应对过拟合:正则化策略与模型容量的关系
需积分: 0 28 浏览量
更新于2024-08-05
收藏 660KB PDF 举报
正则化输入1主要探讨了机器学习中的关键概念,特别是如何处理过拟合和欠拟合问题,以及独立同分布假设在模型评估中的作用。首先,我们来深入理解这两个核心概念:
1. **欠拟合与过拟合**
- 欠拟合和过拟合是衡量机器学习模型性能的两个重要方面。欠拟合指的是模型未能充分学习训练数据的特性,导致泛化能力不足,表现为训练误差较大,而测试误差也可能较高。过拟合则是模型过于复杂,过分适应训练数据中的噪声,以至于在未见过的数据上表现不佳,训练误差低但测试误差高。
2. **独立同分布假设**
- 在理想情况下,数据集中的样本被认为是独立且同分布的,即所有样本都按照同一概率分布生成。这一假设使得我们可以仅通过训练数据估计整体的模型性能。然而,现实情况中这一假设通常难以满足,但它仍然是模型评估和选择的重要指导原则。
3. **模型容量与过拟合**
- 模型容量描述了模型拟合复杂函数的能力。过拟合和欠拟合可以通过调整模型容量来控制。在实际操作中,需要找到一个平衡,避免过度复杂导致过拟合,也不要过于简单造成欠拟合。对于不同类型的模型,如二次模型,随着训练样本数量的增加,训练误差会先下降后上升,测试误差则可能趋于稳定,直到达到最优容量。
4. **训练样本数量与模型复杂度的关系**
- 当训练样本不足时,模型的容量受限,可能导致过拟合。随着样本量增加,模型能更好地适应训练数据,但一旦超过最优容量,继续增加样本只会增加对噪声的敏感性。训练集大小和模型复杂度有密切关系,随着训练集增大,最优模型容量也会相应提升,但达到一定程度后不会进一步增长。
正则化是一种重要的技术,通过限制模型的复杂度来防止过拟合,确保模型具有良好的泛化能力。理解和掌握过拟合、欠拟合、独立同分布假设以及模型容量与训练样本数量的关系,是优化机器学习模型的关键步骤。在实际应用中,需要根据问题的具体情况进行选择和调整,以达到最佳的性能。
正则化输入
一、过拟合问题
1.欠拟合与过拟合
泛化能力:在先前为观测到的输入数据上表现良好的能力
过拟合:将训练样本的一些特有的特点也当作潜在样本的一般性质,进而导致泛化能
力下降。
欠拟合:训练样本性质没有学习完全,进而导致泛化能力较低。
决定机器学习算法效果的两个因素:
降低训练误差(对应欠拟合)
