网络爬虫实现原理:通用与聚焦爬虫解析
117 浏览量
更新于2024-08-27
收藏 488KB PDF 举报
"网络爬虫实现原理与技术"
网络爬虫是一种自动遍历互联网并抓取网页信息的程序,它能够帮助我们收集大量的网络数据。在本文中,我们将深入探讨两种常见的网络爬虫类型:通用网络爬虫和聚焦网络爬虫。
1. 通用网络爬虫
通用网络爬虫,也称为全网爬虫,其目标是尽可能广泛地抓取互联网上的信息。它的实现原理主要包括以下几个步骤:
- **获取初始URL**:爬虫的起点通常是用户指定的一个或多个初始网页URL。这些URL构成了爬取的种子集合。
- **爬取页面并提取新URL**:爬虫访问初始URL,解析网页内容,从中提取出新的链接URL。这些新URL会被添加到待爬取的URL队列中。
- **存储网页和URL管理**:爬虫将抓取到的网页保存到原始数据库,并记录已爬取的URL,以防止重复爬取。同时,URL队列用于控制爬取顺序和避免死循环。
- **持续爬取**:从URL队列中取出下一个URL,重复上述过程,直到队列为空或达到预设的停止条件,如时间限制、内存限制或已爬取页面数量等。
2. 聚焦网络爬虫
聚焦网络爬虫则更为定向,它专注于特定主题或领域,只抓取与目标相关的内容。其工作流程除了通用爬虫的步骤外,还包括额外的策略:
- **定义爬取目标**:首先明确爬虫的目标,例如特定关键词、主题或网站子集,为后续的链接过滤提供依据。
- **获取初始URL**:与通用爬虫相同,从与目标相关的初始URL开始。
- **过滤无关链接**:在爬取过程中,聚焦爬虫会检查每个新发现的URL,如果与目标不相关,则会忽略这些链接,确保只爬取与目标相关的内容。
- **选择下一步爬取的URL**:基于爬取目标的定义,爬虫会选择最相关的URL进行下一步爬取,这可能涉及到对URL的评分和优先级排序。
无论是哪种类型的爬虫,它们都需要处理一些共性问题,如网页编码识别、反爬虫策略、网页动态加载、cookies管理等。此外,为了保证爬虫的效率和合法性,还需要遵守robots.txt协议,尊重网站的抓取规则。
总结来说,网络爬虫是通过自动化的方式,从互联网上抓取大量信息的工具。通用爬虫广泛搜集信息,而聚焦爬虫则更加有针对性,两者在实现原理上有相似之处,但也各有特点。理解这些原理对于开发有效的网络爬虫至关重要,可以帮助我们在海量数据中高效地获取所需信息。
