Ubuntu下快速搭建Hadoop指南:从安装到运行
在Ubuntu环境下搭建Hadoop是一个常见的步骤,本文将详细介绍这个过程。首先,你需要在Windows中安装Ubuntu,这里推荐使用Ubuntu 11.10版本,通过wubi简易安装方式完成,尽管这种方法可能导致安装过程中的一些延迟,但因其简便性而被广泛采用。安装完成后,你需要:
1. **安装Linux操作系统**:使用Ubuntu-11.10-desktop-i386.iso镜像,通过wubi工具在Windows中进行安装。安装过程中可能会遇到卡顿,重启后再次尝试通常会有所改善。
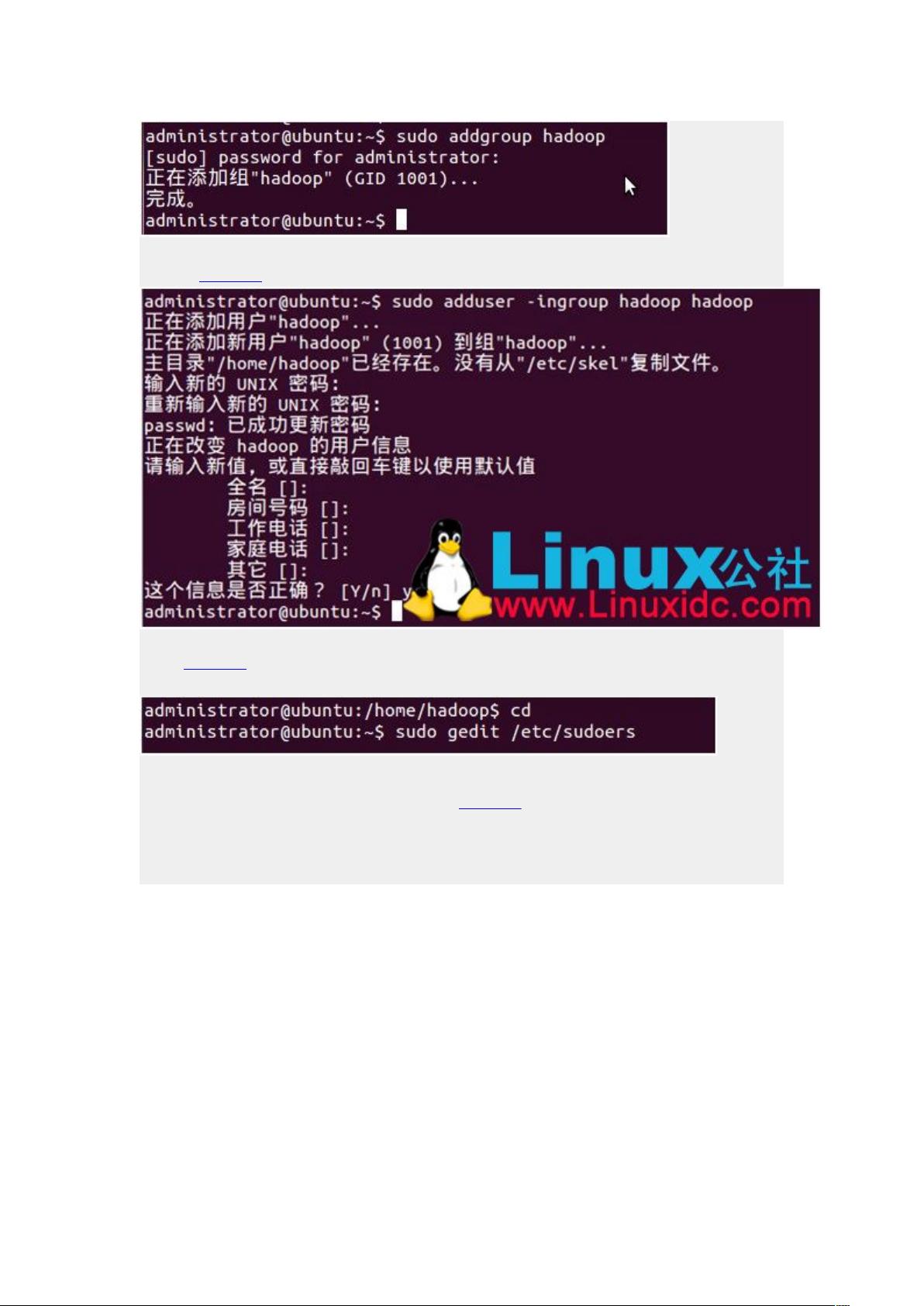
2. **创建Hadoop用户组和用户**:为了方便Hadoop应用的管理,建议创建一个专门的Hadoop用户组(名称为"hadoop")和用户,这样可以确保数据的安全性。首先,创建用户组,然后创建用户,最后将用户添加到sudoers文件中,赋予root级别的权限,以便执行Hadoop相关操作。
3. **安装JDK**:JDK(Java Development Kit)是Hadoop运行的基础,因为Hadoop使用Java语言编写。你需要从官方或可靠的源下载JDK,安装完成后,配置环境变量,确保系统能够识别和使用JDK。
4. **修改机器名**:为了提高集群管理的便利性,确保每台机器都有唯一的机器名。可以通过修改hostname命令行工具来设置。
5. **安装ssh服务**:SSH(Secure Shell)是远程访问的重要工具,需要在Ubuntu上安装并启用它,以便在Hadoop集群间进行安全通信。
6. **无密码登录设置**:为了简化管理,设置SSH免密登录,使得管理员能够在不输入密码的情况下登录到Hadoop节点。
7. **安装Hadoop**:从Apache官网下载Hadoop的最新稳定版本,根据官方文档进行安装,包括配置Hadoop环境变量、配置文件(如core-site.xml、hdfs-site.xml等)以及启动守护进程。
8. **单机测试**:在单机上测试Hadoop的运行,包括启动Hadoop守护进程(namenode、datanode等)、创建HDFS文件系统、运行MapReduce任务等。
以上步骤详细介绍了在Ubuntu系统上搭建Hadoop的基础过程,后续可能还需要配置Hadoop集群,如配置Hadoop HA(高可用性)和YARN(Yet Another Resource Negotiator)等高级特性。对于每个步骤,理解背后的原理和配置细节至关重要,这将有助于你更好地管理和优化Hadoop集群。
剩余10页未读,继续阅读
121 浏览量
107 浏览量
点击了解资源详情
221 浏览量
121 浏览量
539 浏览量
131 浏览量
2021-09-19 上传

preterhuman_peak
- 粉丝: 128
- 资源: 23
 我的内容管理
展开
我的内容管理
展开







