"百度运维部实战:大规模时序指标异常检测算法-《藏经阁》详解"
需积分: 0 192 浏览量
更新于2024-01-01
收藏 5.28MB PDF 举报
"藏经阁-百度大规模时序指标自动异常检测实战.pdf" 是一篇由百度运维部的王博撰写的技术文档,讲述了关于大规模时序指标自动异常检测的实战经验和技巧。本文全面介绍了该系统的背景、架构和通用的异常检测算法,特别关注选择决策树算法作为处理时序数据异常的一种有效方法。
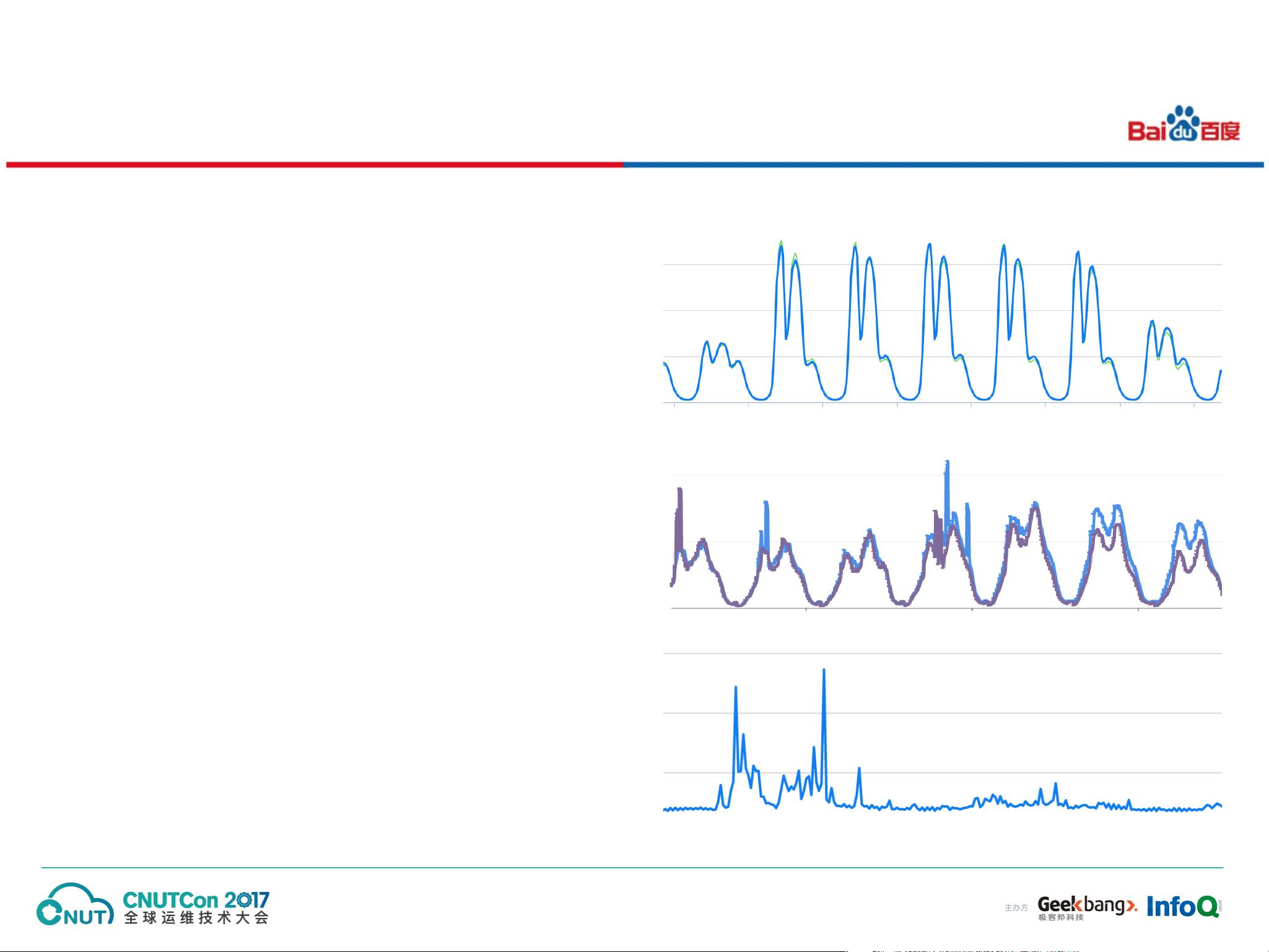
在背景介绍部分,作者提到了大规模系统中的时序数据异常检测的重要性。时序数据是指按照时间先后顺序排列的数据集合,包括网络负载、服务器性能、用户行为等。这种数据异常的检测对于保证系统的稳定性和性能至关重要。然后,作者简要介绍了百度运维部作为百度搜索引擎的运营支持机构,其对时序数据异常检测的需求和挑战。
接下来,作者详细介绍了系统的架构。该架构包括数据采集、预处理、特征提取和异常检测四个主要模块。数据采集模块负责收集大规模时序数据。预处理模块用于对原始数据进行预处理,包括去噪、缺失值处理和平滑等步骤。特征提取模块通过对预处理后的数据进行加工和转换,提取出关键特征供后续的异常检测使用。异常检测模块使用决策树算法来检测异常。作者还详细介绍了每个模块的具体实现和关键技术。
在通用的异常检测算法部分,作者提到了决策树算法是一种常用的机器学习方法,广泛应用于分类和回归问题。作者介绍了决策树的基本原理和构建过程,以及如何将其应用于时序数据异常检测。作者指出决策树算法具有直观易解释、计算效率高和对异常数据具有较好的适应性等优点。
最后,作者讨论了在选择决策树算法时需要考虑的关键因素,并提供了一些建议和经验。作者建议在选择决策树算法时应考虑数据集的大小、特征的数量和关联性、算法的可解释性以及计算资源的要求。通过实例分析,作者展示了如何优化和调整决策树的参数以提高异常检测的准确性和效率。
