Boosting算法在实时人脸检测中的应用
需积分: 9 144 浏览量
更新于2024-07-23
收藏 312KB PDF 举报
"这篇论文是关于在实时人脸检测中应用boosting算法的经典研究,由Paul Viola和Michael J. Jones撰写,并发表在2004年的《国际计算机视觉杂志》57(2)期上。文章提出了一个能够在保持高检测率的同时实现极快速图像处理的面部检测框架。"
论文的主要贡献包括以下三个方面:
1. 积分图像(Integral Image):这是论文引入的一种新的图像表示方法。积分图像使得检测器所用到的特征计算变得非常迅速。通过对图像进行一次预处理,将每个像素的累积和存储起来,后续在检测过程中对图像块的计算可以显著加速,这为实时人脸检测提供了可能。
2. AdaBoost学习算法:作者利用AdaBoost(Adaptive Boosting)算法来构建一个简单且高效的分类器。AdaBoost是一种迭代的弱分类器组合方法,它可以从大量潜在特征中选择出一小部分关键的视觉特征。通过不断迭代和加权,这些弱分类器逐渐提升,最终形成一个强分类器,能够更准确地识别面部特征。
3. 级联分类器(Cascade Classifier):这是论文的第三个关键贡献。级联分类器是由多个弱分类器组成的序列,它们以一种前向传递的方式工作,允许在早期阶段快速过滤掉大部分非脸部区域,从而减少了后续计算的需求。这种设计极大地提高了检测速度,因为大部分背景区域可以在早期就被快速排除,只有少量潜在的人脸区域才会进入后续复杂的检测步骤。
Viola和Jones的方法革新了实时人脸检测技术,使得在当时能够在普通硬件条件下实现高效的人脸检测。这种方法后来被广泛应用于各种计算机视觉系统,包括安全监控、人脸识别软件以及智能手机等设备。至今,这个框架及其核心思想仍对计算机视觉领域有着深远的影响。
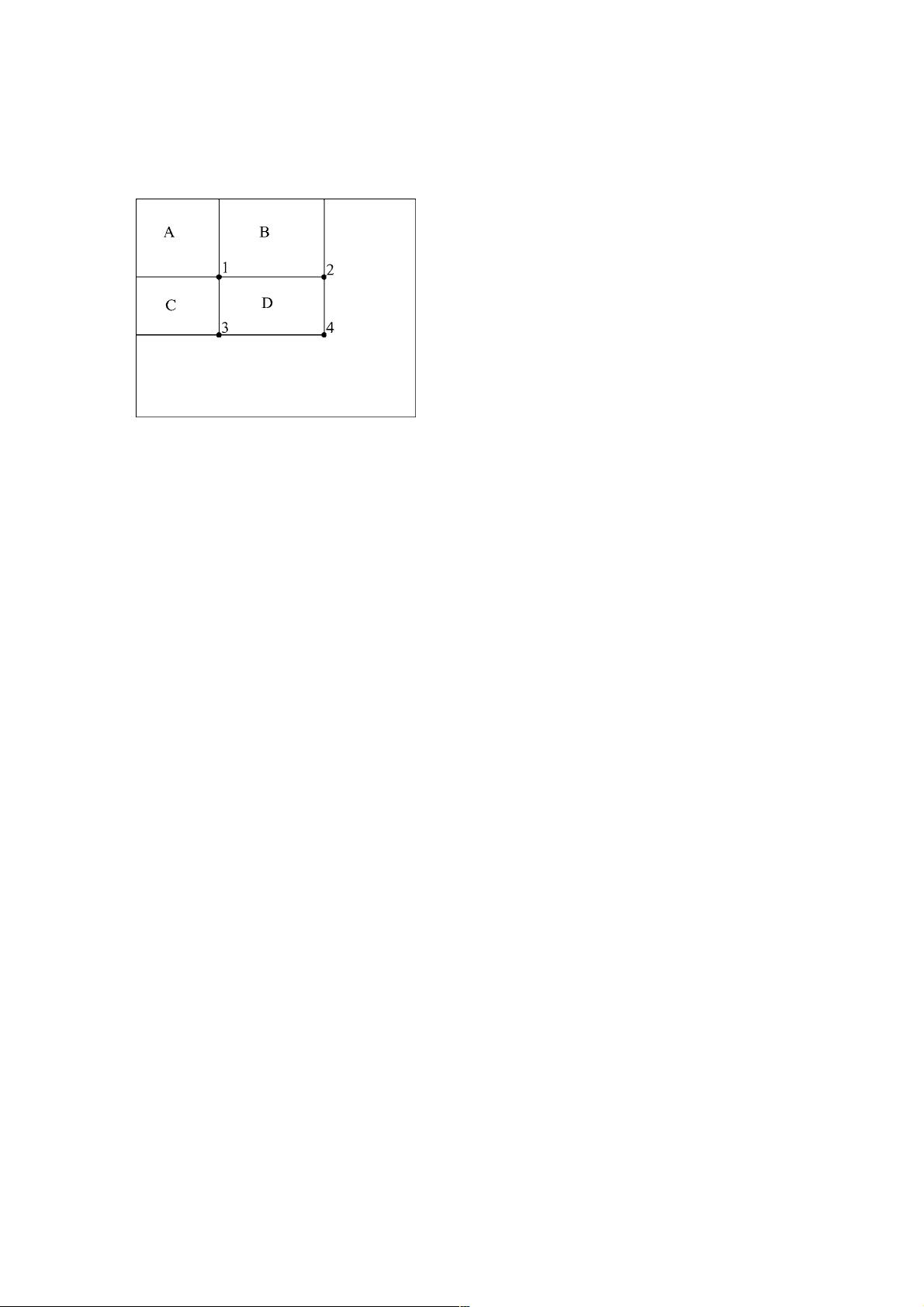
140 Viola and Jones
Figure 3. The sum of the pixels within rectangle D can be computed
with four array references. The value of the integral image at location
1isthe sum of the pixels in rectangle A. The value at location 2 is
A + B,atlocation 3 is A + C , and at location 4 is A + B + C + D.
