
+v:mala2255获取更多论
文
Sigmoid
线性
ReLU
线性
ReLU
线性
ReLU
线性
ReLU
线性
A A D
一
6 J. Kim等人。
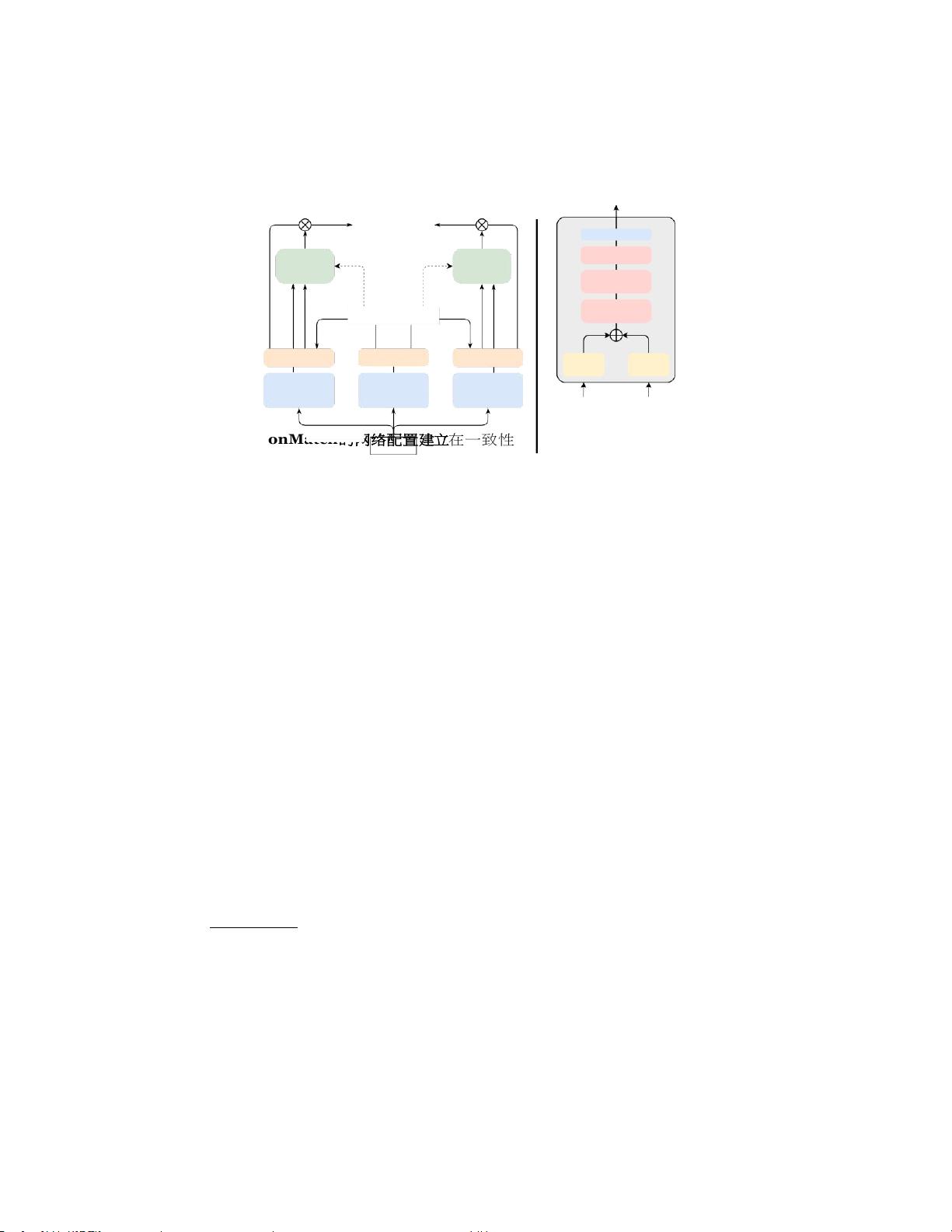
整体架构
置信度估计块
(参数法)估计置信度
特征
分类器
输出
图二、
ConMatch
的网络配置建立
在一致性损失基础上的半监督学习框架,
具有额外的强分支以利用两个强分支之间的一致性损失。在参数化方法中,
置信度估计器块将级联的异构特征作为输入,并产生伪标签的估计置信度。
[2019 - 04 - 15][2019 - 04 - 15][2019 - 04][2019 - 04 - 15][2019 -04][2019 - 04 -
04][2019 - 04][2019
L
self
=D(
Fi
(
r
)
,
Fi
(
r
))
,
(2)
其中,分别从具有两个不同的强增强图像i()和j()的图像中提取
Fi
(
r
)
= f
(
Ai
(
r
))和
Fj
(
r
)= f
(
Aj
(
r
))。(
,
)可以定义为对比
损失[22]或负余弦相似性[10]。即使
这种
损失
有助于
最大限度地
学习
特征
编码
器
f
(
·
),
但是
简单地提取特征
Fi
(
·
)和
Fj
(
·
)的机制对于提升
半监督学习器并打破潜在特征空间可能不是最佳的,而不考虑表示哪
个分支更好的方向。
3.2 制剂
为了将半监督学习和自监督学习范式结合在一起,与[25,33,34]不同,
我们提出有效地利用两
个强
分支之间的自监督来促进半监督学习,称为
ConMatch。与现有的自监督表示学习方法不同,例如,SimSiam [10]中,
我们在类logit-级别
4
制定一致性正则化损失,如在半监督学习方法[47,58]
中所做的那样,并估计来自两
个强
增强图像的每个伪标签的置信度,对
于
r
,
Ai
(
r
)和
j
(
r
),并使用它们来考虑它们之间每个方向的概率。由
于测量这种信心是众所周知的挑战,我们提出
4
在本文
中,
类
logit
表示
网络
的
输出
,
即,
p
m o
de l
(
y
|
r
;
θ
)
对于r
.
一致性损失
置信度估
计器
置信度损失
置信度估
计器
无监督损失
分类器
分类器
分类器
特征编
码器
特征编
码器
弱螺旋
特征编
码器
strong aug 1 strong aug 2图片

剩余30页未读,继续阅读

cpongm
- 粉丝: 5
- 资源: 2万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- 前端面试必问:真实项目经验大揭秘
- 永磁同步电机二阶自抗扰神经网络控制技术与实践
- 基于HAL库的LoRa通讯与SHT30温湿度测量项目
- avaWeb-mast推荐系统开发实战指南
- 慧鱼SolidWorks零件模型库:设计与创新的强大工具
- MATLAB实现稀疏傅里叶变换(SFFT)代码及测试
- ChatGPT联网模式亮相,体验智能压缩技术.zip
- 掌握进程保护的HOOK API技术
- 基于.Net的日用品网站开发:设计、实现与分析
- MyBatis-Spring 1.3.2版本下载指南
- 开源全能媒体播放器:小戴媒体播放器2 5.1-3
- 华为eNSP参考文档:DHCP与VRP操作指南
- SpringMyBatis实现疫苗接种预约系统
- VHDL实现倒车雷达系统源码免费提供
- 掌握软件测评师考试要点:历年真题解析
- 轻松下载微信视频号内容的新工具介绍
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


