Spark SQL 2.0/2.1在TPC-DS基准测试中的实战经验
需积分: 5 76 浏览量
更新于2024-06-21
收藏 12.08MB PDF 举报
"这篇文档是关于Spark SQL 2.0和2.1在处理TPC-DS基准测试中的经验分享,由Berni Schiefer在2016年Spark Summit Europe上的演讲内容。"
在大数据处理领域,Spark SQL因其高效、易用的特点,受到了广泛的关注并迅速发展。尽管当时它主要部署在传统的Hadoop集群上,但作者Berni Schiefer提出了一个设想:如果设计出一种专为Spark优化的新型集群会如何?这篇文档正是基于这样的思考,通过使用Spark的最新版本(当时是2.0和2.1),对一个大型企业级的、具有挑战性的工业标准工作负载——TPC-DS进行测试。
TPC-DS(Transaction Processing Performance Council Decision Support)是一个广为认可的数据仓库基准测试,自2004年至2011年初步开发(Version 1),并在2015年进行了升级(Version 2.3)。尽管该基准测试已经存在,但没有供应商正式公布过其结果。TPC-DS模拟了一个假设零售商的多域数据仓库环境,涵盖了零售销售、网络、目录数据、库存、人口统计和促销等多个方面。这个基准旨在反映商业运营的多个方面,包括查询、并发性、数据加载和数据维护(尽管文档未深入讨论这部分)。
TPC-DS测试集包含99个查询,大致分为四类:
1. 报告查询:这类查询通常用于生成日常或周期性的业务报告,例如销售额分析。
2. 探索性查询:这些查询用于深入研究数据,发现模式和趋势,可能涉及复杂的数据聚合和过滤操作。
3. 维度归约查询:这类查询通常用于减少维度表的大小,以提高性能。
4. 验证查询:设计用来验证系统正确性和一致性的查询,确保数据仓库的准确性。
通过TPC-DS,Spark SQL可以在大规模数据处理场景下展示其性能和可扩展性。文档中可能会详细探讨Spark SQL如何处理这些复杂的查询,以及在新型集群架构下相对于传统Hadoop集群的优势。此外,还可能涉及性能优化策略、内存管理和资源调度等方面的内容。
由于Spark SQL 2.0和2.1的引入,带来了DataFrame API和Dataset API的改进,这使得处理结构化和半结构化数据更加高效。同时,该版本还加强了与Hadoop生态系统的集成,提高了SQL查询的性能和兼容性。通过TPC-DS测试,可以评估Spark SQL在大数据分析任务中的实际表现,为实际业务提供参考。
