Scrapy框架入门与爬虫实践教程
下载需积分: 17 | DOCX格式 | 39KB |
更新于2024-09-10
| 115 浏览量 | 举报
"Scrapy框架教程详解"
Scrapy是一个强大的Python网络爬虫框架,专为高效地爬取网站数据而设计。它提供了一种结构化的方式,使得编写爬虫变得更加简单和灵活。在本教程中,我们将深入理解Scrapy的基本框架,并通过实例学习如何创建、配置和运行一个爬虫。
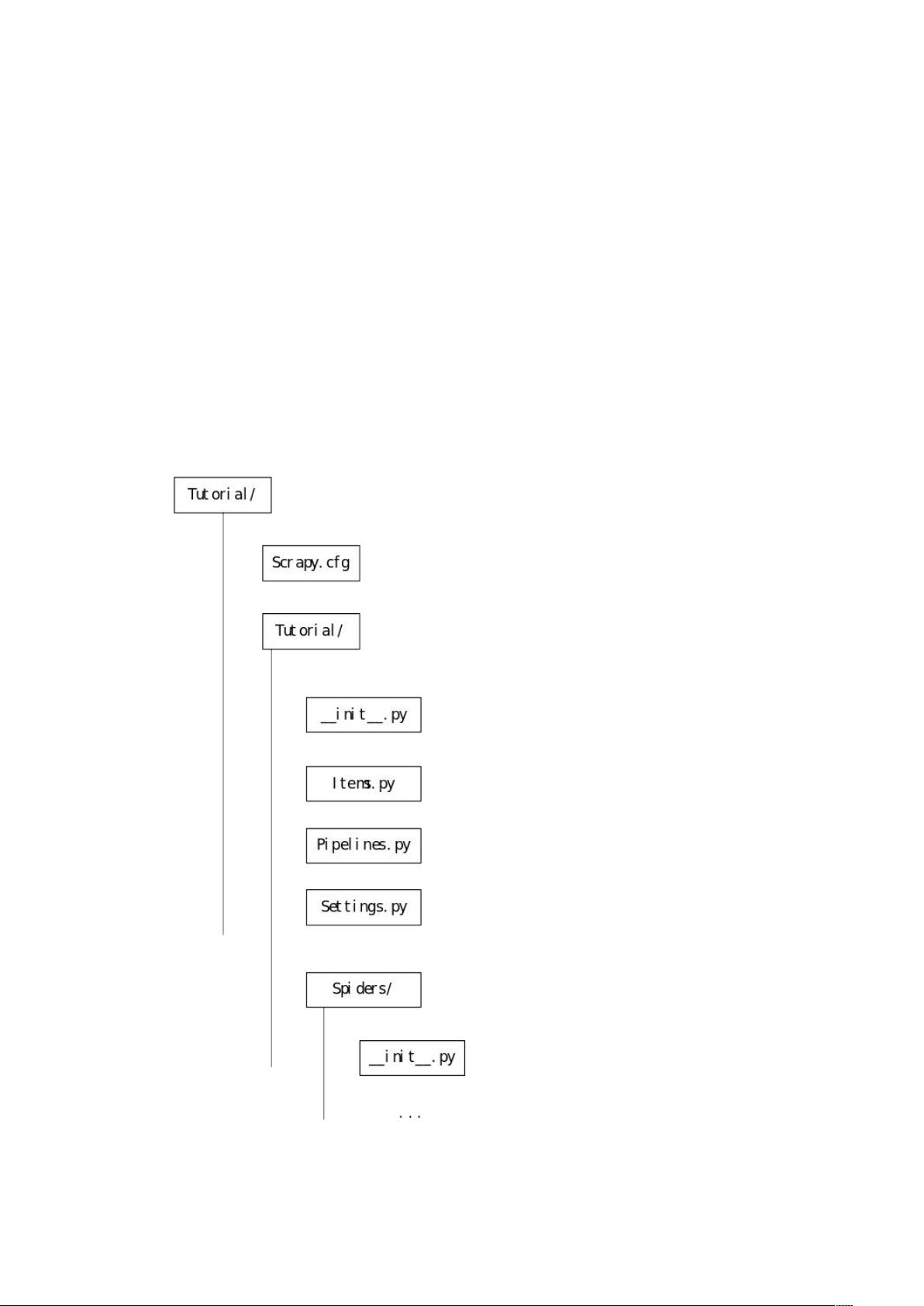
首先,要开始使用Scrapy,你需要在命令行中安装它,通常使用pip install scrapy命令。然后,创建一个新的Scrapy项目是一个重要的步骤。通过运行`scrapy startproject Tutorial`,你会得到一个名为"Turorial"的项目模板,其中包含几个关键文件:
1. `Scrapy.cfg`:这是项目的配置文件,用于设置全局配置,如下载延迟、代理等。你需要根据项目需求自定义这些设置。
2. `spiders`目录:存放每个特定爬虫的Python类文件。例如,一个名为"DmozSpider"的爬虫可能如下所示:
```python
from scrapy.spiders import BaseSpider
class DmozSpider(BaseSpider):
name = "dmoz" # 必须为每个spider设置唯一的name
allowed_domains = ["dmoz.org"] # 爬虫允许访问的域名
start_urls = [
"http://www.dmoz.org/Computers/Programming/Languages/Python/Books/",
"http://www.dmoz.org/Computers/Programming/Languages/Python/Resources/"
] # 开始抓取的URL列表
def parse(self, response): # 默认回调函数,处理抓取的页面
filename = response.url.split("/")[-2] # 获取文件名
open(filename, 'wb').write(response.body) # 将网页内容保存到本地文件
```
`name`属性确保每个spider有唯一的标识,`start_urls`定义了爬虫的起点。`parse`方法是每个spider的入口点,当接收到一个新的URL时,Scrapy会自动调用这个方法。
运行爬虫是通过在项目目录下执行`scrapy crawl dmoz`命令,这里传入的是spider的名字(在这个例子中是'dmoz')。
Scrapy还提供了HTMLXPathSelector(HXS)或LXMLSelector等工具,帮助我们解析网页内容。例如,为了提取HTML元素,我们可以更新爬虫代码:
