Spark:内存计算引擎的崛起与应用
需积分: 10 127 浏览量
更新于2024-09-04
收藏 101KB DOCX 举报
Spark笔记1.docx
Spark是一款专为大规模数据处理而设计的分布式计算框架,它诞生于2009年美国加州大学伯克利分校AMP实验室,2014年正式成为Apache的顶级项目,因其卓越的数据模型、计算抽象和强大的生态系统而广受欢迎。
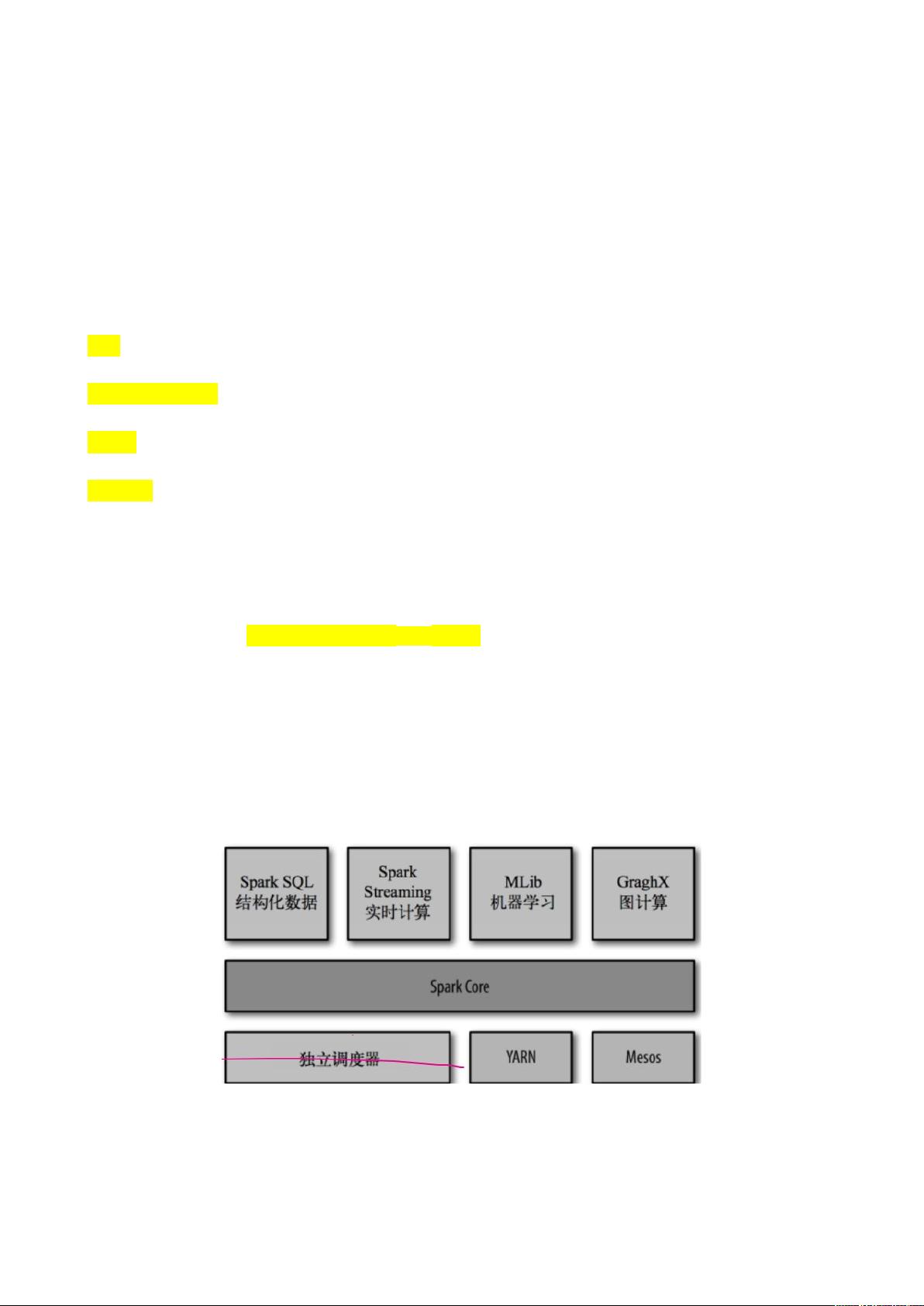
Spark的核心特点是其基于内存的计算能力,这使得它在处理数据时的速度远超传统的MapReduce,通常能达到10-100倍的性能提升。Spark支持多种计算模型,如批处理、交互式查询、实时流处理和机器学习,使其具备了高度的通用性和灵活性。它能无缝对接大数据平台,如YARN和Mesos,同时兼容Hadoop的数据。
相比于Hadoop,Spark的优势主要体现在以下几个方面:
1. 数据存储和计算效率:Spark通过内存计算避免了频繁的数据磁盘I/O,这在处理大规模数据时具有显著优势。
2. 更广泛的计算能力:除了MapReduce模型,Spark提供了Spark SQL(处理结构化数据)、Spark Streaming(实时流处理)、Spark MLlib(机器学习库)和GraphX(图计算),扩展了数据处理的多样性。
3. 生态系统的完善:Spark拥有一个丰富的生态系统,包括各种数据处理工具和库,满足不同场景的需求。
Spark提供多种运行模式,以适应不同的应用场景:
- **Local模式**(单机):适合开发和测试,无需设置复杂的集群。
- **Standalone集群模式**:同样适用于开发和测试,但可扩展到多台机器,提高性能。
- **HA高可用模式**:针对生产环境,保证任务的稳定性和可靠性。
- **On YARN集群模式**:在Hadoop YARN之上运行,用于大规模生产环境。
- **On Mesos集群模式**:国内较少使用,但也是跨平台的选择。
- **On Cloud集群模式**:中小公司或云计算环境中,未来趋势是使用云服务部署。
安装部署Spark时,可以选择本地模式:
1. 下载并解压Spark包。
2. 在本地启动`spark-shell`,默认为`local[*]`,表示使用所有可用核心;也可以指定特定核心数量,如`./spark-shell --master local[n]`。
初识Spark,可以通过一个简单的例子来体验,例如读取本地文本文件进行WordCount操作:
```scala
val textFile = sc.textFile("file:///opt/tt.txt") // 使用SparkContext读取文件
