Transformer模型解析:Encoder-Decoder与词编码
104 浏览量
更新于2024-08-03
收藏 927KB PDF 举报
"Transformer模型详解,包括Transformer的基本结构、Encoder-Decoder架构、Self-Attention机制以及词编码方式的探讨,重点介绍了Word Embedding在解决独热编码问题上的应用。"
Transformer模型是自然语言处理(NLP)领域的一种创新性结构,主要应用于序列到序列(seq2seq)的任务,如机器翻译。它的核心设计理念在于通过自注意力(Self-Attention)机制,使得模型能够全局考虑输入序列的信息,而非局限于局部上下文。
1. Transformer概述
Transformer模型最初由Vaswani等人在2017年的《Attention is All You Need》论文中提出。它摒弃了传统的循环神经网络(RNN)和卷积神经网络(CNN),转而使用全注意力机制。在机器翻译任务中,Transformer接收一种语言的句子作为输入,并生成另一种语言的对应句子作为输出。
2. Encoder-Decoder架构
Transformer模型由Encoder和Decoder两部分组成。Encoder负责理解输入序列的信息,Decoder则负责生成输出序列。每部分由多个相同的层堆叠而成,通常论文中使用6层,但实际应用中可根据需求调整层数。
3. Self-Attention与Encoder
Encoder由多层Self-Attention层组成。Self-Attention允许模型在编码单个词时考虑整个输入序列,这样每个位置的词都能获取到全局上下文信息,增强了模型的理解能力。
4. Decoder的特殊性
Decoder除了Self-Attention层外,还包括Encoder-Decoder Attention层,这一层帮助Decoder关注输入序列的相应部分,以便生成正确的输出。Decoder还需要防止当前位置过早看到未来信息,因此在内部还采用了遮蔽策略(Masking)。
5. 词编码:从One-Hot到Word Embedding
传统的One-Hot编码方式虽然简单,但存在无法表示词汇间的语义关系和高维度问题。为了解决这些问题,Word Embedding应运而生,它是基于word2vec算法的。每个单词被映射到一个固定维度的连续向量空间,这些向量能捕捉到词汇之间的语义和语法关系。例如,Word Embedding维度为4,即使得单词如"dog", "apple", "banana", "cat"在向量空间中有相对的位置,反映了它们的语义相似度。
6. Word Embedding的优势
- 语义表示:Word Embedding能捕捉到单词间的相似性,例如"apple"和"banana"可能比"dog"和"cat"在向量空间中更接近。
- 维度压缩:相比于One-Hot编码,Word Embedding的维度远小于词汇表大小,减少了计算复杂性和存储需求。
