Python文本分析实战:创建语料库与机器学习模型
《Python应用文本分析实战》是一本由 Benjamin Bengfort、Tony Ojeda 和 Rebecca Bilbro 合著的专业书籍,旨在引导读者探索如何利用Python进行深度的文本处理和分析,从而开发具备语言理解能力的数据产品。本书涵盖了从基础操作到高级技术的全面内容,适合那些对自然语言处理(NLP)、文本挖掘和机器学习感兴趣的开发者。
该书的核心部分围绕以下几个关键知识点展开:
1. **Python基础知识**:首先,作者会介绍Python的基础语法和库,确保读者对这个强大的编程语言有扎实的理解,这对于后续的文本分析至关重要。Python的简洁性和丰富的数据处理模块(如Numpy、Pandas和Matplotlib)将被深入讲解。
2. **文本预处理**:在文本分析过程中,数据清洗和预处理是关键步骤。本书会介绍如何去除噪声(如标点符号、停用词),进行分词、词干提取和词形还原,以及如何进行词频统计和文档向量化,以便于机器学习模型的构建。
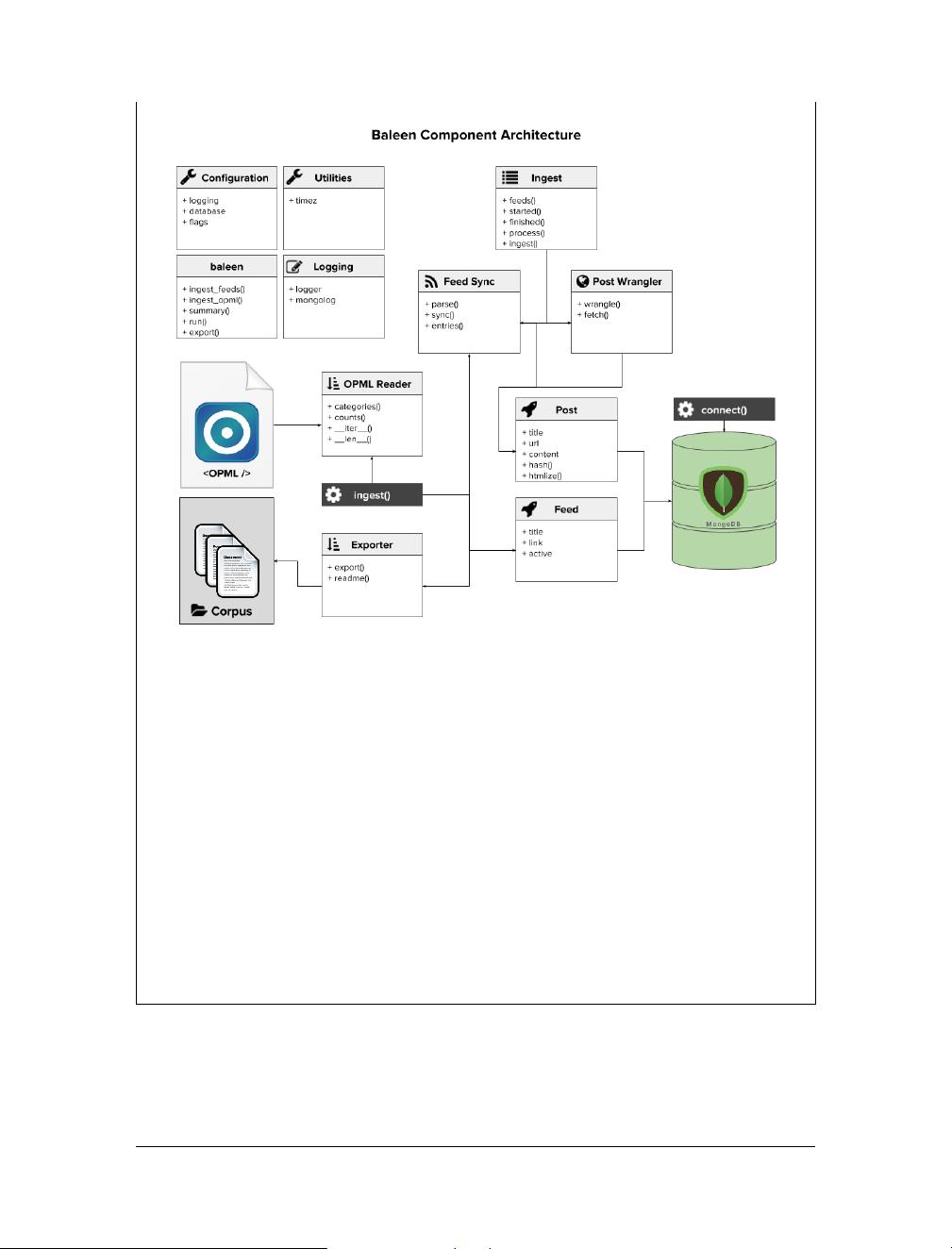
3. **语料库创建**:如何从网络爬虫抓取数据、处理网页结构、下载和存储大规模文本数据,以及如何组织和管理这些语料库,都是书中不可或缺的部分。
4. **模型选择与应用**:书中会详细讨论各种常用的文本分析模型,如TF-IDF、词袋模型、n-gram、朴素贝叶斯、支持向量机(SVM)、深度学习(如RNN和LSTM)等,并通过实例演示如何使用这些模型进行情感分析、主题建模、命名实体识别等任务。
5. **实战项目**:为了帮助读者巩固所学,本书提供了多个实际项目的指导,比如新闻分类、社交媒体监控、用户评论分析等,使理论知识得以实践。
6. **版权与出版信息**:最后,书中包含了版权信息,确认了作者权益,并介绍了O'Reilly Media的出版流程,包括编辑、生产编辑、校对等环节,以及购买和在线获取电子版的途径。
《Applied Text Analysis with Python》是一本实用且全面的指南,不仅适合初学者快速入门文本分析,也适合有一定经验的开发者进一步提升技能,将Python的强大功能应用于实际场景中。无论是对于个人学习还是企业项目开发,都具有很高的参考价值。

