Hive分桶表操作与数据仓库特性解析
需积分: 9 76 浏览量
更新于2024-07-16
收藏 1004KB PDF 举报
"离线-day10.pdf - 数据仓库与Hive表操作详解"
在IT行业中,数据仓库(Data Warehouse,DW或DWH)是至关重要的一个环节,它专注于为企业提供决策支持服务。数据仓库是一个面向分析的存储系统,旨在集成来自不同业务系统的数据,为分析和报告提供统一视图。其主要特征包括面向主题、集成性、非易失性和时变性。
面向主题意味着数据仓库围绕特定主题(如用户、订单、商品)组织,为这些主题的深度分析提供便利。集成性体现在数据仓库通过ETL(抽取、转换、加载)过程,将不同源的数据整合在一起,解决字段不一致等问题。非易失性则保证了数据仓库中的历史数据不会被覆盖或丢失,但会定期更新以反映最新的业务状况。时变性强调了数据仓库包含不同时间粒度的历史数据,用于分析过去的业务模式。
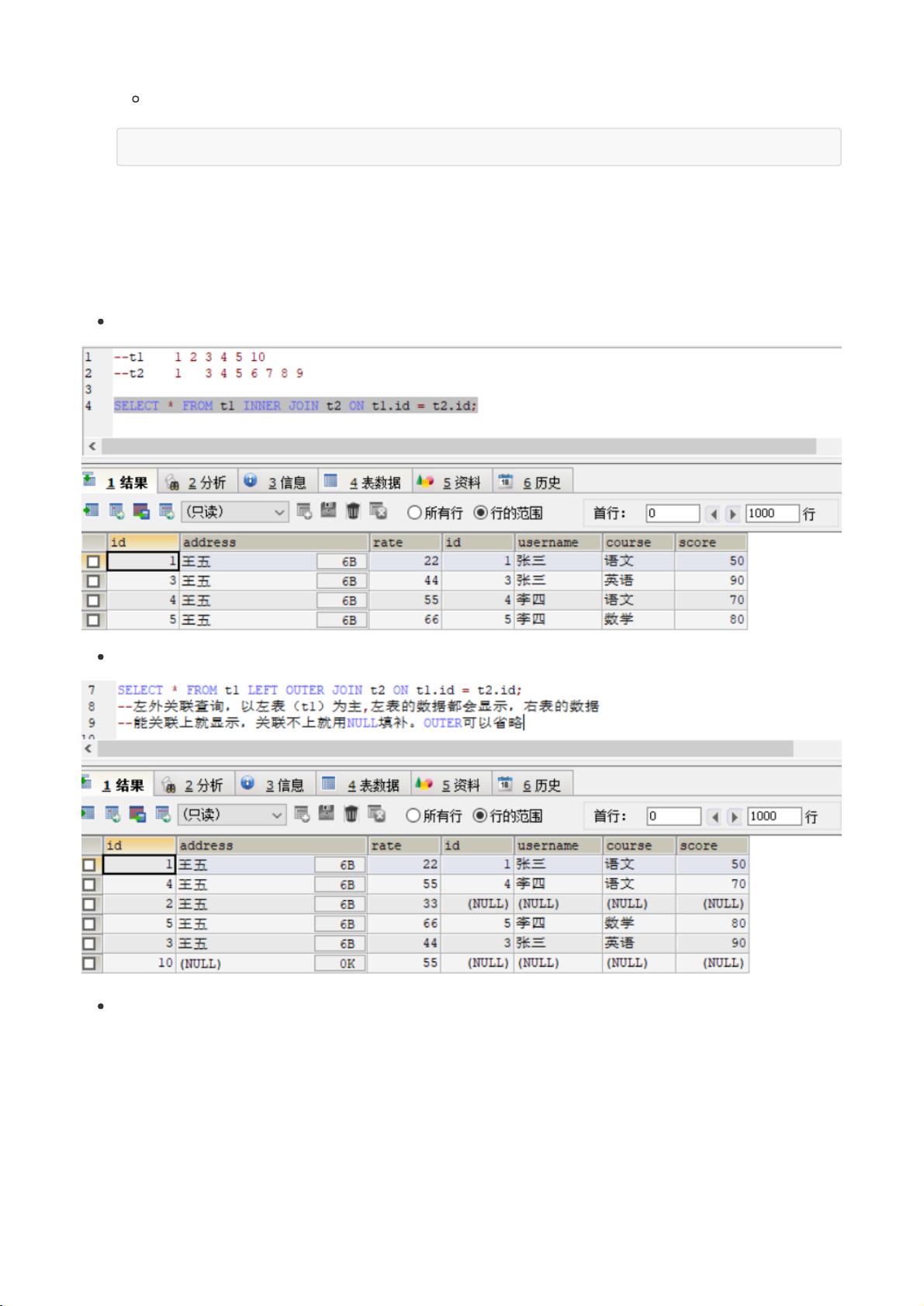
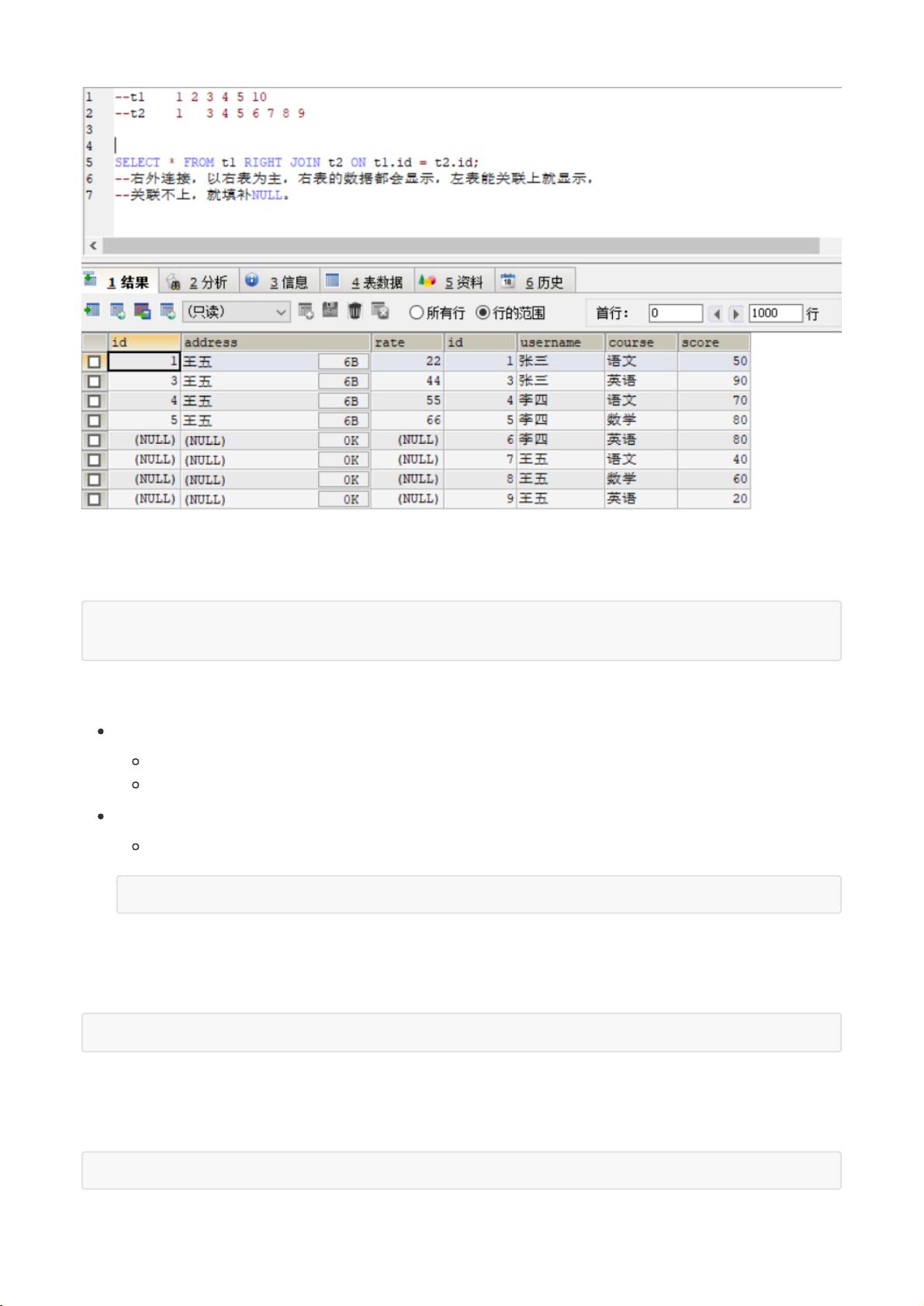
Hive是一个基于Hadoop的大数据处理工具,它的分桶功能进一步优化了数据存储和查询效率。分桶是根据指定字段将数据划分为多个文件,类似于MapReduce中的分区。创建Hive的分桶表需要通过`INSERT OVERWRITE`语句,并确保数据加载到桶表时遵循正确的字段值。分桶的一个关键好处是在进行特定类型的join操作时,可以利用分桶匹配减少数据处理量,提高性能。
修改Hive表结构包括重命名表、添加或修改列以及删除列。例如,可以使用ALTER TABLE命令来实现这些操作。此外,Hive的查询语法中,`ORDER BY`会执行全局排序,可能导致长时间计算,而`SORT BY`则仅在数据进入Reducer前局部排序,更适合大规模数据处理。
