深入理解Spark Structured Streaming
需积分: 17 16 浏览量
更新于2024-07-19
收藏 1.37MB PDF 举报
"Spark Streaming是Apache Spark项目中的一个模块,用于处理实时数据流。它提供了一个高级抽象,允许开发者以类似批处理的方式编写流处理应用程序,从而实现高吞吐量和容错性。随着Spark的发展,Structured Streaming在Spark 2.2及以后的版本中成为了更推荐的流处理模型,它提供了更加结构化的编程接口,取代了RDD(弹性分布式数据集)作为流处理的基础抽象。尽管在Spark 2.1中Structured Streaming仍处于实验阶段,但其稳定性和功能已经得到了显著提升。
Structured Streaming的核心概念是持续查询(Continuous Query),这种查询会在数据流入时不断运行,直到被显式停止。相比于传统的基于微批次的Spark Streaming,Structured Streaming提供了更强大的保证,比如精确一次(Exactly Once)的语义,以及对延迟数据的处理能力。
在Spark Streaming中,数据流处理分为输入和输出两个主要部分。使用`read.stream()`函数可以从各种数据源读取数据流,如Socket、Kafka、Flume、HDFS等。而`write.stream()`函数则用于将处理后的数据写入到目标位置,常见的输出格式有JSON、Parquet、CSV等。`format()`函数用于指定数据源或数据目标的格式,`outputMode()`则定义了如何处理输出数据,例如全量更新(Complete)、增量更新(Append)或更新差分(Update)。
Structured Streaming支持多种操作,包括窗口操作和时间滑动,这对于处理时间序列数据非常有用。窗口操作允许我们在特定时间间隔内聚合数据,而时间滑动则可以处理迟到的数据。此外,Structured Streaming还能与静态数据集进行连接,使得实时流数据可以与历史数据进行交互分析。
在实际应用中,Structured Streaming的动手实验室通常会涵盖以下内容:
1. 使用Socket数据源和HDFS数据源进行数据读取。
2. 学习窗口流处理以及Spark如何处理延迟数据。
3. 实现静态视图与动态视图的连接,结合实时和静态数据进行分析。
通过这些实践,开发者能够深入理解Structured Streaming的工作原理,以及如何利用其特性构建高效、可靠的实时数据处理系统。"
Hadoop Decoded – Spark Project
Page 11
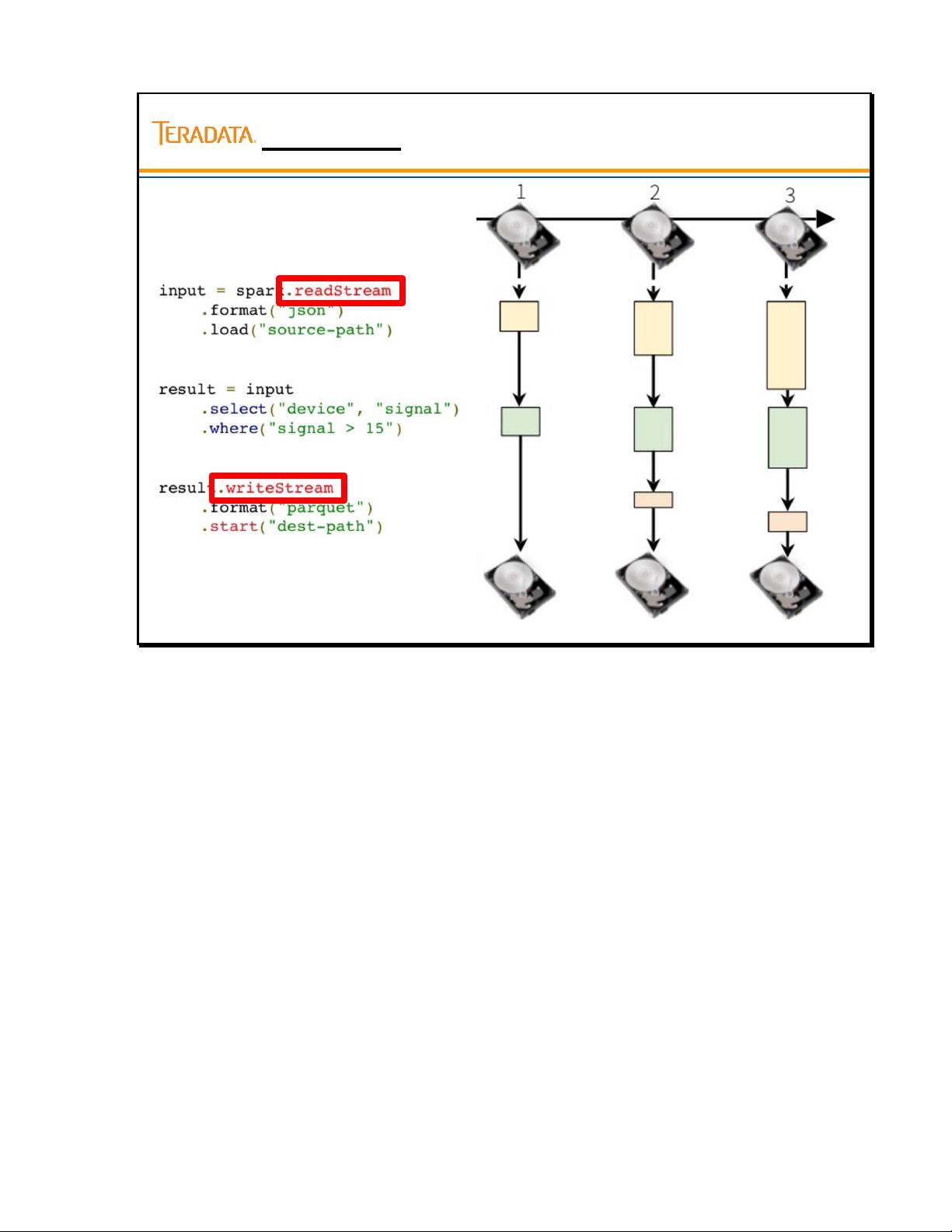
