使用LEX构建C语言词法分析器
版权申诉
"基于LEX的C语言词法分析器文档提供了关于使用LEX工具构建C语言词法分析器的详细过程和设计思路。实验旨在使学习者掌握编译原理的基础理论,了解编译程序的结构,以及词法分析的基本概念和实现方法。文档中详细介绍了LEX输入文件的构成,包括定义集、规则集和辅助程序集,并给出了正则表达式的定义及在LEX中的实现方式。此外,还具体展示了如何定义和处理C语言中的保留字、数字和特殊符号。"
在编译原理中,词法分析是编译器前端的一个关键步骤,它负责将源代码分解成一个个称为Token的最小语法单元。在这个基于LEX的C语言词法分析器中,主要目标是识别并生成C语言的Token,包括标识符(ID)、整数(NUM)、保留字(Keyword)、特殊符号(Specialsymbol)和空白字符(Whitespace)等。
LEX,也称为Flex,是一个广泛使用的词法分析器生成器,它根据用户提供的正则表达式定义,自动生成词法分析器的C代码。LEX输入文件通常分为三部分:
1. **定义集**(Definitions):这部分包含C语言的代码和函数定义,用于定义正则表达式,如标识符ID、数字NUM、字母Letter和数字Digit等。
2. **规则集**(Rules):这一部分列出各种正则表达式的匹配规则,当匹配成功时,会执行相应的C代码块。
3. **辅助程序集**(Auxiliary Routines):这部分可以包含用户自定义的C函数,供词法分析器在处理过程中调用。
在给出的示例中,LEX文件定义了如下的正则表达式:
- ID: 匹配C语言的标识符,由字母、数字或下划线组成。
- NUM: 匹配整数,由一个或多个数字组成。
- Letter 和 Digit: 分别表示字母和数字的字符类。
- Keyword: 列出了一些常见的C语言保留字。
- Specialsymbol: 包含各种运算符和分隔符。
- Whitespace 和 Enter: 分别表示空白字符和换行符。
在规则定义部分,文档展示了如何处理匹配到的保留字、数字和特殊符号。例如,当遇到保留字时,会调用特定的函数输出相关信息;遇到数字时,同样会输出对应的Token类型。