总而言之,"藏经阁-百度大规模时序指标自动异常检测实战.pdf" 是一篇详细介绍了大规模时序数据异常检测系统的实战经验和技巧的技术文档。该文档内容丰富,包括系统的背景、架构和通用的异常检测算法。特别关注了决策树算法作为解决时序数据异常的有效工具,并提供了选择和优化决策树算法的建议和经验。这篇文章对于对大规模时序数据异常检测感兴趣或从事相关工作的人员具有很大的参考价值。

背景介绍
系统架构
通用z景的异常检测算法
算法选择决策树&i数自c配置算法
总结与展望
剩余25页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2023-09-11 上传
2023-09-09 上传
2023-09-01 上传
2023-08-27 上传

weixin_40191861_zj
- 粉丝: 87
- 资源: 1万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- toggle-icon:toggle-icon是使用Polymer创建的自定义元素。 它提供了一个功能强大且可自定义的开关,看起来像一个纸质图标按钮
- 电子商务商店:电子商务商店
- 【Java毕业设计】这是使用java ee ,tomcat,jsp,Oracle 开发的毕业设计双向选题系统.zip
- Resume
- tidy_project
- Android 9妹工具(9Patch).zip
- nuxeo-web-ui:新的Nuxeo Web UI
- 基于QT+FFmpeg+dxva2硬解码的,音视频播放软件,同时也支持播放url,本机摄像头等
- 蒂尔:今天我学到了
- practice_exercises
- canvasboard-backend:基于NodeJS的Canvasboard Backend
- 第17章 数据统计和分析.rar
- files
- GolompServer
- ARC_Alkali_Rydberg_Calculator-2.2.10-cp37-cp37m-win32.whl.zip
- 云杉:Minecraft资源包
