MySQL全文索引、联合索引与like/json查询速度对比实测
版权申诉
101 浏览量
更新于2024-09-12
收藏 1.04MB PDF 举报
本文将深入探讨MySQL中的四种查询方法:全文索引、联合索引、LIKE查询和JSON查询在处理大量数据时的速度表现。具体案例中,作者使用了一个名为`tmp_test_course`的表,该表约有10万条记录,其中`outline`字段存储了一对多的关系,包括一系列编码。目标是查找类型为5,已删除且为叶子节点的记录,并在`outline`中匹配给定的多个编码,例如jy1577683381775等。
首先,作者通过LIKE查询进行测试,这种方法使用通配符匹配字符串,查询时间为248毫秒,扫描了相当数量的行以找到匹配项。LIKE查询可能会因为模式匹配的复杂性而导致性能下降,尤其是在大数据集上,因为它需要全表扫描。
接下来,文章会对比使用联合索引的方法,通常情况下,联合索引能提高查询效率,因为它允许数据库系统通过单个索引来定位多个列的组合值。然而,对于本文的情况,由于查询条件中的`outline`字段是JSON类型的,可能无法直接利用到传统的联合索引优化。
针对JSON查询,MySQL提供了对JSON字段的操作,但在这个场景下,由于`outline`是编码集合而非嵌套结构,可能并不适用直接的JSON操作来加速查询。如果`outline`字段被设计为JSON对象,JSON路径查询或函数(如JSON_EXTRACT())可能会更合适。
最后,文章可能会提到全文索引(Full-Text Indexing, FTS)作为另一种可能的解决方案。全文索引特别适合于全文本搜索,能够快速查找包含特定关键词的文本字段,但是否在本文场景中建立全文索引取决于`outline`字段是否主要用于全文搜索,以及MySQL的FTS特性支持程度。
通过对这四种查询方式的详细分析,读者将了解在特定条件下,MySQL如何选择最有效的查询策略来优化查询性能,特别是在处理大量数据和复杂查询时。对于需要处理类似场景的数据库管理员和开发人员,本文提供了宝贵的实际经验和优化技巧。
MySQL全文索引、联合索引、全文索引、联合索引、like查询、查询、json查询速度哪个快查询速度哪个快
主要介绍了MySQL全文索引、联合索引、like查询、json查询速度大比拼,通过实例代码截图的形式给大家介绍的非常详细,具有一定的参考借鉴价值,需要的朋友可以参考下
查询背景查询背景
有一个表tmp_test_course大概有10万条记录,然后有个json字段叫outline,存了一对多关系(保存了多个编码,例如jy1577683381775)
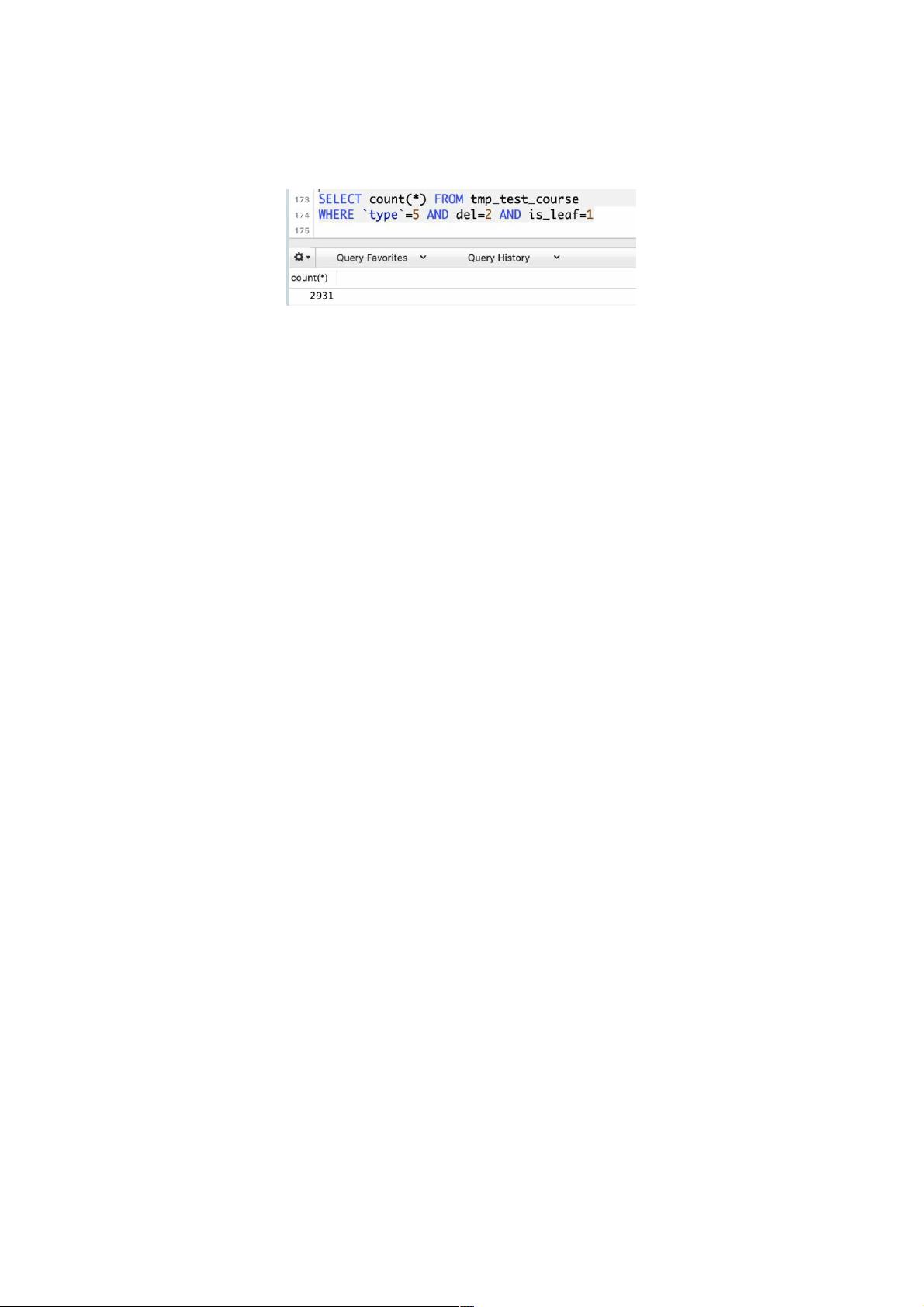
我们需要在这10万条数据中检索特定类型的数据,目标总数据量:2931条
SELECT COUNT(*) FROM tmp_test_course WHERE `type`=5 AND del=2 AND is_leaf=1
我们在限定为上面类型的同时,还得包含下面任意一个编码(也就是OR查询)
jy1577683381775
jy1577683380808
jy1577683379178
jy1577683378676
jy1577683377617
jy1577683376672
jy1577683375903
jy1578385720787
jy1499916986208
jy1499917112460
jy1499917093400
jy1499917335579
jy1499917334770
jy1499917333339
jy1499917331557
jy1499917330833
jy1499917329615
