Spark伪分布式安装部署指南
需积分: 9 31 浏览量
更新于2024-09-06
收藏 336KB DOCX 举报
"该文档详细介绍了如何在Ubuntu系统中安装和部署Spark的伪分布式模式,包括所需的环境准备、Scala的安装、Spark的下载与配置,以及启动和监控Spark集群的步骤。"
Spark伪分布式模式是一种在单机上模拟多节点集群的方式,常用于测试和学习。以下是安装部署Spark伪分布的具体步骤:
1. **环境准备**:
- 首先确保已安装Java开发工具集(JDK),因为Spark依赖于Java环境。
- 需要安装Hadoop,尽管在伪分布式模式中,Hadoop不是必须的,但Spark与Hadoop兼容,因此通常会一起部署。
- 安装Scala编程语言,Spark是用Scala编写的,因此需要安装Scala环境。
2. **安装Scala**:
- 下载Scala安装包,然后使用`tar -zxvf scala-2.10.4.tgz -C ~`命令解压到家目录。
- 通过`mv scala-2.10.4/ scala`命令重命名解压后的目录。
- 使用`vim ~/.bashrc`编辑环境变量配置文件,在文件末尾添加Scala的环境配置,并运行`source ~/.bashrc`使配置生效。
- 验证Scala是否安装成功,通过运行`scala`命令,如果出现Scala交互式解释器界面,说明安装成功。
3. **安装Spark**:
- 下载Spark的二进制包,例如`spark-2.4.4-bin-hadoop2.7.tgz`,并同样解压到家目录。
- 重命名解压后的目录为`spark`。
- 添加Spark的环境变量,编辑`~/.bashrc`文件,添加Spark的环境配置。
4. **配置Spark**:
- **配置slaves文件**:复制`slaves.template`到`slaves`,并在`slaves`文件中添加内容,表示本地机器作为工作节点。
- **配置spark-env.sh文件**:复制`spark-env.sh.template`到`spark-env.sh`,根据实际情况添加相关环境变量,如Hadoop的配置路径等。
5. **启动Spark**:
- 进入Spark的`sbin`目录,通过运行`./start-all.sh`命令启动所有Spark服务,包括Master和Worker。
- 使用`jps`命令检查进程,确认Master和Worker已经启动。
6. **监控Spark**:
- 可以通过Web界面来监控Spark集群的状态:
- 访问`http://ip:8081`查看Worker节点的监控页面,这里的`ip`是你的服务器IP。
