Git工作原理详解:核心组件与对象存储
需积分: 5 73 浏览量
更新于2024-09-05
收藏 94KB DOCX 举报
"Git工作原理.docx"
Git是一种分布式版本控制系统,它的核心在于高效地管理文件的变更历史。本文档详细介绍了Git的工作原理,包括其底层命令和存储机制。Git通过将文件转换为数据对象,并利用SHA-1哈希算法确保内容的唯一性和完整性。
在Git初始化一个项目时,会在当前目录创建一个隐藏的`.git`目录,这个目录包含了Git的所有元数据和对象库。`.git`目录下有几个关键子目录:
1. **hooks**: 存储客户端和服务端的钩子脚本,这些脚本在特定事件触发时执行,如提交、推送等。
2. **info**: 包含全局排除文件,用于定义不在`.gitignore`中列出但应被忽略的模式。
3. **config**: 存储项目的特定配置选项,如用户信息、远程仓库地址等。
4. **description**: GitWeb程序使用,通常不需要用户直接修改。
5. **HEAD**: 指向当前检出分支的引用。
6. **index**: 保存暂存区信息,记录了哪些文件被添加到暂存区,以及文件的状态。
7. **objects**: 存储所有的数据对象,包括文件内容、树对象、提交对象等。
8. **refs**: 保存指向数据(分支)的提交对象的指针,如`refs/heads/`下存储各个分支的引用。
在Git中,每个文件或目录变更都会被转化为一个对象,有四种基本类型的Git对象: blob(文件内容)、tree(目录结构)、commit(提交信息)和tag(标签)。创建新文件时,Git会将其内容转换为blob对象,并通过SHA-1哈希计算生成一个唯一的ID。这个ID用于在`.git/objects`目录下创建相应的子目录和文件,存储压缩后的文件内容。
当文件被添加到暂存区时,Git创建一个tree对象来表示当前目录的状态,每个tree对象可以包含多个子tree对象和blob对象的引用。提交时,Git会创建一个commit对象,其中包含了父提交的引用(如果有的话)、作者和提交者信息、提交消息以及指向顶级tree对象的引用。这整个过程确保了Git能够追踪到任何文件的完整历史。
此外,Git还通过分支引用(如`refs/heads/master`)来跟踪不同分支的最新提交。当切换分支或者合并代码时,Git会更新HEAD文件来指向新的分支引用,从而实现代码库的多版本管理。