```python
from scrapy.spiders import BaseSpider
from scrapy.selector import HtmlXPathSelector
class DmozSpider(BaseSpider):
...
def parse(self, response):
hxs = HtmlXPathSelector(response)
books = hxs.select('//a[@href]')
for book in books:
title = book.select('text()').extract_first()
href = book.select('@href').extract_first()
yield {'title': title, 'url': href} # 提取并yield需要的数据
```
这段代码通过XPath表达式选取了所有带有链接的`<a>`标签,然后提取了链接文本和URL。
Scrapy框架通过分层架构,如Spiders、中间件、Item Pipelines等,使得爬虫开发变得模块化和可扩展。掌握Scrapy的基础后,你能够灵活处理各种复杂的网络抓取任务,为数据分析、数据挖掘和网站监控提供强大的支持。对于初学者来说,这是一个很好的起点,后续还可以学习更多高级特性如异步下载、分布式爬取等。
爬虫框架 scrapy 详解
生成一个项目
Scrapy startproject Turorial
生成项目类似如下结构
下载后可阅读完整内容,剩余7页未读,立即下载
相关推荐







yuedong111
- 粉丝: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- 嵌入式Linux:GUI编程入门与设备驱动开发详解
- iBATIS 2.0开发指南:SQL Maps详解与升级
- Log4J详解:组件、配置与关键操作
- 掌握MIDP与MSA手机编程实战指南
- 数据库设计:信息系统生命周期与DSDLC
- 微软工作流基础教程:2007年3月版
- Oracle PL/SQL语言第四版袖珍参考手册
- F#基础教程 - Robert Pickering著
- Java集合框架深度解析:Collection与Map接口
- C#编程:时间处理与字符串操作实用技巧
- C#编程规范:Pascal与Camel大小写的使用
- Linux环境下Oracle与WebLogic的配置及J2EE应用服务搭建
- Oracle数据库完整卸载指南
- 精通Google Guice:轻量级依赖注入框架实战
- SQL Server与Oracle:价格、性能及平台对比分析
- 二维数据可视化:等值带彩色填充算法优化