通过这样的设计,词法分析器可以逐字符读取源代码,识别出符合规则的Token序列,为后续的语法分析和语义分析提供基础。这对于理解和编写编译器,或者对编译过程有深入需求的开发者来说,是非常重要的知识和技能。掌握LEX工具的使用,能够帮助开发者更高效地实现词法分析阶段的功能。
for(i=0;i<l;i++){
s[i]=toupper(s[i]);
}
}//将保留字变为大写
//主函数
main(void)
{
//定义输入文件名变量
char infilename[400];
printf("输入文件名:");
scanf("%s",&infilename);
yyin = fopen(infilename,"r");//读取文件
printf("开始词法分析: \n");
return yylex();
}
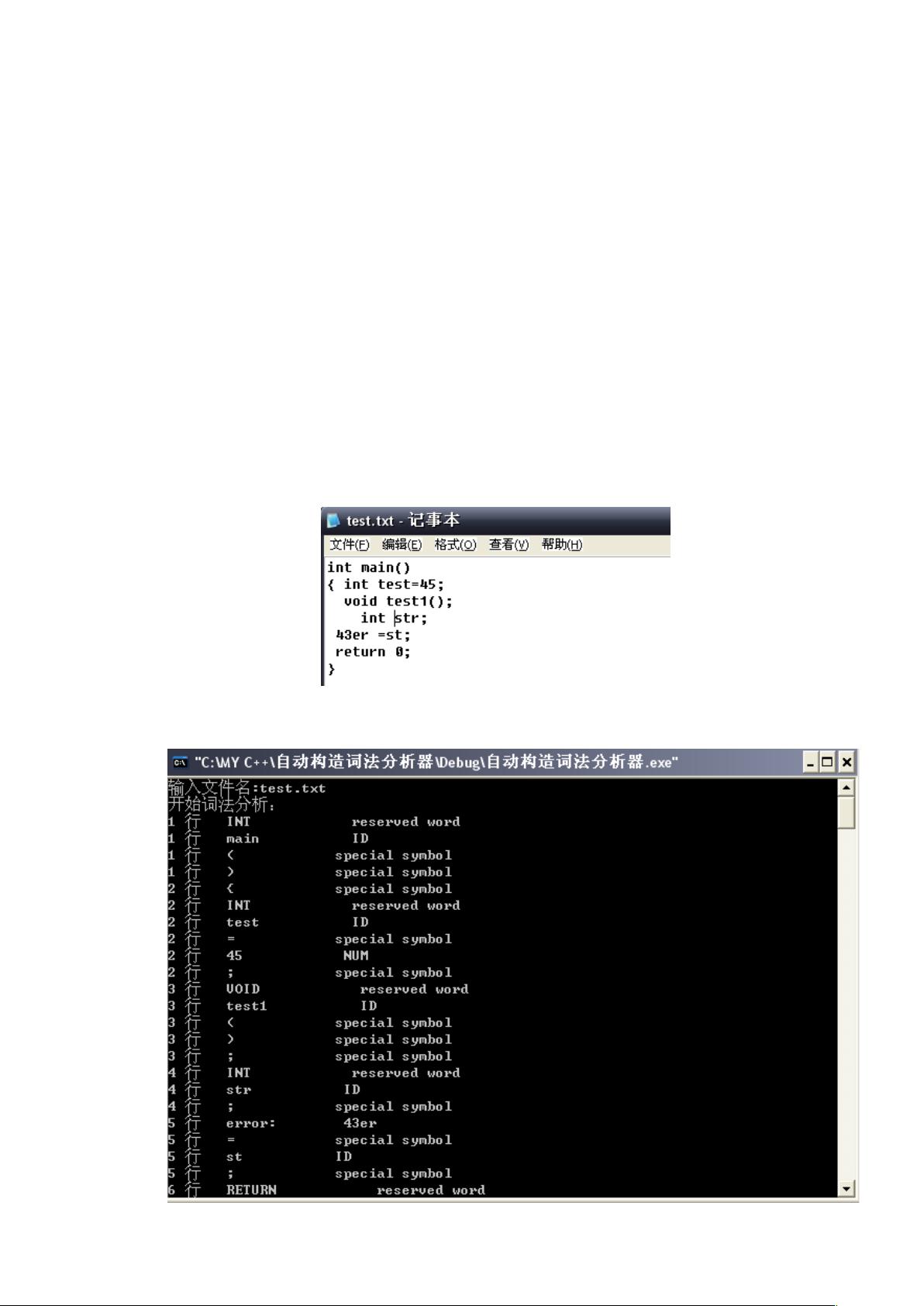
4. 测试结果
测试数据选择
测试的文件代码
测试结果分析
5. 总结
剩余19页未读,继续阅读
2016-06-23 上传
2010-05-23 上传
2022-07-03 上传
2009-11-12 上传
2022-07-03 上传
2021-12-05 上传
2021-09-16 上传
点击了解资源详情

猫一样的女子245
- 粉丝: 230
- 资源: 2万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- Angular程序高效加载与展示海量Excel数据技巧
- Argos客户端开发流程及Vue配置指南
- 基于源码的PHP Webshell审查工具介绍
- Mina任务部署Rpush教程与实践指南
- 密歇根大学主题新标签页壁纸与多功能扩展
- Golang编程入门:基础代码学习教程
- Aplysia吸引子分析MATLAB代码套件解读
- 程序性竞争问题解决实践指南
- lyra: Rust语言实现的特征提取POC功能
- Chrome扩展:NBA全明星新标签壁纸
- 探索通用Lisp用户空间文件系统clufs_0.7
- dheap: Haxe实现的高效D-ary堆算法
- 利用BladeRF实现简易VNA频率响应分析工具
- 深度解析Amazon SQS在C#中的应用实践
- 正义联盟计划管理系统:udemy-heroes-demo-09
- JavaScript语法jsonpointer替代实现介绍
