虚拟机中安装Hadoop1详细步骤
版权申诉
33 浏览量
更新于2024-07-06
收藏 2.79MB DOCX 举报
"这是关于在虚拟机中安装Hadoop1的详细步骤,主要涉及虚拟机配置、Linux系统安装以及网络设置。"
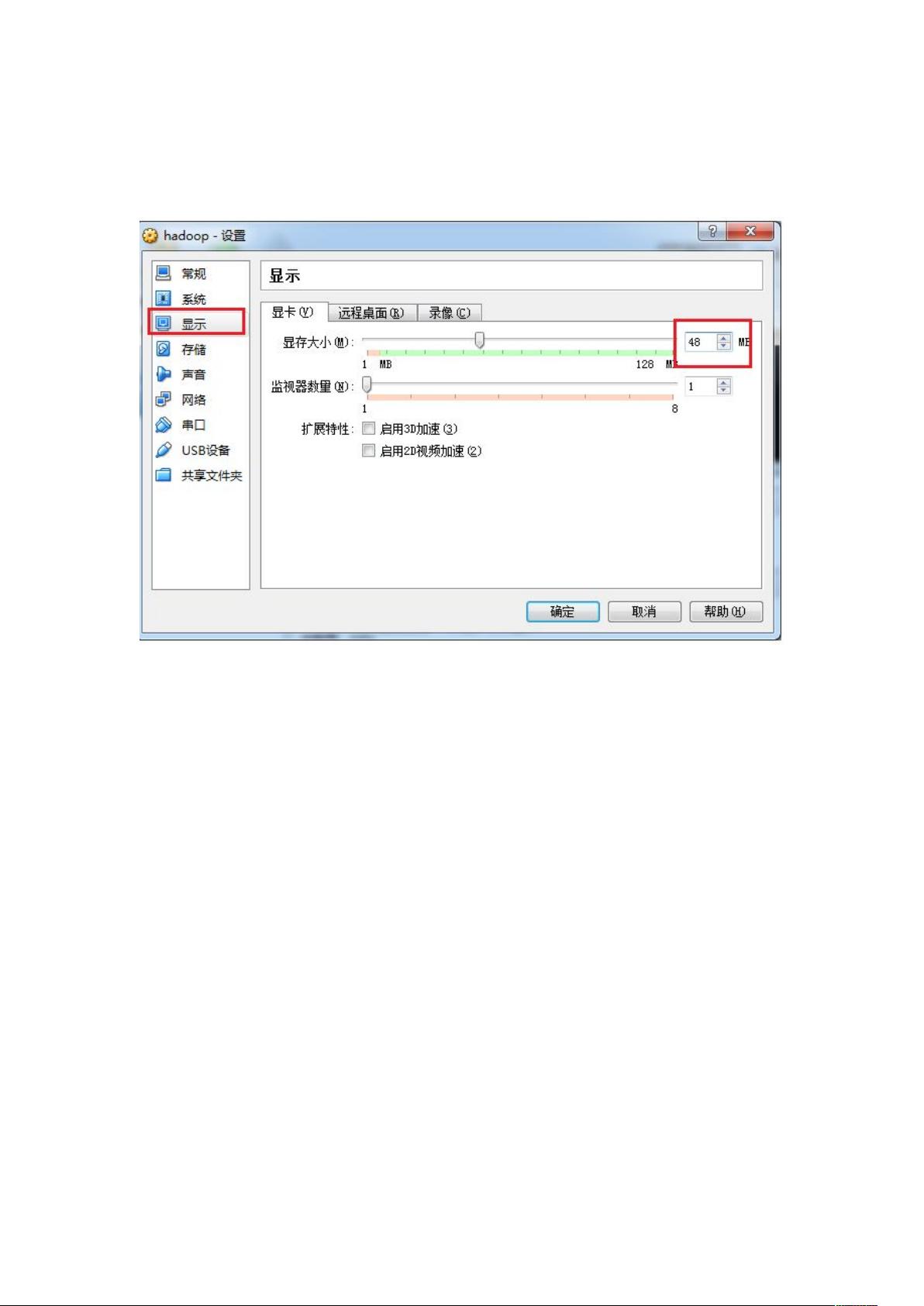
在安装Hadoop之前,首先需要在虚拟机上搭建Linux环境。此处选择了虚拟机软件,并创建了一个新的虚拟机。在创建过程中,确保虚拟机的内存至少为1024MB,以便支持图形化界面安装。同时,选择动态分配的硬盘类型以节省磁盘空间。接着,设置虚拟机的各项属性,如虚拟机备份位置、显示内存大小以保证安装过程流畅,以及网络适配器的配置。
对于网络配置,虚拟机中通常有两个网卡:网卡1和网卡2。网卡1通常设置为桥接模式,与主机的物理网络接口(如本地连接或无线网卡)相连,以使虚拟机可以直接访问外网。网卡2则设置为仅Host-only模式,用于创建一个隔离的网络环境,适合内部通信,如Hadoop集群中的节点间通信。
在安装Linux系统时,可能会遇到不支持非i686架构的错误,这可能是因为虚拟化技术未开启,需要进入BIOS进行设置。安装过程中选择合适的语言(如中文简体)以方便操作,同时在安装前要对系统进行必要的配置,例如设置主机名,这将在集群环境中起到标识作用。