了解Git的这些底层工作原理,可以帮助开发者更深入地理解Git的操作,如解决合并冲突、回溯历史、调试问题等。熟悉这些概念,不仅能够提升日常开发效率,还能在遇到复杂版本控制问题时游刃有余。
Git 工作原理
Git 所做的实质工作——将被改写的文件保存为数据对象,更新
暂存区,记录树对象,最后创建一个指明了顶层树对象和父提
交的提交对象。
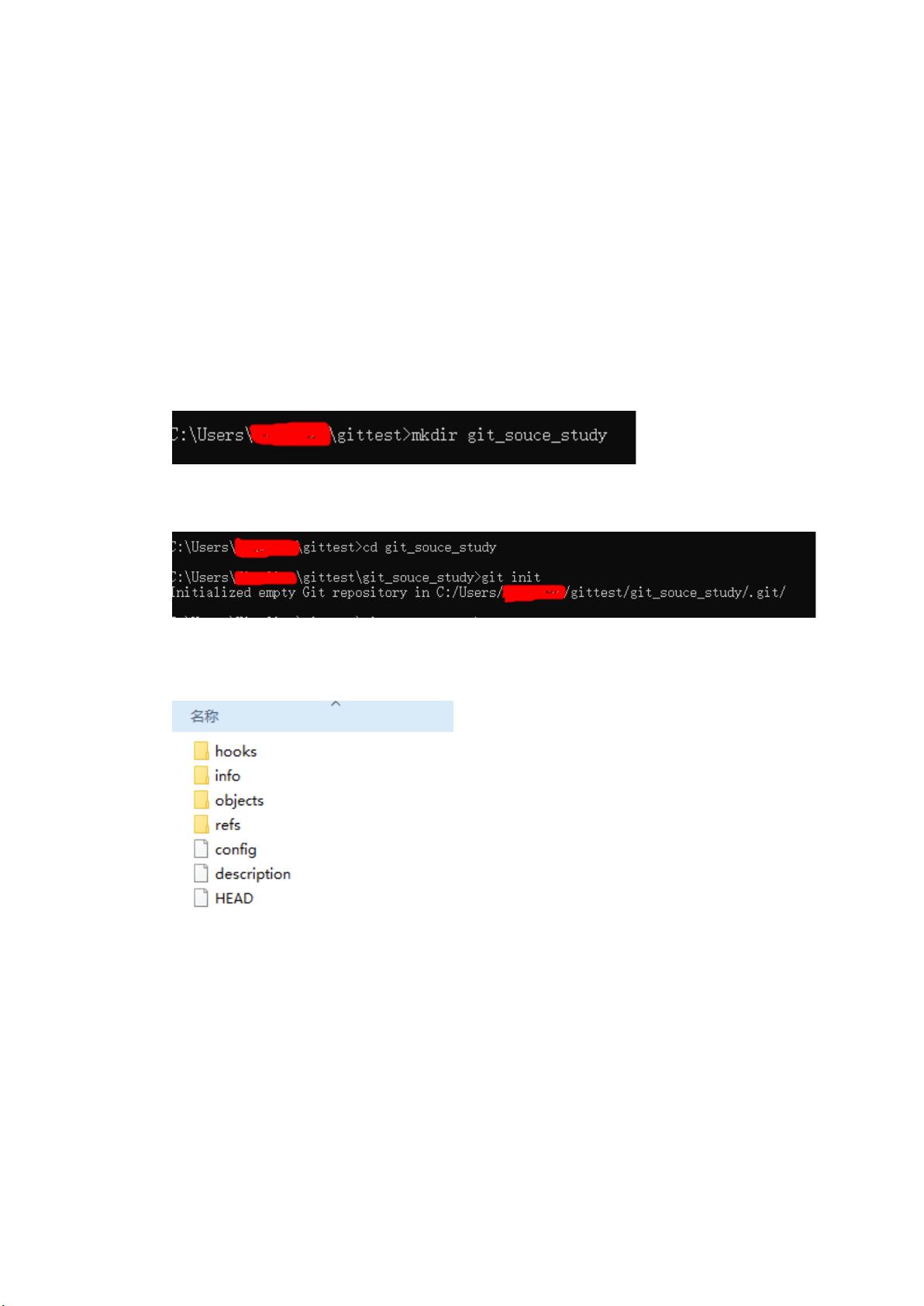
1、干净环境(Windows cmd 命令窗口下)
选定路径创建项目,例如 git_souce_study
进入目录,初始化, git init
2、目录预览
3、目录说明
hooks 目录包含客户端或服务端的钩子脚本(hook scripts)。
info 目录包含一个全局性排除(global exclude)文件,用以放置那些不希
望被记录在 .gi"gnore 文件中的忽略模式(ignored pa#erns)。
con$g 文件包含项目特有的配置选项。
下载后可阅读完整内容,剩余4页未读,立即下载
186 浏览量
356 浏览量
141 浏览量
348 浏览量
124 浏览量
114 浏览量
178 浏览量
271 浏览量
122 浏览量

浮光月影
- 粉丝: 19
 我的内容管理
展开
我的内容管理
展开







最新资源
- 第七届ITAT移动互联网站设计决赛试题分享
- C语言实现52张牌随机分发及排序方法
- VS2008智能提示补丁,让英文变中文的解决办法
- SISTEMA-LACONQUISTA:深入解析Windows窗体窗口应用开发
- STM32F407单片机RTC闹钟唤醒功能实验教程
- CRRedist2005 X86:水晶报表下载辅助文件解析
- Android开发中调用WebService的简易实例教程
- React Native与Electron融合:打造桌面端PWA应用
- fping:高效的网络端口批量测试工具
- 深入解析Spring与MyBatis的整合配置及问题答疑
- 深入探讨Struts2与Spring整合技术实现
- Java游戏项目开发实战:游戏项目1深入解析
- STM32掌机测试教程与资源分享
- Win7内置搜索小工具:百度与谷歌搜索集成
- JWPlayer JavaScript API下载指南
- 精易模块V5.22新特性与功能更新解析