干货:一文看懂网络爬虫实现原理与技术干货:一文看懂网络爬虫实现原理与技术
01 网络爬虫实现原理详解
不同类型的网络爬虫,其实现原理也是不同的,但这些实现原理中,会存在很多共性。在此,我们将以两种典型的网络爬虫为
例(即通用网络爬虫和聚焦网络爬虫),分别为大家讲解网络爬虫的实现原理。
1. 通用网络爬虫
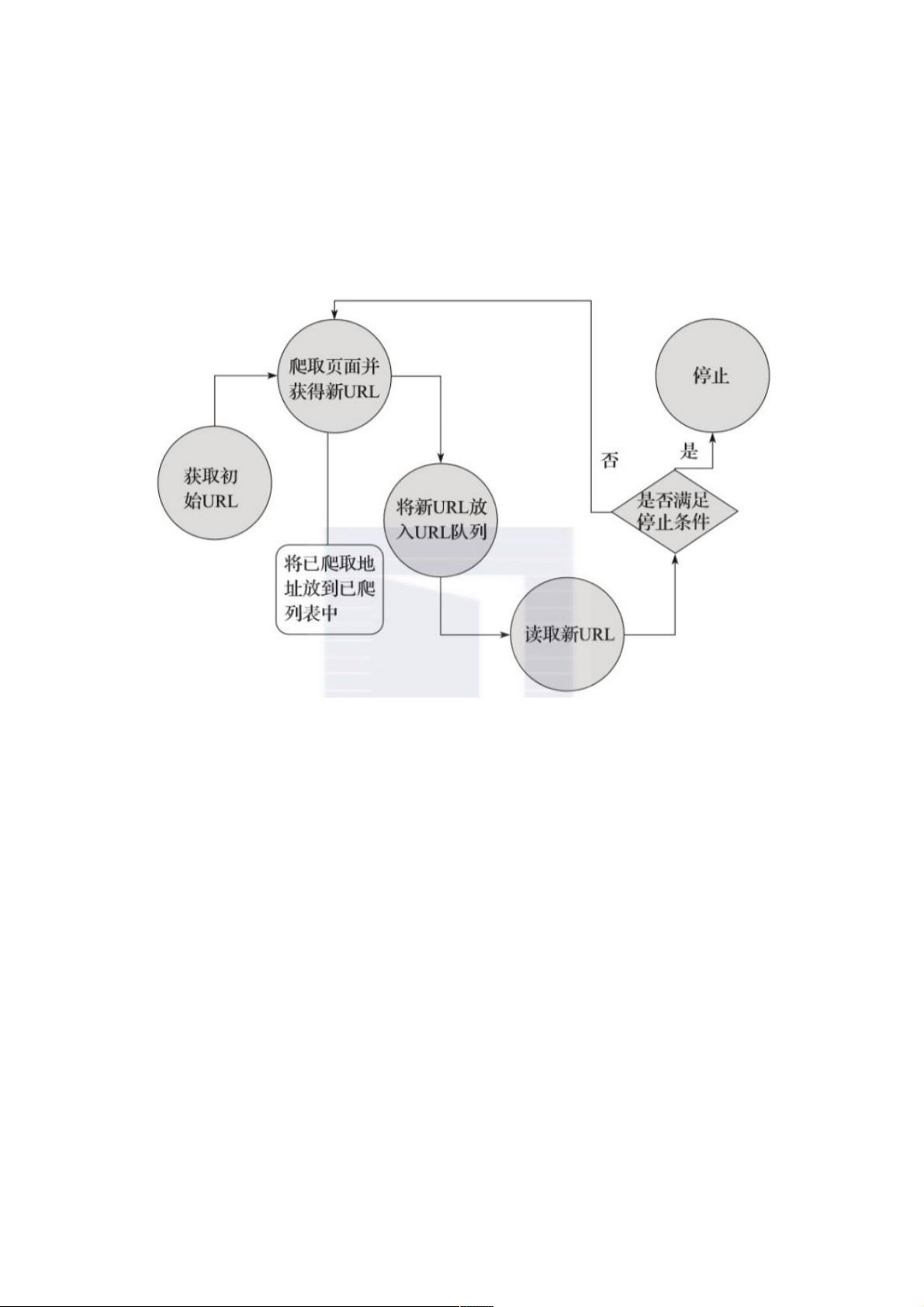
首先我们来看通用网络爬虫的实现原理。通用网络爬虫的实现原理及过程可以简要概括如下(见图3-1)。
▲图3-1 通用网络爬虫的实现原理及过程
获取初始的URL。初始的URL地址可以由用户人为地指定,也可以由用户指定的某个或某几个初始爬取网页决定。
根据初始的URL爬取页面并获得新的URL。获得初始的URL地址之后,首先需要爬取对应URL地址中的网页,爬取了对应的
URL地址中的网页后,将网页存储到原始数据库中,并且在爬取网页的同时,发现新的URL地址,同时将已爬取的URL地址存
放到一个URL列表中,用于去重及判断爬取的进程。
将新的URL放到URL队列中。在第2步中,获取了下一个新的URL地址之后,会将新的URL地址放到URL队列中。
从URL队列中读取新的URL,并依据新的URL爬取网页,同时从新网页中获取新URL,并重复上述的爬取过程。
满足爬虫系统设置的停止条件时,停止爬取。在编写爬虫的时候,一般会设置相应的停止条件。如果没有设置停止条件,爬虫
则会一直爬取下去,一直到无法获取新的URL地址为止,若设置了停止条件,爬虫则会在停止条件满足时停止爬取。
以上就是通用网络爬虫的实现过程与基本原理,接下来,我们为大家分析聚焦网络爬虫的基本原理及其实现过程。
2. 聚焦网络爬虫
聚焦网络爬虫,由于其需要有目的地进行爬取,所以对于通用网络爬虫来说,必须要增加目标的定义和过滤机制,具体来说,
此时,其执行原理和过程需要比通用网络爬虫多出三步,即目标的定义、无关链接的过滤、下一步要爬取的URL地址的选取
等,如图3-2所示。
下载后可阅读完整内容,剩余6页未读,立即下载
624 浏览量
129 浏览量
点击了解资源详情
175 浏览量
点击了解资源详情
253 浏览量
138 浏览量
148 浏览量
181 浏览量

weixin_38544075
- 粉丝: 10
- 资源: 931
 我的内容管理
展开
我的内容管理
展开