缩小训练误差和测试误差的差距(对应过拟合)
补充:欠拟合是指模型不能在训练集上获得足够低的误差,而过拟合是指训练误差和
测试误差之间的差距太大
2.独立同分布假设
训练集和测试集数据通过数据集上被称为数据生成过程的概率分布生成,假设每个数
据集中的样本都彼此相互独立,并且训练集和测试集都是同分布,采样自相同的分布,
我们将这个共享的潜在分布成为数据生成分布,即为 pdata,这就是独立同分布假设,
这使得我们能够用单个样本的概率分布表述数据生成过程。
在独立同分布的夹设下,训练样本的误差等于潜在样本的无查,只需要尽可能降低训
练无查即可。(实际上假设基本不能成立,而并不影响使用该假设)
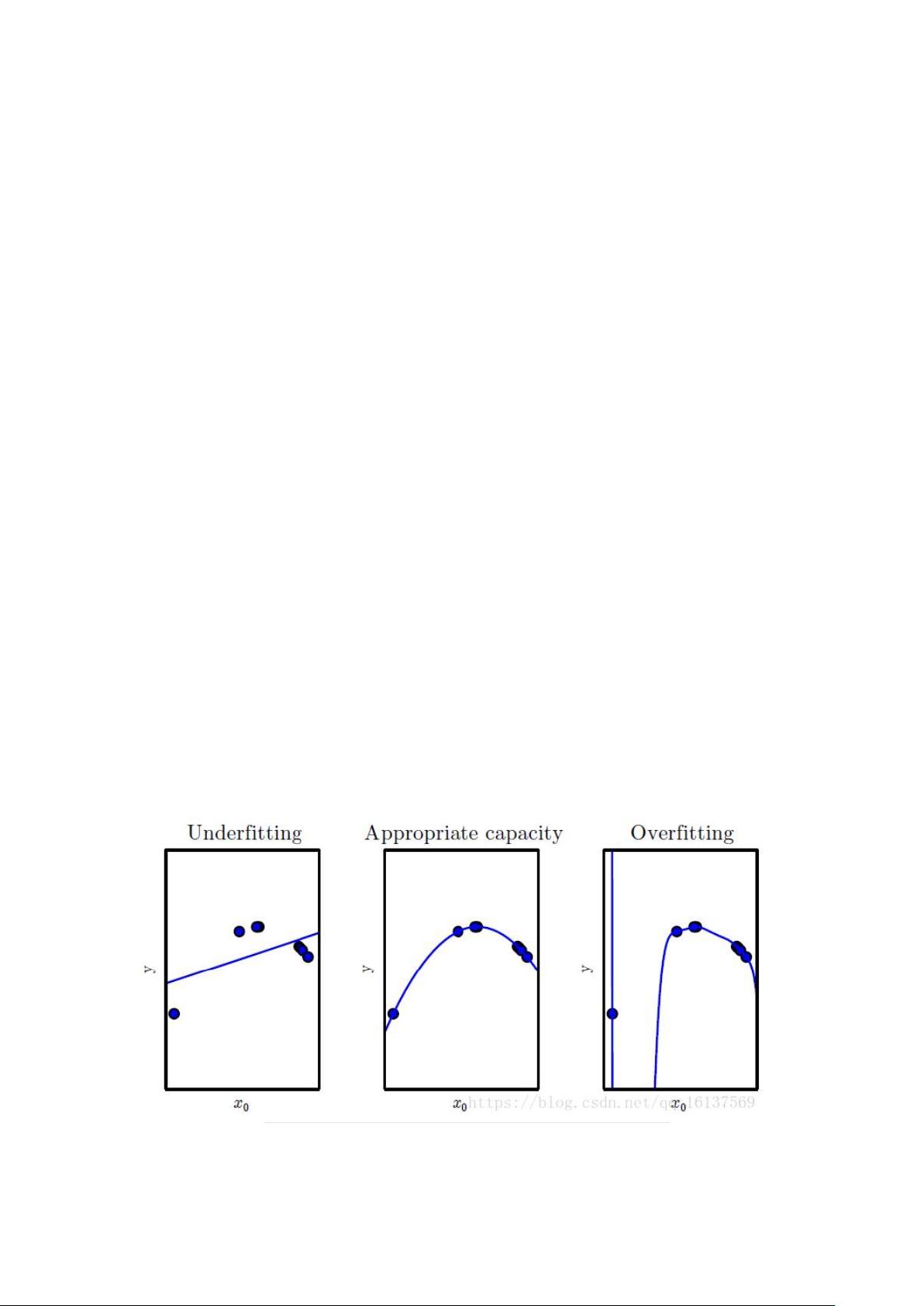
3.模型容量与过拟合
模型容量:指其拟合各种函数的能力。
我们可以通过调整模型的容量,控制模型是否偏向于过拟合与欠拟合。
过拟合、适当拟合、欠拟合:
容量与误差之间典型关系:
下载后可阅读完整内容,剩余7页未读,立即下载
2021-09-29 上传
2022-07-14 上传
222 浏览量
2023-05-11 上传
2024-03-31 上传
2023-10-19 上传
2023-09-13 上传
2023-06-08 上传
2023-09-21 上传

内酷少女
- 粉丝: 16
- 资源: 302
 我的内容管理
展开
我的内容管理
展开







最新资源
- 单片机串口通信仿真与代码实现详解
- LVGL GUI-Guider工具:设计并仿真LVGL界面
- Unity3D魔幻风格游戏UI界面与按钮图标素材详解
- MFC VC++实现串口温度数据显示源代码分析
- JEE培训项目:jee-todolist深度解析
- 74LS138译码器在单片机应用中的实现方法
- Android平台的动物象棋游戏应用开发
- C++系统测试项目:毕业设计与课程实践指南
- WZYAVPlayer:一个适用于iOS的视频播放控件
- ASP实现校园学生信息在线管理系统设计与实践
- 使用node-webkit和AngularJS打造跨平台桌面应用
- C#实现递归绘制圆形的探索
- C++语言项目开发:烟花效果动画实现
- 高效子网掩码计算器:网络工具中的必备应用
- 用Django构建个人博客网站的学习之旅
- SpringBoot微服务搭建与Spring Cloud实践
