视觉SLAM详解:定位与建图关键技术
版权申诉
视觉SLAM(Simultaneous Localization and Mapping,同时定位与建图)是机器人技术中的关键模块,它解决了机器人在自主导航时面临的两大基本问题:定位自身所在位置(Where am I?)和构建周围环境的地图(What's my environment like?)。视觉SLAM将摄像头作为主要传感器,利用其采集的图像数据来实现这两项任务。
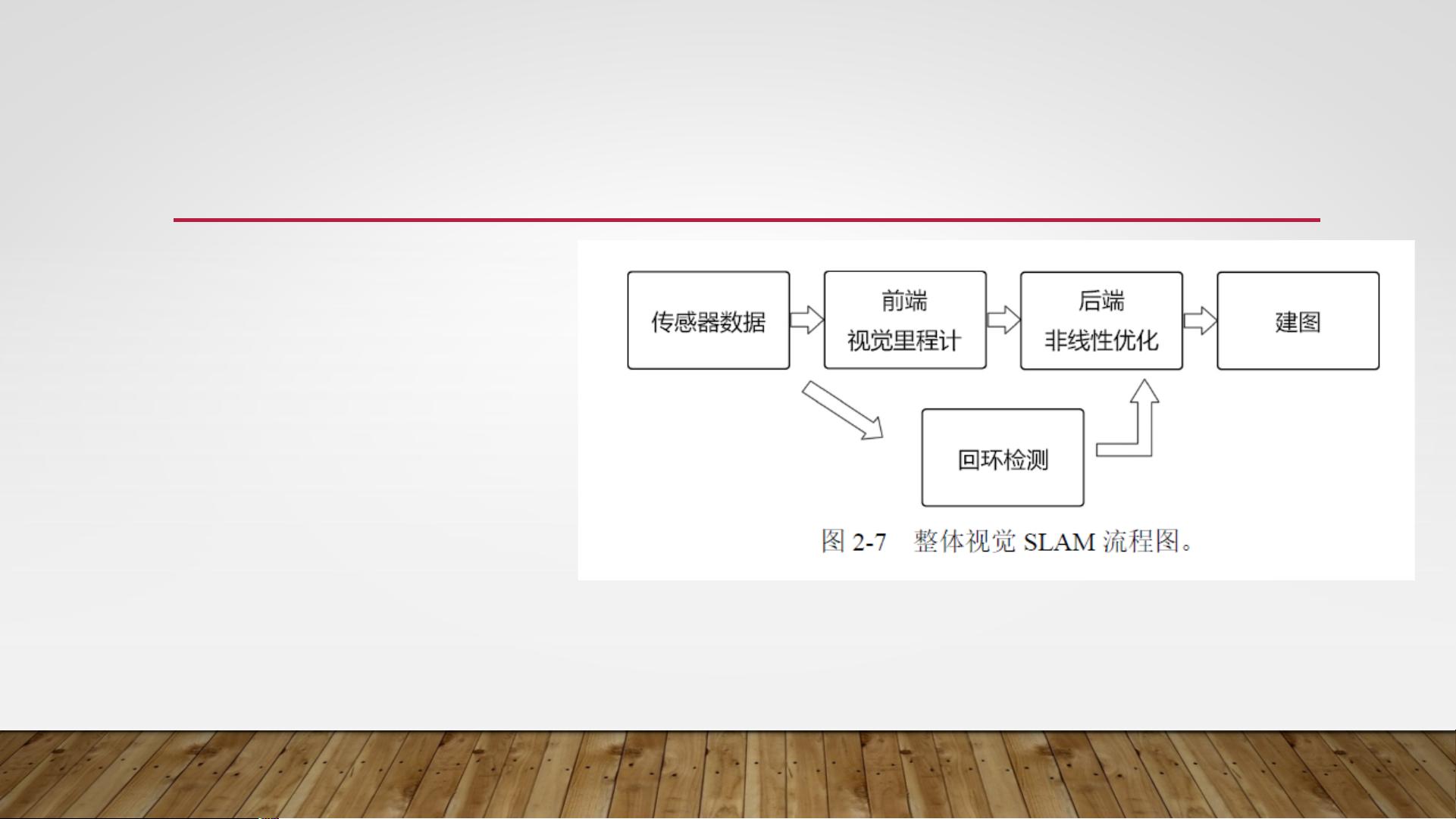
视觉SLAM分为前端和后端两个主要部分。前端负责实时估计机器人的运动状态,称为视觉里程计(Visual Odometry, VO),主要包括两种方法:特征点法和直接法。特征点法通过匹配图像中的特征点来计算相机的位姿变化,而直接法则是直接从像素级差异中估计运动,尽管这种方法更精确但计算量较大,且容易积累误差。
后端优化是视觉SLAM的重要环节,它通过优化算法如最大后验概率估计(Maximum A Posteriori, MAP)或现代的图优化技术,从带有噪声的数据中求解最优的轨迹和地图估计,减轻了前端的漂移问题。早期,基于卡尔曼滤波器(Extended Kalman Filter, EKF)的方法较为常见,但现在这些方法已逐渐被图优化方法所取代,后者能够更好地处理非线性系统和不确定性。
回环检测(Loop Closing)是视觉SLAM中的一个重要补充,它检测机器人是否返回到先前的位置,这对于长距离和大规模环境的导航至关重要。通过比较当前的图像和已知地图中的特征,可以确认重复路径并进行重定位,从而纠正可能的累积误差。
视觉SLAM中使用的相机类型多样,包括单目、双目(立体)、RGBD等,它们各有优缺点。单目相机由于缺少深度信息,需要通过移动相机来产生深度信息,计算量大;双目相机通过视差来估计深度,虽能提供相对准确的距离,但计算复杂;RGBD相机通过物理方法测量距离,虽然准确度高但量程有限,易受环境干扰。
在选择传感器时,会根据应用场景和需求权衡,如二维码标记、GPS和导轨用于固定环境的定位,而IMU、激光和相机则适用于携带式机器人。视觉SLAM是一项结合了计算机视觉、机器学习和机器人导航的复杂技术,它的成功应用对于无人驾驶、无人机、机器人导航等领域具有重要意义。


2021-07-27 上传
109 浏览量
2022-07-15 上传
2017-10-29 上传

文档优选
- 粉丝: 98
- 资源: 1万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- vb语言程序设计教程.zip
- sjasmplus:SJAsmPlus
- A06:作业6
- GnomeNibus-开源
- message-franking-tester:实施不同的邮件盖章方案和性能分析测试仪
- 机器学习python标记工具-Labelimg2024
- React-Portfolio:我的一小部分作品,用React重写
- MM32SPIN0x(s) 库函数和例程.rar
- goApi
- cuetools-开源
- Veni-Vidi-Voravi
- website:Terre Tropicale公共网站
- Main:基于struts2库存管理系统Android端
- Another-React-Lib:只是另一个充满可重用组件的React库
- 华为简历-求职简历-word-文件-简历模版免费分享-应届生-高颜值简历模版-个人简历模版-简约大气-大学生在校生-求职-实习
- 原型