这篇文档是Spark SQL在应对复杂数据仓库查询时的一次实践,对于理解Spark SQL在企业级应用中的性能和优化有着重要的参考价值。对于希望了解Spark SQL在大规模数据处理和性能测试领域的读者来说,这是一个宝贵的学习资源。
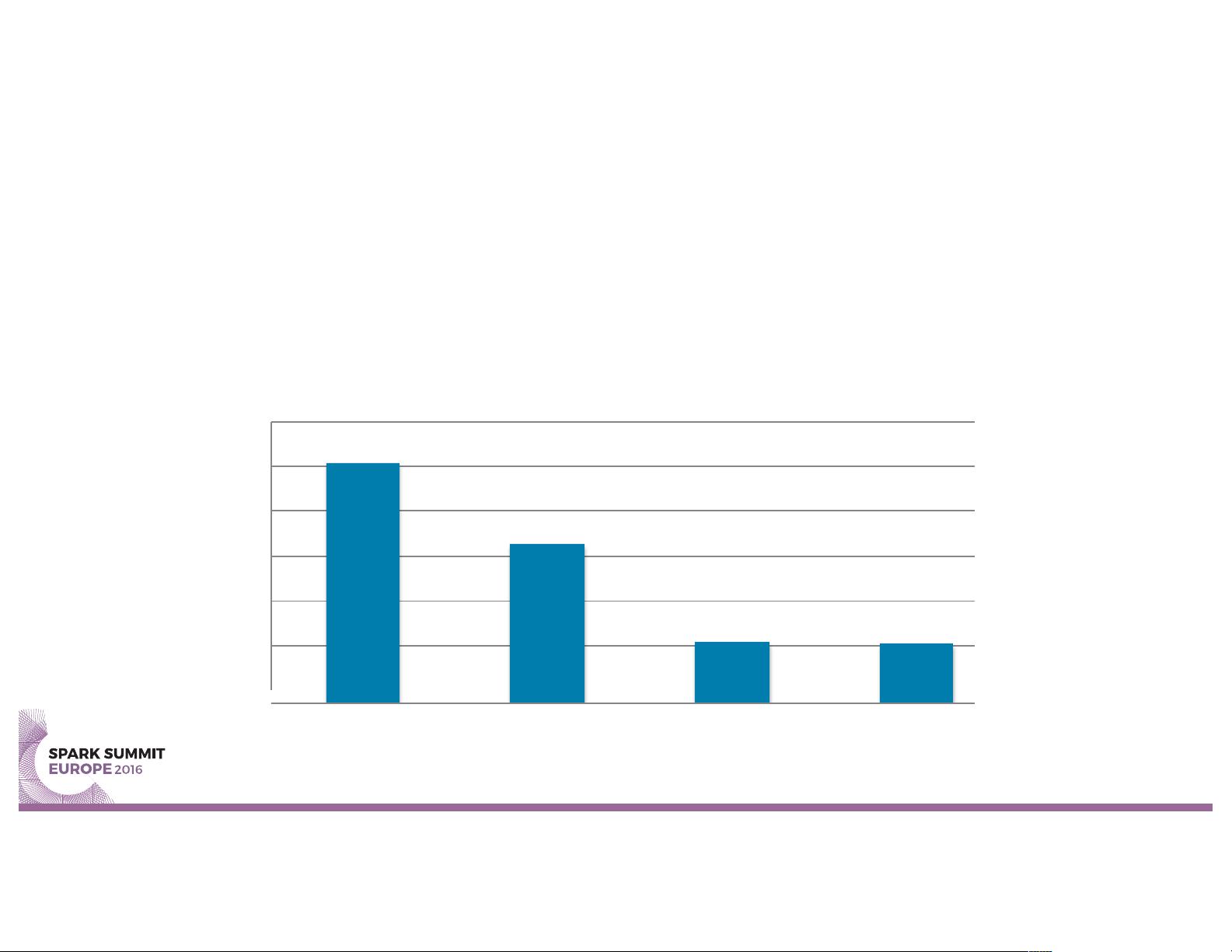
TPC-DS Single User
51,351
33,876
13,283
12,690
0
10,000
20,000
30,000
40,000
50,000
60,000
Spark 1.5 Spark 1.6 Spark 2.0 Spark 2.0 with deep
tuning
TPC-DS @ 10TB Total Time (sec)
for 49 comparable queries only, lower is better
6
剩余30页未读,继续阅读
2023-09-09 上传
2023-08-26 上传
2019-06-09 上传
2019-10-29 上传
2023-09-01 上传
2023-09-01 上传
2024-09-27 上传

weixin_40191861_zj
- 粉丝: 83
- 资源: 1万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- Android圆角进度条控件的设计与应用
- mui框架实现带侧边栏的响应式布局
- Android仿知乎横线直线进度条实现教程
- SSM选课系统实现:Spring+SpringMVC+MyBatis源码剖析
- 使用JavaScript开发的流星待办事项应用
- Google Code Jam 2015竞赛回顾与Java编程实践
- Angular 2与NW.js集成:通过Webpack和Gulp构建环境详解
- OneDayTripPlanner:数字化城市旅游活动规划助手
- TinySTM 轻量级原子操作库的详细介绍与安装指南
- 模拟PHP序列化:JavaScript实现序列化与反序列化技术
- ***进销存系统全面功能介绍与开发指南
- 掌握Clojure命名空间的正确重新加载技巧
- 免费获取VMD模态分解Matlab源代码与案例数据
- BuglyEasyToUnity最新更新优化:简化Unity开发者接入流程
- Android学生俱乐部项目任务2解析与实践
- 掌握Elixir语言构建高效分布式网络爬虫
