GPU排序新突破:Onesweep LSD基数排序算法
140 浏览量
更新于2024-08-03
1
收藏 3.98MB PDF 举报
"Onesweep是一种针对GPU的更快的最小位数字基数排序算法,由NVIDIA Corporation的Andy Adinets和Duane Merrill提出。该算法专为处理存储在全局内存中的大规模数据排序问题设计,显著降低了最后级别内存流量,提高了排序效率。在NVIDIA A100 GPU上,Onesweep在排序256M随机32位键时可达到29.4 GKey/s的速度,相比CUB有约1.5倍的性能提升。"
在计算机科学领域,排序算法是数据处理的重要部分,特别是在高性能计算和大数据处理中。GPU(图形处理单元)由于其并行计算能力,已经成为解决大规模计算问题的首选平台。然而,有效地在GPU上执行排序任务仍然是一个挑战,因为需要处理大量数据并减少内存访问的开销。
Onesweep算法引入了一种创新的单次传递前缀和方法,用于最小位数字(LSD)基数排序。传统的GPU基数排序通常需要两次遍历来完成每个数字位的分配,导致较高的全局内存操作数量。Onesweep通过一次遍历就完成这个过程,显著减少了内存交互次数,大约只需要2n次全局读写操作,从而降低了内存带宽的需求,这对于GPU性能至关重要。
在性能比较方面,Onesweep在处理随机32位键时表现优异,速度比CUB(目前最先进的GPU LSD基数排序库)快约1.5倍。这表明Onesweep在处理大规模数据集时能提供更高的吞吐量。此外,对于具有不同分布的32位键,Onesweep相对于当前的GPU最重大位(MSD)基数排序算法HRS提供了更一致的性能,并且在大多数情况下表现更优。
关键词包括:图形处理器、排序算法、毕业设计、算法。这些关键词强调了Onesweep算法在GPU计算环境中的重要性,以及它对教育和研究领域的潜在贡献。Onesweep的提出,不仅优化了现有的GPU排序技术,还可能启发未来更高效的并行计算解决方案。
Onesweep: A Faster Least-Significant-Digit Radix Sort for GPUs
June, 2022
CUB library has increased from r = 16 (eight digit-binning
iterations) to r = 128 (five digit-binning iterations) for large
32-bit sorting problems [12].
In contrast, comparison-based sorting methods have
super-linear O(nlogn) asymptotic work complexity.
Furthermore, practicable strategies for reducing the number
passes through global memory have been elusive. For
example, state-of-the-art GPU merge sorting
implementations perform binary (radix-2) merging [5,8]. As
such, a merge sort of 16M 32-bit keys will require ~10
passes through global memory (i.e., one pass to bootstrap
32K sublists followed by nine binary merging passes),
whereas our Onesweep LSD radix sort only requires five
(i.e., one histogram pass followed by four binning
iterations).
Prefix sum. An exclusive prefix sum across a list of
numbers produces a corresponding list in which the i
th
output is the sum of the first i-1 inputs. It is a useful
construct for allocation-like behavior in parallel settings
(partitioning, binning, compaction, queuing, etc.), where the
offset for the i
th
thread to write its output is the sum of the
number of output items being produced by the prior i-1
threads.
Prefix sum plays two roles in digit binning. The first is
determining the starting location of each bin in the output
buffer such that no space is wasted. For example, an
exclusive prefix sum across the radix r = 8 histogram
<8,6,7,5,3,0,9,2> of digit counts produces the
corresponding list of offsets <0,8,14,21,26,29,29,38>
indicating the locations of the 0s, 1s, 2s, etc. bins in the
output buffer.
Prefix sum is also used to compute the bin-relative
offsets for scattering keys into their destination bins.
Specifically, a prefix sum across a list of binary flags
indicating which keys contain a given digit will produce a
corresponding list of scatter offsets within that digit’s output
bin. Given the list of keys <17,8,24,5>, for example, the
flag list <0,1,1,0> corresponds to the presence of a 0s digit
in the least-significant 3-bit digit-place. A prefix sum of
these flags produces the scatter offsets <0,0,1,2> for
relocating the flagged keys relative to the start of the 0s bin.
Thus, each digit-binning iteration entails computing r prefix
flag sums, one for each bin.