Streaming ETL with DataFrames (generic)
Replace write with writeStream
Replace save() with start()
Write to Parquet
Replace write with writeStream
Replace save() with start()
writeSteam…start() defines where/how to output
data source and starts processing
Read from JOINS file stream
Replace read with readStream
readStream…load() creates Streaming DF
Does not start any computations
SELECT some data
Code does not change from Batch
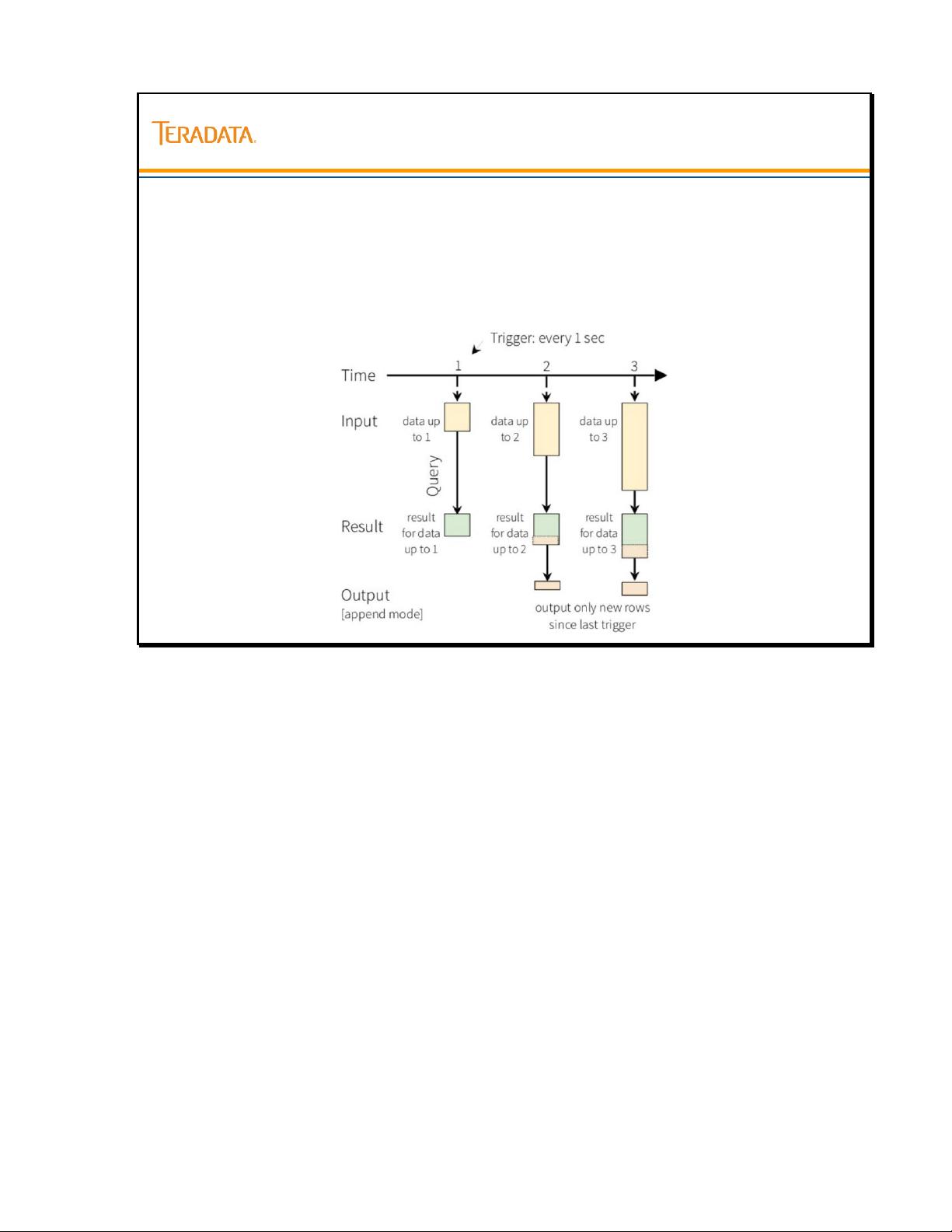
New rows in
result of 2
New rows in
result of 3

剩余62页未读,继续阅读
2021-05-31 上传
2019-05-09 上传
2021-07-07 上传
2018-04-28 上传
2016-01-14 上传
2023-04-23 上传
2023-03-16 上传
2022-03-24 上传

li12345bukeneng
- 粉丝: 0
- 资源: 14
 我的内容管理
展开
我的内容管理
展开







最新资源
- project-
- javaStudy
- PSP Tools package-开源
- cfdi-files-ws:从 CFDI 文档生成文件的 Web 服务
- Yet Another Web Server-开源
- AMQPStorm-2.2.1-py2.py3-none-any.whl.zip
- uptimes:El Eliyar Eziz的正常运行时间监控器和状态页面,由@upptime提供支持
- Test_LDPC (2).zip
- grunt-generate-config
- VC++基于mfc71.dll渐变变色按钮
- recaptcha:适用于Laravel的Google ReCaptcha V3软件包
- 电子功用-基于IEC标准的家用电器输入功率测试方法及装置
- visual studio2022已经编译好的ceres库
- 一键部署kubernetes1.18版本
- Pomodoro
- 基于HTML的移动网页布局--携程网.zip
