SparkSQL Catalyst源码解析:TreeNodeLibrary详解
193 浏览量
更新于2024-08-28
收藏 461KB PDF 举报
"SparkSQLCatalyst源码分析之TreeNodeLibrary"
SparkSQL的Catalyst模块是其核心执行引擎,它负责解析SQL语句并转化为可执行的计划。在深入探讨Catalyst的优化过程之前,理解TreeNode这一基础概念至关重要。TreeNode是构建Catalyst语法树的基本单元,它们共同构成了LogicalPlan,用于表示经过Analyzer阶段解析和验证后的SQL逻辑。TreeNodeLibrary是Catalyst中的关键组件,包含了所有TreeNode的实现。
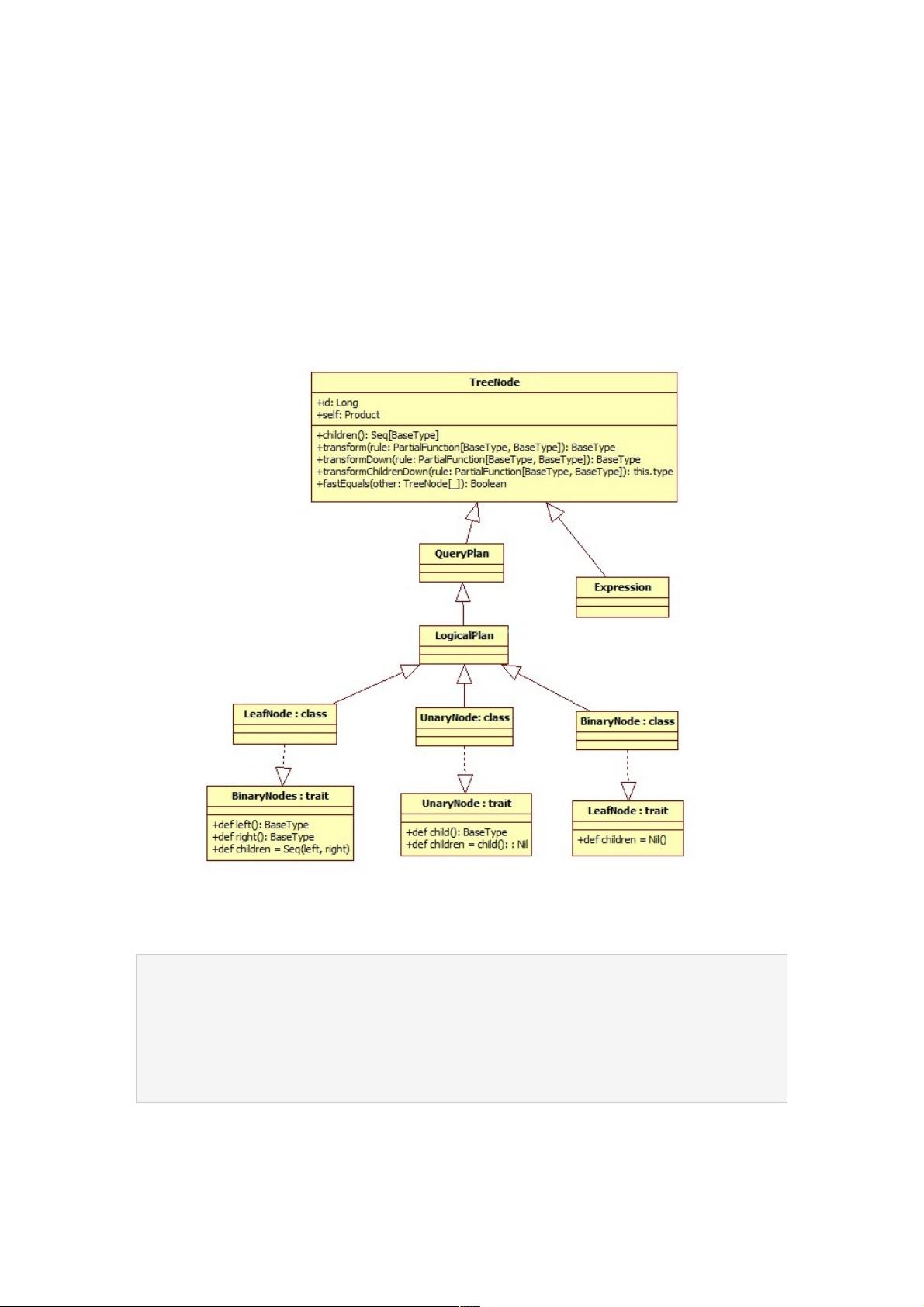
TreeNode是一个泛型类,继承自BaseType并实现了Product特质,这使得TreeNode能够存储不同类型的数据。TreeNode分为三种主要类型:BinaryNode、UnaryNode和LeafNode。
1. BinaryNode是具有两个子节点的二元节点,如`left`和`right`。在Catalyst中,这些节点通常是LogicalPlan的子类。BinaryNode的`children`属性是一个包含`left`和`right`的Seq。常见的二元节点包括Join操作(例如InnerJoin、LeftOuterJoin等)和Union操作,它们用于合并两个数据集。
```scala
trait BinaryNode[BaseType<:TreeNode[BaseType]] {
def left: BaseType
def right: BaseType
def children = Seq(left, right)
}
abstract class BinaryNode extends LogicalPlan with trees.BinaryNode[LogicalPlan] {
self: Product =>
}
```
2. UnaryNode是一元节点,只有一个子节点。这种节点在逻辑计划中代表那些只有一个输入的操作,如Project、Filter等。
```scala
trait UnaryNode[BaseType<:TreeNode[BaseType]] {
def child: BaseType
def children = Seq(child)
}
abstract class UnaryNode extends LogicalPlan with trees.UnaryNode[LogicalPlan] {
self: Product =>
}
```
3. LeafNode是无子节点的叶子节点,通常表示数据源或表达式。例如,TableScan表示从表中读取数据,而Literal则表示常量值。
TreeNode通过这些不同类型的节点构建出复杂的逻辑计划树,为后续的Optimizer提供基础。Optimizer通过应用规则和策略来改进LogicalPlan,生成更高效的OptimizedLogicalPlan,最终转化为物理执行计划。
了解TreeNode的结构和分类有助于我们理解SparkSQL如何处理SQL查询,以及在优化过程中如何对LogicalPlan进行变换。每个TreeNode都代表了SQL查询中的一个特定操作或部分,它们通过连接形成一个完整的查询执行流程。对于开发者来说,深入学习TreeNode的源码可以帮助优化SparkSQL应用程序,提高查询性能。
SparkSQLCatalyst源码分析之源码分析之TreeNodeLibrary