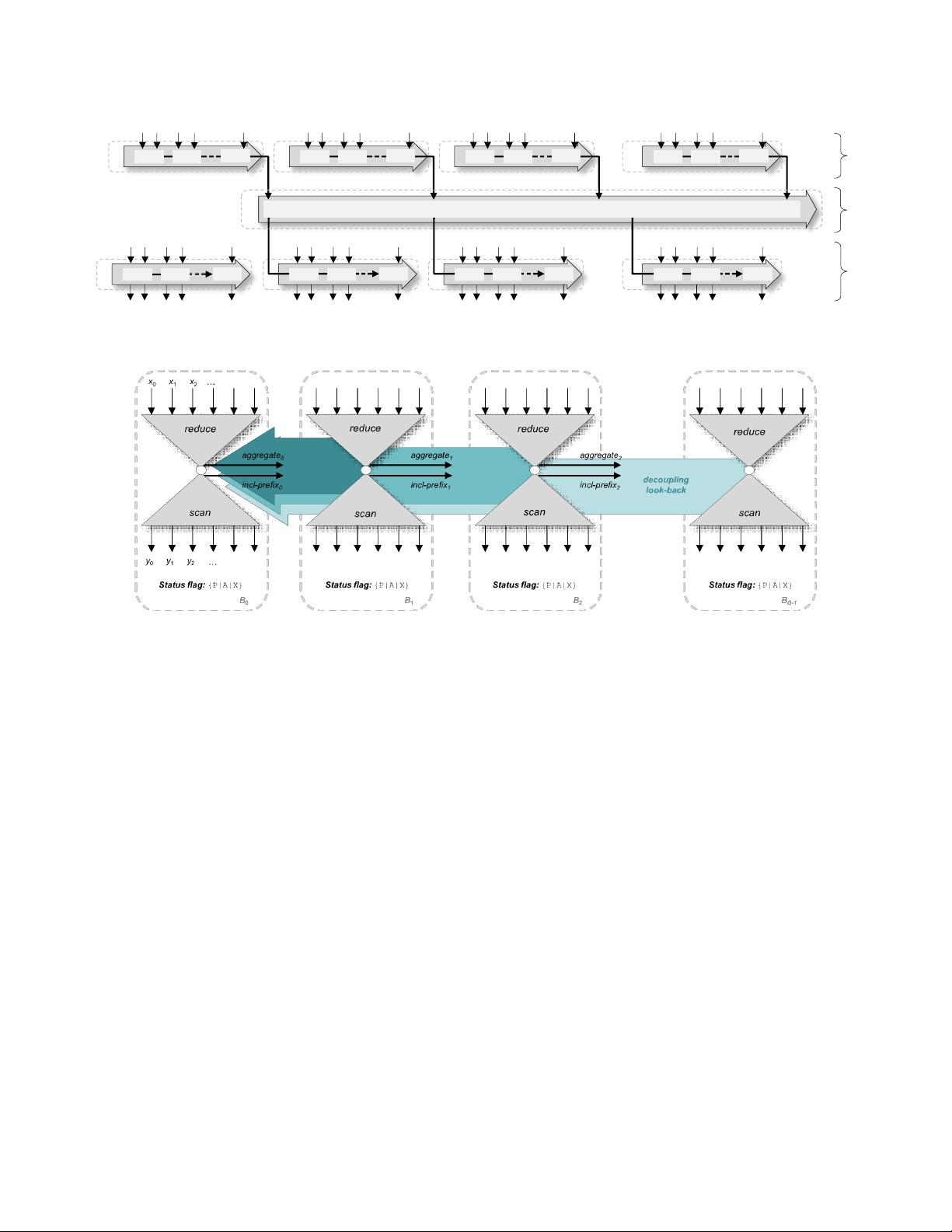
Figure 1. Three-kernel reduce-then-scan parallelization among G thread blocks (~3n global data movement) [12]
Figure 2. Single-pass adaptive look-back prefix scan among G thread blocks (~2n global data movement) [12]
reduce
reduce
x
0
x
b-1
x
b
…
B
0
…
reduce reduce
reduce
…
reduce
…
B
1
reduce reduce
reduce
…
reduce
…
B
2
reduce reduce
reduce
…
reduce
…
B
G-1
reduce reduce
reduce
…
reduce
…
B
1
…
scan
…
…
reduce
…
B
2
…
scan scan
scan
…
…
reduce
x
0
x
b-1
x
b
…
B
0
…
scan scan
scan
…
…
y
0
y
b-1
y
b
B
0
reduce
…
B
G-1
…
scan scan
scan
…
…
scan
…
upsweep
pass
downsweep
pass
root scan
scan scan
剩余11页未读,继续阅读
2025-01-09 上传
2025-01-09 上传
2025-01-09 上传
2025-01-09 上传
2025-01-09 上传
2025-01-09 上传

0x0007
- 粉丝: 3697
- 资源: 487
 我的内容管理
展开
我的内容管理
展开







最新资源
- 免除登录繁琐步骤,QQ登录器
- responsiveapp
- Boundless-Marble
- 电子功用-多功能通用电锁
- 保险公司新干部培训班课后作业
- Curso_JavaScrip_Rocketseat-:JavaScript的模数模
- 泉中流版base64编码和解码(支持汉字等编码(utf-8))
- wget在线扒站.zip
- personal-website:我的个人网站上列出了项目等
- Reservia:Reservia是一个预订网站
- JerryQuu:使用Typescript编写的Node.js的快速,可靠的基于Redis的电子邮件队列
- d-pyro.github.io:PS4 6.72漏洞利用
- gulp-framer-skeleton:一个基于 FramerJS 的基于 gulp 的骨架项目
- 2016年“ 蓝桥 杯” 第 七 届 全国 软件和信息技术专业人才 大赛 个人赛——温湿度监控设备·代码.zip
- Story:学习git
- 保险公司新人成功销售训练培训班操作标准