The sum within D can be computed as 4 + 1 − (2 + 3).
(1999). The authors point out that in the case of linear
operations (e.g. f · g), any invertible linear operation
can be applied to f or g if its inverse is applied to the
result. For example in the case of convolution, if the
derivative operator is applied both to the image and the
kernel the result must then be double integrated:
f ∗ g =
( f
∗ g
).
The authors go on to show that convolution can be
significantly accelerated if the derivatives of f and g
are sparse (or can be made so). A similar insight is that
an invertible linear operation can be applied to f if its
inverse is applied to g:
( f
) ∗
g
= f ∗ g.
Viewed in this framework computation of the rect-
angle sum can be expressed as a dot product, i ·r , where
i is the image and r is the box car image (with value
1 within the rectangle of interest and 0 outside). This
operation can be rewritten
i · r =
i
· r
.
The integral image is in fact the double integral of the
image (first along rows and then along columns). The
second derivative of the rectangle (first in row and then
in column) yields four delta functions at the corners of
the rectangle. Evaluation of the second dot product is
accomplished with four array accesses.
2.2. Feature Discussion
Rectangle features are somewhat primitive when
compared with alternatives such as steerable filters
(Freeman and Adelson, 1991; Greenspan et al., 1994).
Steerable filters, and their relatives, are excellent for the
detailed analysis of boundaries, image compression,
and texture analysis. While rectangle features are also
sensitive to the presence of edges, bars, and other sim-
ple image structure, they are quite coarse. Unlike steer-
able filters, the only orientations available are vertical,
horizontal and diagonal. Since orthogonality is not cen-
tral to this feature set, we choose to generate a very
large and varied set of rectangle features. Typically the
representation is about 400 times overcomplete. This
overcomplete set provides features of arbitrary aspect
ratio and of finely sampled location. Empirically it ap-
pears as though the set of rectangle features provide
a rich image representation which supports effective
learning. The extreme computational efficiency of rect-
angle features provides ample compensation for their
limitations.
In order to appreciate the computational advantage
of the integral image technique, consider a more con-
ventional approach in which a pyramid of images is
computed. Like most face detection systems, our de-
tector scans the input at many scales; starting at the
base scale in which faces are detected at a size of
24 × 24 pixels, a 384 by 288 pixel image is scanned
at 12 scales each a factor of 1.25 larger than the last.
The conventional approach is to compute a pyramid of
12 images, each 1.25 times smaller than the previous
image. A fixed scale detector is then scanned across
each of these images. Computation of the pyramid,
while straightforward, requires significant time. Imple-
mented efficiently on conventional hardware (using bi-
linear interpolation to scale each level of the pyramid) it
takes around .05 seconds to compute a 12 level pyramid
of this size (on an Intel PIII 700 MHz processor).
5
In contrast we have defined a meaningful set of rect-
angle features, which have the property that a single
feature can be evaluated at any scale and location in a
few operations. We will show in Section 4 that effec-
tive face detectors can be constructed with as few as two
rectangle features. Given the computational efficiency
of these features, the face detection process can be com-
pleted for an entire image at every scale at 15 frames per
剩余17页未读,继续阅读
2019-04-22 上传
2020-07-31 上传
2019-09-10 上传
2009-10-13 上传
2009-10-21 上传
114 浏览量
2011-03-22 上传
2019-08-17 上传

Carl_dondon
- 粉丝: 16
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- 前端协作项目:发布猜图游戏功能与待修复事项
- Spring框架REST服务开发实践指南
- ALU课设实现基础与高级运算功能
- 深入了解STK:C++音频信号处理综合工具套件
- 华中科技大学电信学院软件无线电实验资料汇总
- CGSN数据解析与集成验证工具集:Python和Shell脚本
- Java实现的远程视频会议系统开发教程
- Change-OEM: 用Java修改Windows OEM信息与Logo
- cmnd:文本到远程API的桥接平台开发
- 解决BIOS刷写错误28:PRR.exe的应用与效果
- 深度学习对抗攻击库:adversarial_robustness_toolbox 1.10.0
- Win7系统CP2102驱动下载与安装指南
- 深入理解Java中的函数式编程技巧
- GY-906 MLX90614ESF传感器模块温度采集应用资料
- Adversarial Robustness Toolbox 1.15.1 工具包安装教程
- GNU Radio的供应商中立SDR开发包:gr-sdr介绍