There are also several ways to crawl and scrape websites besides the methods we’ve
demonstrated here. For more advanced crawling and scraping, it may be worth look‐
ing into the following tools.
•
Scrapy - an open source framework for extracting data from websites.
• Selenium - a Python library that allows you to simulate user interaction with a
website.
• Apache Nutch - a highly extensible and scalable open source web crawler.
Web crawling and scraping can take us a long way in our quest to acquire text data
from the web, and the tools currently available make performing these tasks easier
and more efficient. However, there is still much work left to do after initial ingestion.
While formatted HTML is fairly easy to parse with packages like BeautifulSoup,
after a bit of experience with scraping, one quickly realizes that while general formats
are similar, different websites can lay out content very differently. Accounting for, and
working with, all these different HTML layouts can be frustrating and time consum‐
ing, which can make using more structured text data sources, like RSS, look much
more attractive.
Ingestion using RSS Feeds and Feedparser
RSS (Really Simple Syndication) is a standardized XML format for syndicated text
data that is primarily used by blogs, news sites, and other online publishers who pub‐
lish multiple documents (posts, articles, etc.) using the same general layout. There are
different versions of RSS, all originally evolved from the Resource Description
Framework (RDF) data serialization model, the most common of which is currently
RSS 2.0. Atom is a newer and more standardized, but at the time of this writing, a less
widely-used approach to providing XML content updates.
Text data structured as RSS is formatted more consistently than text data on a regular
web page, as a content feed, or a series of documents arranged in the order they were
published. This feed means you do not need to crawl the website in order to get other
content or acquire updates, making it preferable to acquiring data through crawling
and scraping. If the desired data resides in the body of blog posts or news articles and
the website makes them available as an RSS feed, you can merely parse that feed.
Another feature of RSS is its ability to synchronize or retrieve the latest version of the
content as articles on the source website are updated. Routine querying ensures any
changes to the content are reflected in the XML. However, the RSS format also has
some notable drawbacks. Most feeds give the content owner the option of displaying
either the full text or just a summary of each post or article. Content owners whose
revenue depends heavily on serving advertisements have an incentive to display only
12 | Chapter 1: Text Ingestion and Wrangling


剩余81页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2021-01-18 上传
2018-01-25 上传
2022-09-23 上传
2023-03-27 上传
点击了解资源详情
点击了解资源详情

承载的流年
- 粉丝: 0
- 资源: 2
 我的内容管理
展开
我的内容管理
展开







最新资源
- ok:K5编程语言的开源解释器
- vue-tiny-loading-overlay:vue.js 2x的任何元素的微小轻量级加载叠加指令
- baseview:音频插件UI的低级窗口系统界面
- cnn_gru-regression-master.zip
- 毕业设计&课设--大学毕业设计.zip
- 数据分析
- Excel模板00固定资产管理台帐.zip
- emgo:恩戈
- stop-words:支持合并的 code.google.compstop-words 的分支
- 毕业设计&课设--大学毕业设计(Web系统),企业人力资源管理系统(小型),前端采用Bootstrap框架,后端使用.zip
- unSAFE_MODE:SAFE_MODE系统更新程序的3DS用户级二次利用。 这实际上是一个相当安全的hax(͡°͜ʖ͡°)
- Excel模板企业公司部门预付款申请表单模板.zip
- holoclean:一种用于数据丰富的机器学习系统
- YANADU_DICT:The Conlang YANADU字典自动程序
- plex-api-graphql:用于Plex API的非官方GraphQL服务器
- mayorleaguec12:Basi HTML页面