网络配置是关键环节,包括两个网卡的IP设置。网卡1(eth0)通常设置为自动获取IP(DHCP),以便从路由器获取网络信息;而网卡2(eth1)则设置为手动指定IP,例如在192.168.56.0/24这个子网内分配一个IP,以便于在Host-only网络中与其他虚拟机通信。
安装完成后,Hadoop的部署需要在Linux环境下进行。Hadoop是一个分布式计算框架,由HDFS(Hadoop Distributed File System)和MapReduce两部分组成。HDFS负责数据的分布式存储,而MapReduce则处理大规模数据的并行计算。在单个节点上安装Hadoop1时,通常会包含Hadoop的主节点组件,如NameNode、JobTracker等,以及DataNode和TaskTracker组件。
为了运行Hadoop,还需要配置相关的环境变量,如HADOOP_HOME、PATH等,并根据集群规模调整Hadoop配置文件(如hdfs-site.xml、mapred-site.xml)。同时,初始化HDFS并启动相关服务,如格式化NameNode、启动DataNode和TaskTracker。在多节点集群中,还需要配置 slaves 文件以指定其他DataNode节点。
安装Hadoop1涉及多个步骤,包括虚拟机的创建和配置、Linux系统的安装、网络设置以及Hadoop环境的搭建。每个环节都需要仔细操作,确保Hadoop能够在虚拟机中正常运行,并为后续的大数据处理提供基础平台。
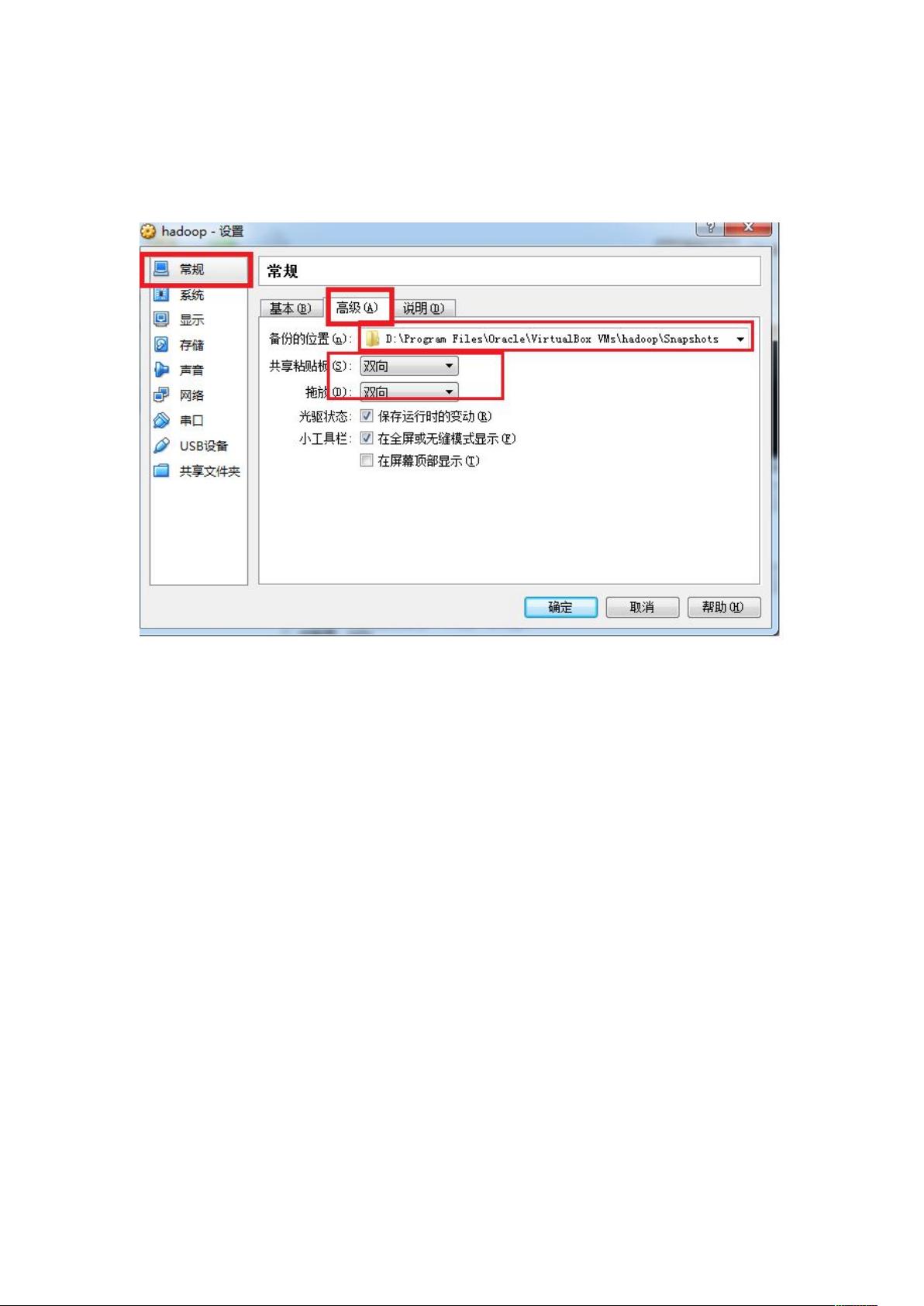
