C#轻松操作:合并与拆分PDF文件全程代码
192 浏览量
更新于2024-08-29
收藏 260KB PDF 举报
本文主要介绍了如何使用C#编程语言实现PDF文件的合并与拆分功能。针对常见的需求场景,即PDF资料被分散在多个文件中不便管理和阅读,本文提供了具体的技术解决方案。
**合并PDF文件**
在C#中,合并PDF文件的过程相当直接且易于实现。首先,你需要导入Spire.Pdf库,这是一个用于处理PDF文档的工具包。以下是关键步骤:
1. **准备工作**:定义一个字符串数组`InputFiles`,包含所有需要合并的PDF文件路径,如`String[] files = new String[]{"文件1.pdf", "文件2.pdf", "文件3.pdf"}`。
2. **调用合并方法**:使用`PdfDocumentBase.MergeFiles`方法,传入文件路径数组,例如`PdfDocument doc = PdfDocument.MergeFiles(files)`。
3. **保存结果**:将合并后的PDF对象保存到指定的输出文件(如`outputFile = "输出.pdf"`),并设置输出格式为PDF,如`doc.Save(outputFile, FileFormat.PDF)`。
4. **启动查看器**:最后,可以使用`System.Diagnostics.Process.Start(outputFile)`打开合并后的PDF文件,以便查看结果。
**拆分PDF文件**
拆分PDF文件则有多种方式,这里介绍两种主要方法:
1. **拆分每一页为单独文件**:如果目标是每个页面独立,可以读取合并后的PDF,然后逐页拆分。例如,创建一个新的`PdfDocument`对象,使用`doc.SplitPages()`方法,对每一页进行操作,生成新的PDF文件,使用自定义命名模式(如`String pattern = "拆分-{0}.pdf"`)。
2. **按页码范围拆分**:如果你只需要特定页码的PDF文件,可以先确定页码范围,然后使用类似的方法读取并保存指定页面。这可能涉及到遍历整个PDF文档,提取特定页码的页面内容,并保存到新的PDF文件中。
通过C#的Spire.Pdf库,你可以轻松地实现PDF文件的合并和拆分,满足不同场景下的文件管理需求。通过这些操作,你可以提高工作效率,同时保持文档的整洁和便于使用。
C#实现合并及拆分实现合并及拆分PDF文件的方法文件的方法
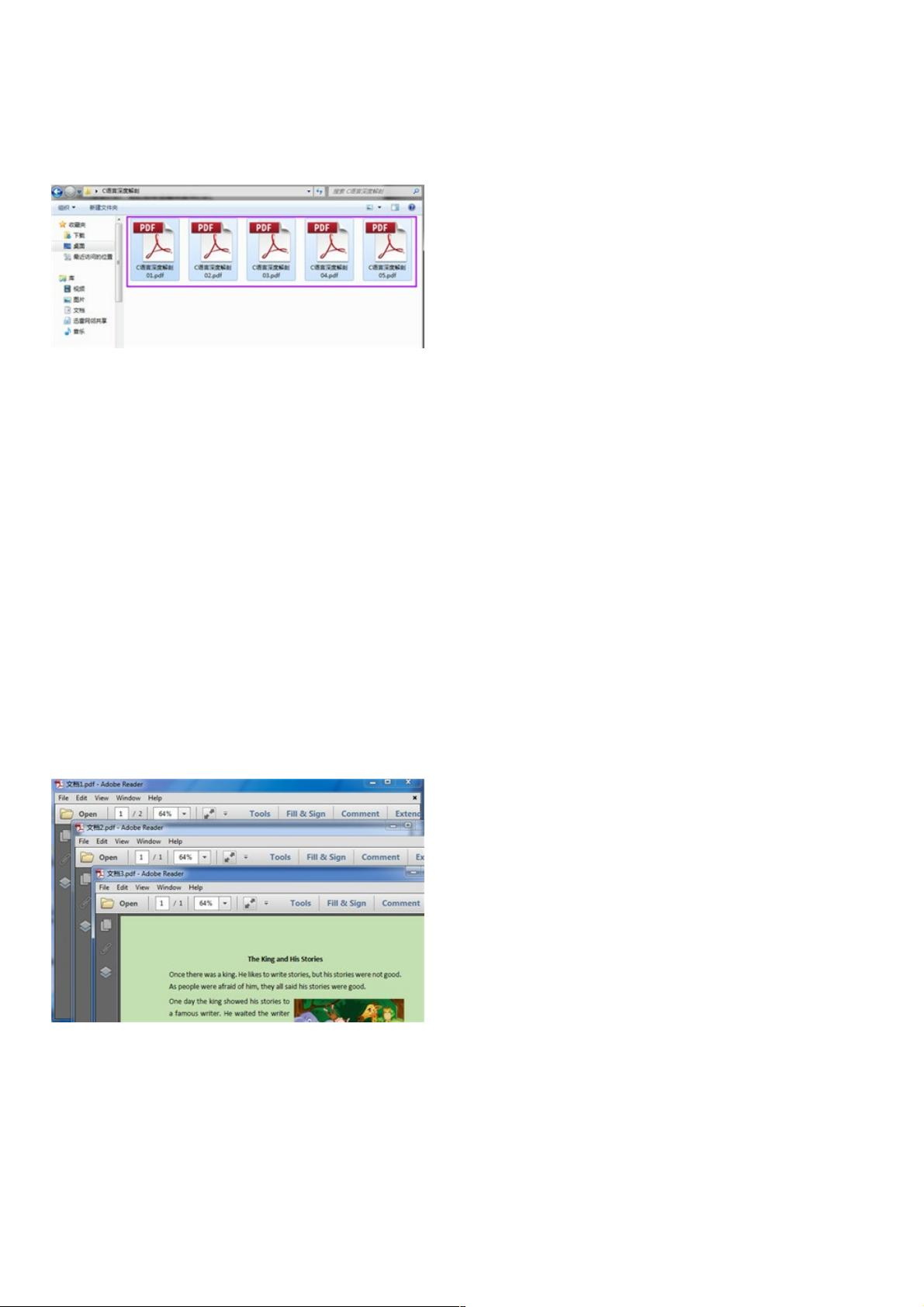
有时我们可能会遇到下图这样一种情况 — 我们需要的资料或教程被分成了几部分存放在多个PDF文件中,不管是阅读还是保
存都不是很方便,这时我们肯定想要把这些PDF文件合并为一个PDF文件。相对应的,有时候我们也需要拆分一个大的PDF文