在处理大数据时,了解并熟练运用数据仓库和Hive的这些特性是提高数据处理效率和洞察业务的关键。通过对数据仓库的基本概念和Hive表操作的深入理解,IT专业人员能够更好地设计、管理和利用企业数据,以支持复杂的数据分析和决策制定。
剩余31页未读,继续阅读
2022-11-26 上传
2021-08-06 上传
2021-08-07 上传
2023-03-24 上传
2022-03-18 上传
2021-06-22 上传
2021-08-23 上传
2021-08-08 上传
2021-10-30 上传

勒依梨
- 粉丝: 0
- 资源: 2
 我的内容管理
展开
我的内容管理
展开







最新资源
- 计算器(java+applet)130228.rar
- paper_review
- des-site-2
- HTML5JJ:HTML5精讲源代码
- flutter_comic_task:我选择的漫画通过颤动显示在屏幕上
- VB未使用OCX/DLL的增强型“浏览”文件对话框
- Test404网站备份文件扫描器 v2.0(网站备份文件扫描工具)
- LeeBro3,c语言消息队列源码,c语言
- PHP人物图片在线评选投票系统 v1.0.1_tpphp_工具查询网站开发模板(使用说明+PHP源代码+html).zip
- 最小二乘法识别:线性系统的识别,采用最小二乘法。-matlab开发
- KguFood
- 样本:样本
- HTML5:HTML5源代码
- onedrive:Image hosting based on OneDrive API | 基于 OneDrive API 的图床
- 如何获取多样化的搜索结果,与Google,Bing或Yahoo不同
- fastgithub-win-x64.rar
