
ISPRS Int. J. Geo-Inf. 2020, 9, 242 5 of 21
1
2
3
4
5
0
1
2
3
4
BN-ReLu
-Conv
BN-ReLu
-Conv
BN-ReLu
-Conv
BN-ReLu
-Conv
Transition Layer
Input
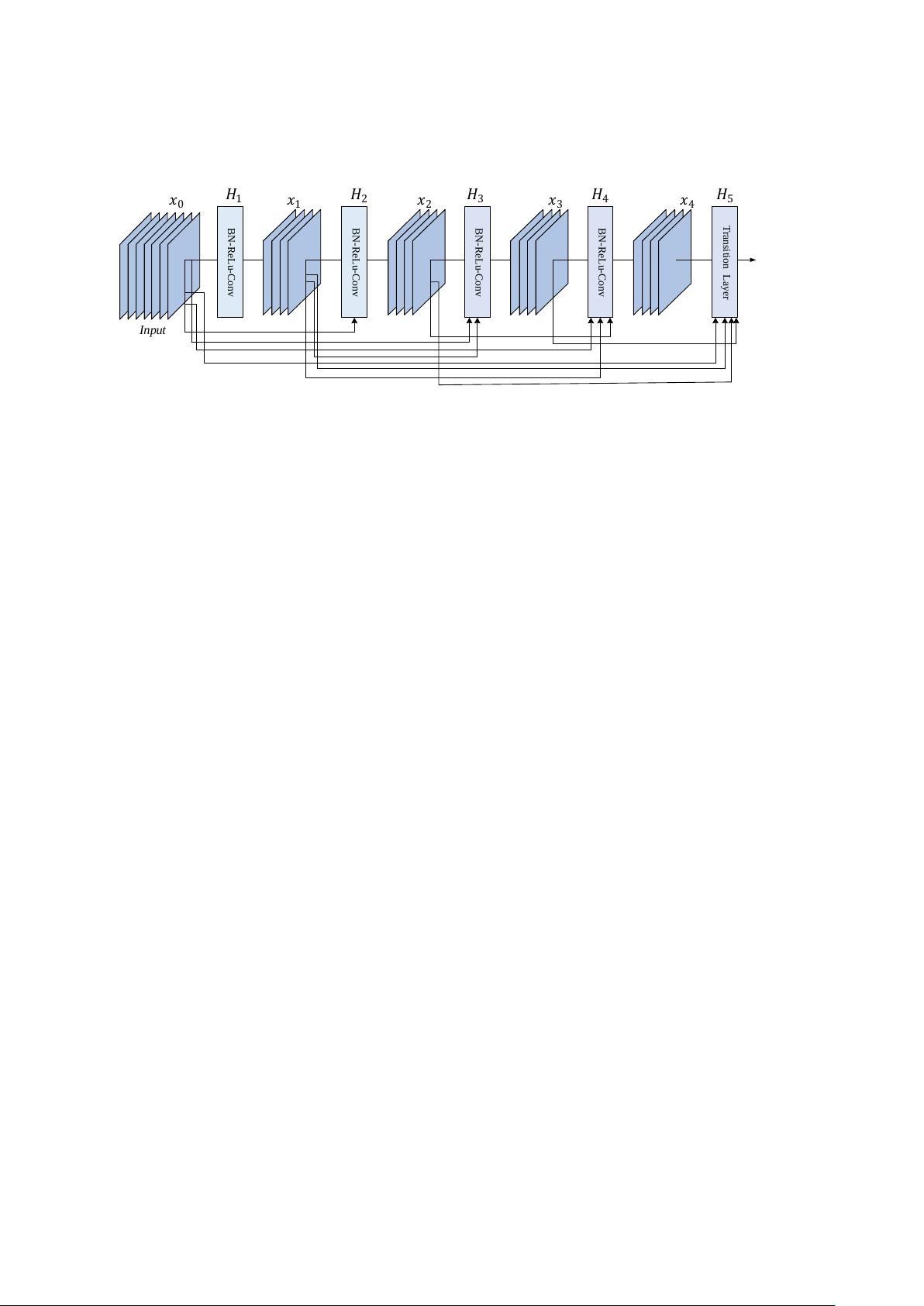
Figure 1.