件,来从中获取我们需要的那一部分资料。这篇文章主要分享如何使用C#来将多个PDF文件合并为一个PDF文件以及将一个
PDF文件拆分为多个PDF文件。
合并合并PDF文件文件
合并PDF文件的代码很简单,主要分为三步,首先获取需要合并的PDF文件,然后调用public static PdfDocumentBase
MergeFiles(string[] InputFiles)方法,将这些PDF文件合并,然后保存文件。
代码如下:
using System;
using Spire.Pdf;
namespace 合并PDF文件
{
class Program
{
static void Main(string[] args)
{
String[] files = new String[] { "文件1.pdf", "文件2.pdf", "文件3.pdf" };
string outputFile = "输出.pdf";
PdfDocumentBase doc = PdfDocument.MergeFiles(files);
doc.Save(outputFile, FileFormat.PDF);
System.Diagnostics.Process.Start(outputFile);
}
}
}
合并前:
合并后:
下载后可阅读完整内容,剩余3页未读,立即下载
293 浏览量
241 浏览量
148 浏览量
1401 浏览量
174 浏览量
293 浏览量
1704 浏览量
241 浏览量
503 浏览量

weixin_38695159
- 粉丝: 5
- 资源: 942
 我的内容管理
展开
我的内容管理
展开







最新资源
- zabaatLib:vvolfster的QML Qt UI和应用程序库
- proposal-array-equality:确定数组相等
- SQLite v3.28.0
- jQuery css3图标动画鼠标滑过图标旋转动画特效
- vecel-antenna
- MP3格式万能转换器任何音频均可自由切换格式
- 黑马瑞吉外卖源码及工程项目全套
- Foodfy-database:Persistindo dados daaplicaçãoFoodfy
- 展示::framed_picture:课程中展示的最佳学生作品展示
- Open Virtual Reality 'L'-开源
- 影响matlab速度的代码-table-testing:表达式矩阵文件格式的要求,示例和测试
- 行业文档-设计装置-饲料用缓释型复方甜菊糖微囊的制备方法.zip
- RedisSubscribeServer.zip
- Wireshark-win32-1.8.4
- C# winform设计 钉钉 微信 二维码 扫码登录登录客户端 源码文件 CS架构
- Martin_Barroso_P2:RISCV Multiciclo con UART para corrercódigo阶乘