- 可学习性:Word Embedding参数可以在训练过程中更新,进一步优化表示。
Transformer模型通过其独特的注意力机制和词编码方式,极大地提升了NLP任务的性能,尤其是在大规模文本处理中展现了卓越的能力。在后续的研究和应用中,Transformer架构被广泛地应用于预训练模型如BERT、GPT等,成为现代NLP技术的基石。
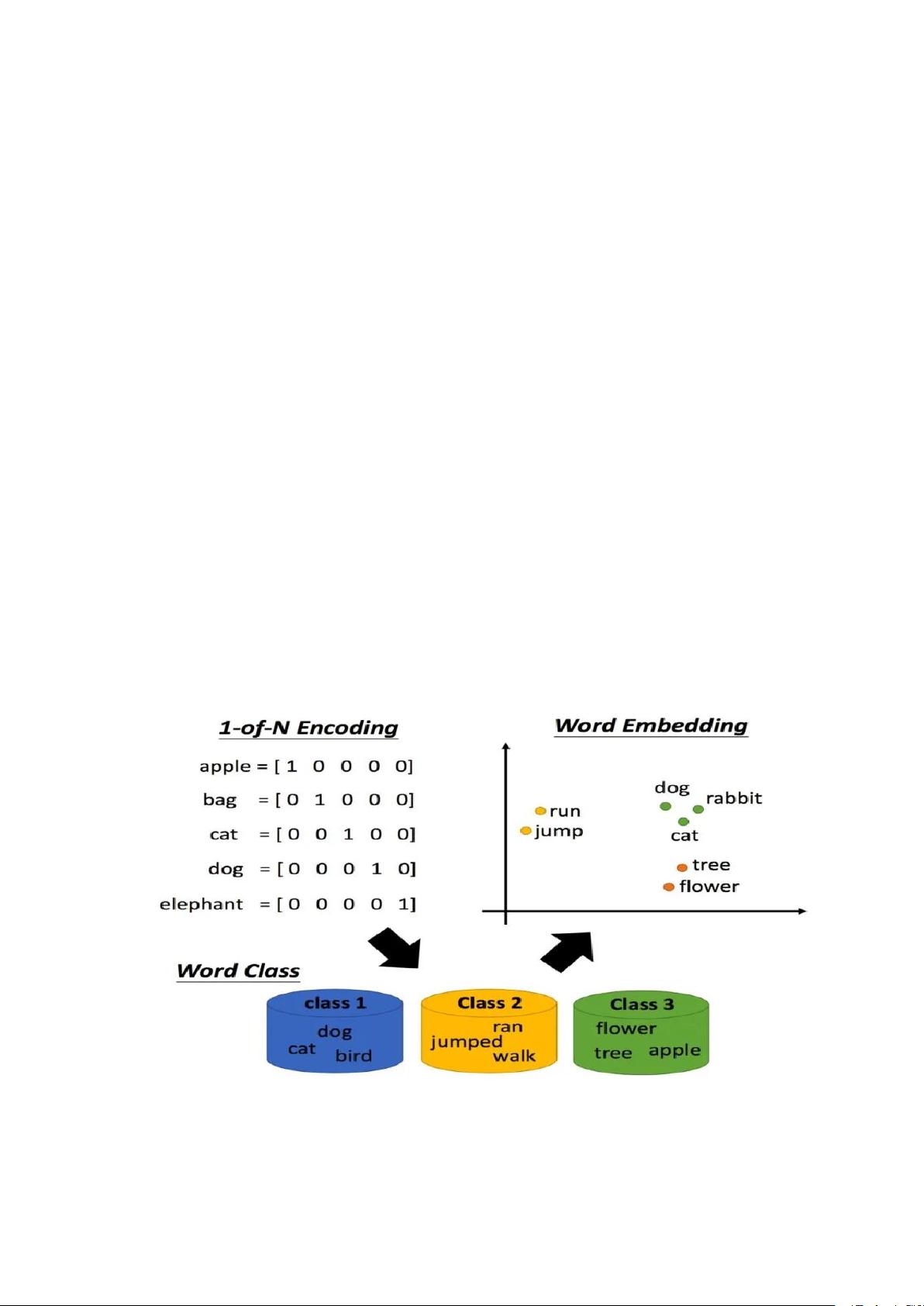
2. 词编码
词编码的手段有很多,比如独热编码(One-Hot 编码),他用以下形式进行
编码,假设要编码的单词有 4 个(dog, apple, banana, cat):
dog: [1, 0, 0, 0]
apple: [0, 1, 0, 1]
banana: [0, 0, 1, 0]
cat: [0, 0, 0, 1]
用这种方法进行编码方法简单,但缺点也有很多,比如:
1.无法表达两个单词之间的相关性(距离)。
以人类的视角来看,apple 和 banana,dog 和 cat 都属于同一类的事物,apple
距离 banana 应该比 dog 更近一些,但从向量上却无法反映出来。
2.词向量维度过大,要编码的向量的维度等于单词的个数。
单单是英语就有成千上万个单词,如果每一个单词都采用这种形式进行编码,那
么所产生的向量的维度将和单词个数一致,这显然是无法接受的(上述维度是 4,
因为有 4 个单词)。
图 5 Word Embedding
剩余11页未读,继续阅读
2023-12-18 上传
113 浏览量
2023-12-15 上传
2023-07-20 上传
2023-05-01 上传
2023-06-28 上传
2023-04-06 上传
2023-08-06 上传
2021-02-24 上传

yyyu1662
- 粉丝: 0
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- 单片机串口通信仿真与代码实现详解
- LVGL GUI-Guider工具:设计并仿真LVGL界面
- Unity3D魔幻风格游戏UI界面与按钮图标素材详解
- MFC VC++实现串口温度数据显示源代码分析
- JEE培训项目:jee-todolist深度解析
- 74LS138译码器在单片机应用中的实现方法
- Android平台的动物象棋游戏应用开发
- C++系统测试项目:毕业设计与课程实践指南
- WZYAVPlayer:一个适用于iOS的视频播放控件
- ASP实现校园学生信息在线管理系统设计与实践
- 使用node-webkit和AngularJS打造跨平台桌面应用
- C#实现递归绘制圆形的探索
- C++语言项目开发:烟花效果动画实现
- 高效子网掩码计算器:网络工具中的必备应用
- 用Django构建个人博客网站的学习之旅
- SpringBoot微服务搭建与Spring Cloud实践
