优化SQL Server大表分区策略与步骤详解
需积分: 34 64 浏览量
更新于2024-09-09
1
收藏 152KB DOCX 举报
在SQL Server数据库中,处理大表分区方案是一项重要的优化技术,特别是在处理千万级及以上数据量的表时。本文档由陈中威于2016年8月撰写,针对大表分区提供了全面的指导。大表分区主要基于三个关键条件:数据量庞大(至少百万级别)、查询和更新性能下降以及表中存在明显的分段列。
首先,当表中的数据量超过100万条时,应考虑采用分区来分散存储,减少单个表的I/O压力,从而提高查询和写入速度。如果发现表操作变慢,这通常是分区的信号。同时,分区的成功依赖于有明显的列用于划分,例如按日期、地理位置或业务部门等,这样的列可以自然地将数据分成不同的部分。
实施大表分区的步骤包括以下几个部分:
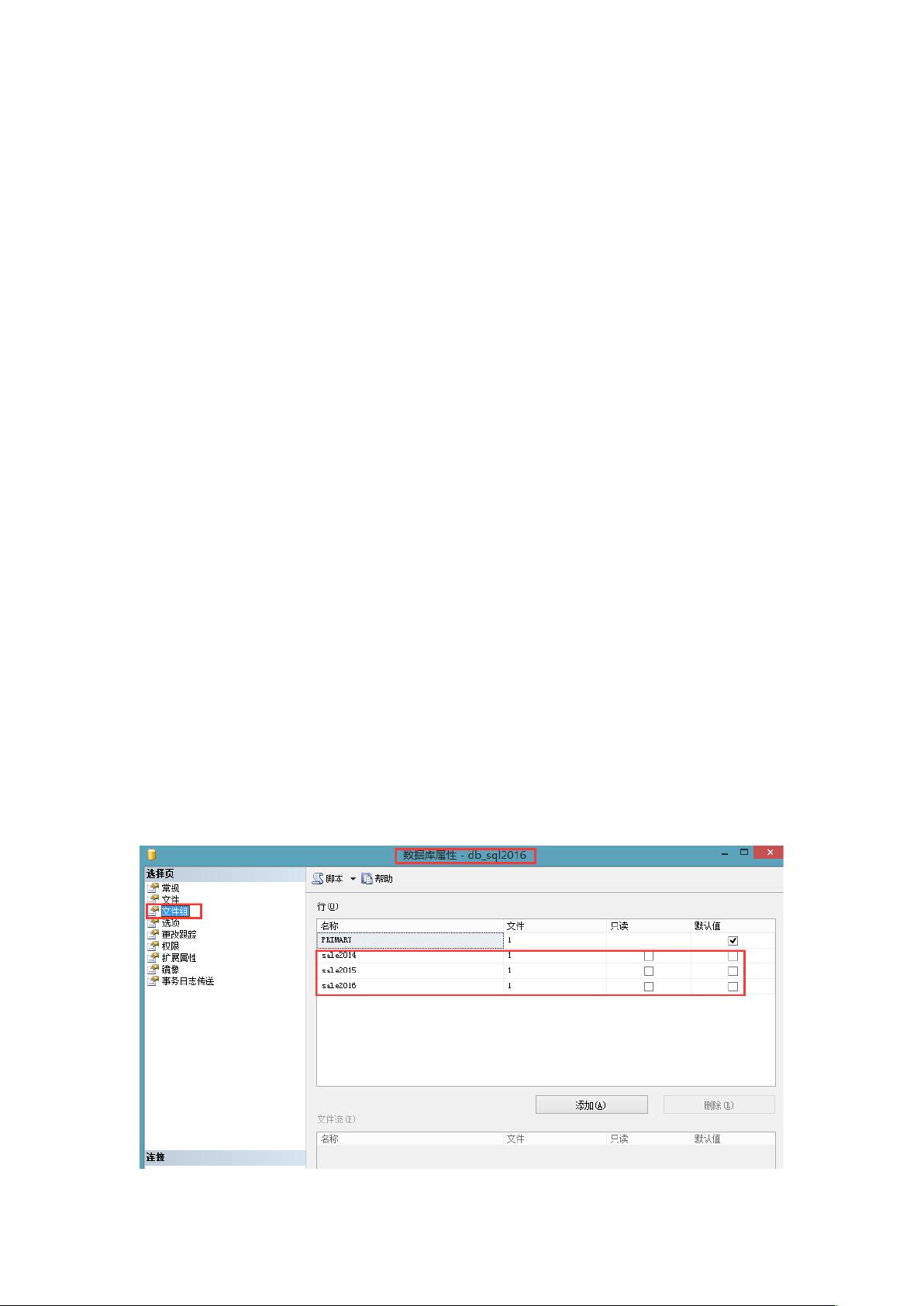
1. 创建数据库和文件组:创建一个新的数据库,如`db_sql2016`,并设定四个文件组,分别为`primary`、`sale2004`、`sale2005`和`sale2006`。`primary`文件组用于存储主数据文件,而其他文件组则用于次要数据。每个文件组都定义了其大小、最大容量和增长策略,比如`filename`指定了文件路径和扩展名,`size`和`maxsize`分别表示初始和最大文件大小,`filegrowth`用于自动扩展文件。
2. 创建文件组时,需要为每个文件指定特定的物理位置,以利用存储设备的优势,如硬盘的不同位置,提高数据访问效率。
3. 分区的创建通常是在表上执行,根据确定的分段列,将表划分为多个物理子表,每个子表存储在不同的文件组中。分区可以按照范围(如按日期范围)、列表(如按特定值列表)或哈希(散列函数决定分区)方式进行。
4. 对于频繁的查询和更新操作,可能需要考虑不同类型的分区策略,如将热点数据(经常被查询的数据)放在较少的分区中,以减少磁盘I/O。同时,分区也会影响数据备份和恢复的时间。
5. 为了确保分区的有效性,需要定期评估和调整分区策略,以适应数据的增长和查询模式的变化。可能需要重新分区、合并或拆分分区以保持性能。
SQL Server的大表分区是管理和优化大型数据库性能的关键手段,通过合理的设计和维护,可以显著提升数据库的整体响应速度和管理效率。然而,实施分区方案需要根据实际业务需求和系统资源来定制,以达到最佳效果。
filegrowth=5%),
filegroup sale2014 -----------sale2014 文件组------