1.1.9. 常规-高级,虚拟机备份位置
剩余47页未读,继续阅读
2022-11-24 上传
2021-10-05 上传
2022-10-16 上传
2022-10-13 上传
2021-09-19 上传
2019-08-27 上传
2024-07-16 上传
2021-04-02 上传

猫一样的女子245
- 粉丝: 234
 我的内容管理
展开
我的内容管理
展开







最新资源
- 虚幻引擎4经典FPS游戏开发包解析
- 掌握LaTeX中psfig.sty的使用技巧
- 探索X102 51学习板:深入嵌入式系统开发
- 深入理解STM32外部中断的实现与应用
- 大冶市数字高程模型(DEM)数据详细解读
- 俄罗斯方块游戏制作教程:Protues实现指南
- ASP.NET视频点播系统源代码及论文:多技术项目资源集锦
- Platzi JavaScript课程体系:全面覆盖初、中、高级
- cutespotify:跨平台MeeSpot音乐播放器兼容SailfishOS
- PictureEx类:在VC6下显示jpg与gif动图
- 基于stc89C51的数字时钟Proteus仿真设计
- MATLAB全面基础教程与实践技巧分享
- 实现双行文字向上滚动效果的js插件
- Labview温度报警系统:实时监控与声光警报
- Java官网ehcache-2.7.3实例教程
- A-Frame超级组件集:超帧的创新与应用