val counts = textFile.flatMap(line => line.split(" ")) // 将每行分割成单词
.map(word => (word, 1)) // 统计每个单词出现次数
.reduceByKey(_ + _) // 求和
counts.collect() // 打印结果
```
Spark凭借其高性能、易用性和灵活性,在大数据处理领域占据了重要的位置,成为许多企业首选的分析引擎之一。
什么是
基于内存的,用于大规模数据处理(离线计算、实时计算、快速查询(交互式查询))的统一分析
引擎。
特点
快:
计算速度是 计算速度的 倍
易用:(算法多)
支持 种计算模型, 支持更多的计算模型。
通用:
能够进行离线计算、交互式查询(快速查询)、实时计算、机器学习、图计算等
兼容性:
支持大数据中的 调度,支持 。可以处理 计算的数据。
发展史
、 年诞生于美国加州大学伯克利分校 实验室
、 年,成为 的顶级项目
为什么会流行
原因 :优秀的数据模型和计算抽象
将多个 之间的中间数据写入内存, 将中间数据写入硬盘,内存比硬盘速度快
原因 :完善的生态圈
能够进行离线计算、交互式查询(快速查询)、实时计算、机器学习、图计算等
: 基本功能
操作结构化数据
下载后可阅读完整内容,剩余6页未读,立即下载
2020-07-26 上传
2020-05-07 上传
2022-01-18 上传
2020-07-09 上传
2020-11-09 上传
2020-11-06 上传
2020-07-17 上传
2020-04-23 上传
2022-12-24 上传

睡覺了
- 粉丝: 711
- 资源: 11
 我的内容管理
展开
我的内容管理
展开







最新资源
- 正整数数组验证库:确保值符合正整数规则
- 系统移植工具集:镜像、工具链及其他必备软件包
- 掌握JavaScript加密技术:客户端加密核心要点
- AWS环境下Java应用的构建与优化指南
- Grav插件动态调整上传图像大小提高性能
- InversifyJS示例应用:演示OOP与依赖注入
- Laravel与Workerman构建PHP WebSocket即时通讯解决方案
- 前端开发利器:SPRjs快速粘合JavaScript文件脚本
- Windows平台RNNoise演示及编译方法说明
- GitHub Action实现站点自动化部署到网格环境
- Delphi实现磁盘容量检测与柱状图展示
- 亲测可用的简易微信抽奖小程序源码分享
- 如何利用JD抢单助手提升秒杀成功率
- 快速部署WordPress:使用Docker和generator-docker-wordpress
- 探索多功能计算器:日志记录与数据转换能力
- WearableSensing: 使用Java连接Zephyr Bioharness数据到服务器