(name='sale2014',
filename='D:\db1\db_sql2016_sale2014.ndf',-----次要数据文件扩展名--
size=5MB,
maxsize=10MB,
filegrowth=5%),
filegroup sale2015 -----------sale2015 文件组------
(name='sale2015',
filename='G:\db2\db_sql2016_sale2015.ndf',-----次要数据文件扩展名--
size=5MB,
maxsize=10MB,
filegrowth=5%),
filegroup sale2016 -----------sale2016 文件组------
(name='sale2016',
filename='H:\db3\db_sql2016_sale2016.ndf',-----次要数据文件扩展名--
size=5MB,
maxsize=10MB,
filegrowth=5%)
log on
(name='db_sql2016 日志文件',
filename='C:\db\db_sql2016.ldf') -------日志文件-------
脚本运行后,实现效果如下:
文件组
3
剩余10页未读,继续阅读
666 浏览量
785 浏览量
353 浏览量
点击了解资源详情
239 浏览量
2024-05-09 上传
132 浏览量
118 浏览量
2021-09-19 上传

tokaika
- 粉丝: 0
 我的内容管理
展开
我的内容管理
展开







最新资源
- 面向对象设计模式:提升复用与灵活性的秘籍
- SQL优化:降龙十八掌——基于索引的性能提升
- Turbo C 主菜单详解:文件与编辑操作指南
- 管理信息系统实验指南——Visual FoxPro 实践
- 深入探索:Linux内核分析技巧与实践
- iReport用户手册:Java图表开发入门
- 湖南移动通信SI合作规范:共创价值,共赢市场
- PCB编辑器网络表载入错误处理及解决方案
- C#连接DBF数据库示例与更新操作
- 持久层设计与ORM实现思想
- 构建高效统一的网络管理体系:策略与实现路径
- 中兴通讯WCDMA技术详解:从基础到演进
- 8051单片机实现简易计算器的硬件与软件设计
- 提升C编程技巧:《微软C编程精粹》精华解读
- 深入解析C/C++指针复杂类型的详细指南
- 演进式设计与计划设计:软件开发的两面