- 访问`http://ip:8080`查看Master节点的监控页面,可以看到整个集群的运行情况。
以上就是安装部署Spark伪分布模式的完整过程。这个模式非常适合个人学习和小型测试,因为它在一台机器上模拟了完整的Spark集群,而不需要额外的硬件资源。
spark 伪分布(Standalone)模式安装部署
一、部署环境
1.1 预先安装好 jdk,hadoop,scala 语言
1.2 scala 语言安装
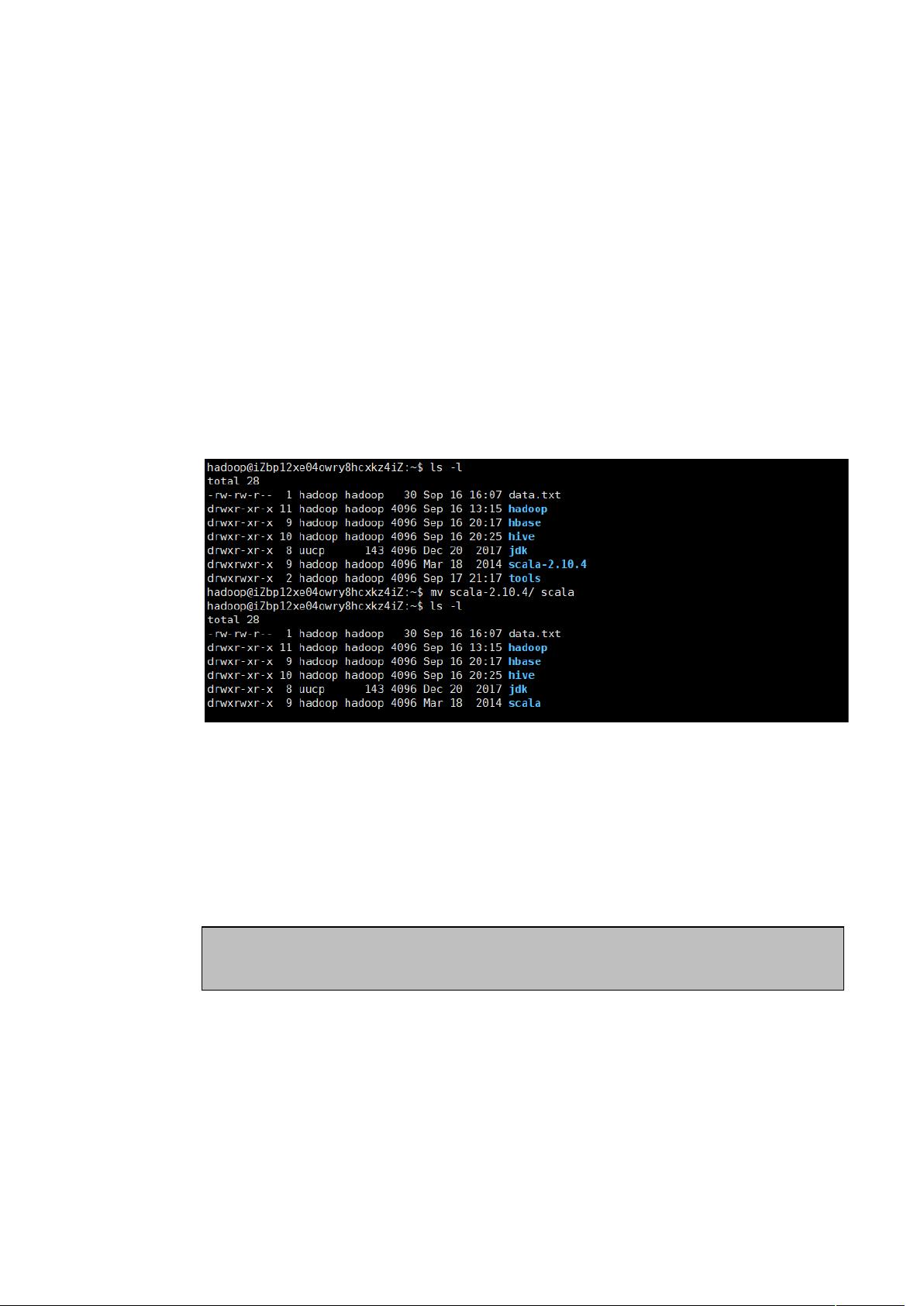
1.2.1 下载 scala 安装包,解压并更名为 scala
解压:tar -zxvf scala-2.10.4.tgz -C ~
更名:mv scala-2.10.4/ scala
1.2.2 添加环境
命令:sudo vim ~/.bashrc
在文件最后添加如下环境配镜
加载一下配置环境:source ~/.bashrc
1.2.3 验证 scala,如果像下图所示则安装成功
输入命令:scala
export SCALA_HOME=/usr/scala/scala-2.11.6(自己安装 scala 的路径)
export PATH=$SCALA_NAME/bin:$PATH
下载后可阅读完整内容,剩余3页未读,立即下载
2014-10-29 上传
2021-10-14 上传
2021-04-27 上传
2024-08-28 上传

@咖啡猫$@
- 粉丝: 1
- 资源: 4
 我的内容管理
展开
我的内容管理
展开







最新资源
- 构建基于Django和Stripe的SaaS应用教程
- Symfony2框架打造的RESTful问答系统icare-server
- 蓝桥杯Python试题解析与答案题库
- Go语言实现NWA到WAV文件格式转换工具
- 基于Django的医患管理系统应用
- Jenkins工作流插件开发指南:支持Workflow Python模块
- Java红酒网站项目源码解析与系统开源介绍
- Underworld Exporter资产定义文件详解
- Java版Crash Bandicoot资源库:逆向工程与源码分享
- Spring Boot Starter 自动IP计数功能实现指南
- 我的世界牛顿物理学模组深入解析
- STM32单片机工程创建详解与模板应用
- GDG堪萨斯城代码实验室:离子与火力基地示例应用
- Android Capstone项目:实现Potlatch服务器与OAuth2.0认证
- Cbit类:简化计算封装与异步任务处理
- Java8兼容的FullContact API Java客户端库介绍
