西门子结构化编程.rar
- opaline-theme:VSCode的颜色主题
- simulink_SimMechanicS.zip_MATLAB s-function_simulink机械臂_机械臂 pd控制
- Auto Lotro Launcher-开源
- Simple Math Application