jy1499917328496
jy1576922006950
jy1499916993558
jy1499916992308
jy1499917003454
jy1499917002952
下面分别列出4种方式查询outline字段,给出相应的查询时间和扫描行数
一、一、like查询查询
耗时248毫秒
SELECT * FROM tmp_test_course
WHERE `type`=5 AND del=2 AND is_leaf=1
AND (
outline like '%jy1577683381775%'
OR outline like '%jy1577683380808%'
OR outline like '%jy1577683379178%'
OR outline like '%jy1577683378676%'
OR outline like '%jy1577683377617%'
OR outline like '%jy1577683376672%'
OR outline like '%jy1577683375903%'
OR outline like '%jy1578385720787%'
OR outline like '%jy1499916986208%'
OR outline like '%jy1499917112460%'
OR outline like '%jy1499917093400%'
OR outline like '%jy1499917335579%'
OR outline like '%jy1499917334770%'
OR outline like '%jy1499917333339%'
OR outline like '%jy1499917331557%'
OR outline like '%jy1499917330833%'
OR outline like '%jy1499917329615%'
OR outline like '%jy1499917328496%'
OR outline like '%jy1576922006950%'
OR outline like '%jy1499916993558%'
OR outline like '%jy1499916992308%'
OR outline like '%jy1499917003454%'
OR outline like '%jy1499917002952%'
)
下载后可阅读完整内容,剩余4页未读,立即下载
2020-12-15 上传
2020-09-09 上传
2020-09-09 上传
点击了解资源详情
2020-12-14 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情

weixin_38733676
- 粉丝: 5
- 资源: 915
 我的内容管理
展开
我的内容管理
展开







最新资源
- 基于Matlab/ Simulink 的雷达系统仿真
- 电子商务论文(chiana-pub与华储网的对比分析)
- 数据库设计漫谈-数据库的规范与技巧
- MIMO雷达正交频分LFM信号设计及性能分析
- IE注册表设置安全项
- matlab builder for dotnet User's Guide
- Maven权威指南中文版.pdf
- Linux0从硬盘安装Linux
- at89s52中文资料
- 程序员的SQL金典,从入门到精通
- GridView的相关技术
- 一片关于用OPNET无线建模的文章
- 三层交换机配置实例里面含有代码
- SQL语句基本语法 sql语句的基本语法
- js面向对象高级编程-电子书(pdf格式)
- Unix toolbox