A five-layer dense block with a growth rate of
k =
4. All preceding feature-maps are the
input data of each layer.
In a dense block, the feature map
x
l
of the
l
th
layer can be achieved from the feature maps
x
0
, x
1
, ..., x
l−1
, which is calculated and expressed as follows:
x
l
= H
l
([x
0
, x
1
, ..., x
l−1
]) (1)
where
x
0
, ...,
x
l−1
are the result of tensor stitching of feature maps from the zeroth layer to the
(l −
1
)
th
layer, which are the input data of the
l
th
layer. The standard
H
l
(
.
)
is a compound function consisting of
three successive operations: BN, ReLU, and the convolution kernel with a size of 3
×
3. Each function
H
l
(
.
)
outputs kfeature maps, so there are
k(l −
1
) + k
0
input feature maps in the
l
th
layer, where
k
0
is the channel number of the first input layer. In order to control the width of the network and
improve the efficiency of the parameters,
k
is generally limited to a smaller integer. This control of the
growth rate can not only reduce the parameters of the DenseNet, but also ensure the performance of
the DenseNet.
In addition, although each layer only outputs feature maps, a large amount of feature maps
(
k(l −
1
) + k
0
) is the input data of each layer. To solve this problem, a bottleneck layer is added to
the DenseNet architecture. That is to say, a 1
×
1 convolution operation is introduced before each
3
×
3 convolution operation to reduce the dimension. This network architecture with bottleneck
layers is called DenseNet-B. At the same time, for simplifying the architecture, a compression factor
θ
(0
≤ θ ≤
1) can be added in the transition layer to decrease the output of the feature maps. If the
output of the dense blocks includes feature maps, the subsequent transition layer will output
θ ∗ m
feature maps.
θ =
1 indicates that the number of feature maps passing through the transition layer
remains unchanged. The network architecture containing the compression factor is called DenseNet-C.
The network architecture including the bottleneck layer and compression factor is called DenseNet-BC.
DenseNet-BC uses the bottleneck layer and the compression factor to narrow the network and reduce
the network parameters, effectively suppressing over-fitting. Moreover, the experimental results show
that DenseNet-BC using the bottleneck layer and compression factor can obtain a better fused image
than DenseNet.
3. Methodology
Some studies have demonstrated that deeper CNN architectures can extract more feature
information, but with the deepening of the network architecture, training will become increasingly
difficult. In view of the particularities of pan-sharpening, more feature information needs to be
extracted to ensure the preservation of spectral information and the enhancement of spatial resolution.
Therefore, a new pan-sharpening method is proposed in this paper that employs the advantages of
DenseNet to mitigate gradient disappearance, improve feature propagation, and promote feature reuse.
In this way, the fused image can retain the original image spectrum information and enhance its spatial
剩余20页未读,继续阅读

weixin_38687928
- 粉丝: 2
- 资源: 950
 我的内容管理
展开
我的内容管理
展开







最新资源
- zlib-1.2.12压缩包解析与技术要点
- 微信小程序滑动选项卡源码模版发布
- Unity虚拟人物唇同步插件Oculus Lipsync介绍
- Nginx 1.18.0版本WinSW自动安装与管理指南
- Java Swing和JDBC实现的ATM系统源码解析
- 掌握Spark Streaming与Maven集成的分布式大数据处理
- 深入学习推荐系统:教程、案例与项目实践
- Web开发者必备的取色工具软件介绍
- C语言实现李春葆数据结构实验程序
- 超市管理系统开发:asp+SQL Server 2005实战
- Redis伪集群搭建教程与实践
- 掌握网络活动细节:Wireshark v3.6.3网络嗅探工具详解
- 全面掌握美赛:建模、分析与编程实现教程
- Java图书馆系统完整项目源码及SQL文件解析
- PCtoLCD2002软件:高效图片和字符取模转换
- Java开发的体育赛事在线购票系统源码分析
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