前几篇文章介绍了Spark SQL的Catalyst的核心运行流程、SqlParser,和Analyzer,本来打算直接写Optimizer的,但是发现忘
记介绍TreeNode这个Catalyst的核心概念,介绍这个可以更好的理解Optimizer是如何对Analyzed Logical Plan进行优化的生
成Optimized Logical Plan,本文就将TreeNode基本架构进行解释。
一、TreeNode类型
TreeNode Library是Catalyst的核心类库,语法树的构建都是由一个个TreeNode组成。TreeNode本身是一个BaseType <:
TreeNode[BaseType] 的类型,并且实现了Product这个trait,这样可以存放异构的元素了。
TreeNode有三种形态:BinaryNode、UnaryNode、Leaf Node.
在Catalyst里,这些Node都是继承自Logical Plan,可以说每一个TreeNode节点就是一个Logical Plan(包含Expression)(直
接继承自TreeNode)
主要继承关系类图如下:
1、BinaryNode
二元节点,即有左右孩子的二叉节点
[[TreeNode]] that has two children, [[left]] and [[right]].
trait BinaryNode[BaseType <: TreeNode[BaseType]] {
def left: BaseType
def right: BaseType
def children = Seq(left, right)
}
abstract class BinaryNode extends LogicalPlan with trees.BinaryNode[LogicalPlan] {
self: Product =>
}
节点定义比较简单,左孩子,右孩子都是BaseType。 children是一个Seq(left, right)
下面列出主要继承二元节点的类,可以当查询手册用 :)
这里提示下平常常用的二元节点:Join和Union
下载后可阅读完整内容,剩余9页未读,立即下载
2021-03-03 上传
2021-03-03 上传
2021-01-30 上传
2021-01-30 上传
点击了解资源详情
2024-12-21 上传
2024-12-21 上传
2024-12-21 上传
2024-12-21 上传

weixin_38548394
- 粉丝: 2
- 资源: 913
 我的内容管理
展开
我的内容管理
展开







最新资源
- JavaScript实现的高效pomodoro时钟教程
- CMake 3.25.3版本发布:程序员必备构建工具
- 直流无刷电机控制技术项目源码集合
- Ak Kamal电子安全客户端加载器-CRX插件介绍
- 揭露流氓软件:月息背后的秘密
- 京东自动抢购茅台脚本指南:如何设置eid与fp参数
- 动态格式化Matlab轴刻度标签 - ticklabelformat实用教程
- DSTUHack2021后端接口与Go语言实现解析
- CMake 3.25.2版本Linux软件包发布
- Node.js网络数据抓取技术深入解析
- QRSorteios-crx扩展:优化税务文件扫描流程
- 掌握JavaScript中的算法技巧
- Rails+React打造MF员工租房解决方案
- Utsanjan:自学成才的UI/UX设计师与技术博客作者
- CMake 3.25.2版本发布,支持Windows x86_64架构
- AR_RENTAL平台:HTML技术在增强现实领域的应用
