《矩阵烹饪书》:矩阵知识宝典
需积分: 10 10 浏览量
更新于2024-07-15
收藏 683KB PDF 举报
"The Matrix Cookbook.pdf" 是一本关于矩阵知识的工具书,收集了大量与矩阵相关的事实、身份、近似值、不等式和关系等内容,适用于快速查询,不适合作为系统学习的教材。
该书的目的是为了方便那些需要快速查阅矩阵相关知识的读者。书中所包含的矩阵公式和性质大多来源于网络上的笔记和书籍附录,作者并未声称这些内容为原创,而是进行了整理和汇集。同时,书中明确指出可能存在错误、打字错误或疏漏,并鼓励读者发现后通过指定邮箱 cookbook@2302.dk 提供更正。
这本书是一个持续更新的项目,版本会随着日期的更新而变化。作者欢迎读者通过电子邮件提供额外内容的建议或对某些主题进行深入探讨的提议。关键词包括矩阵代数、矩阵关系、矩阵恒等式、行列式导数、逆矩阵导数以及矩阵的微分。
书中涵盖了广泛的主题,例如矩阵的基本运算、特殊类型的矩阵(如对角矩阵、单位矩阵、正交矩阵等)、矩阵的性质(如秩、迹、行列式、特征值和特征向量)、矩阵函数的导数和微分、以及与线性变换和微分方程相关的矩阵理论。此外,还涉及到了矩阵的近似计算和不等式,这对于解决实际问题,如在数值分析、信号处理、机器学习等领域具有重要的应用价值。
这本书的作者名单包括 Kaare Brandt Petersen 和 Michael Syskind Pedersen,他们感谢了多位贡献者和建议者,以及资助其博士研究的 Oticon 基金会。《矩阵食谱》是数学和工程领域研究人员、学生和专业工作者不可或缺的参考资料,它提供了丰富的矩阵理论和实用技巧。
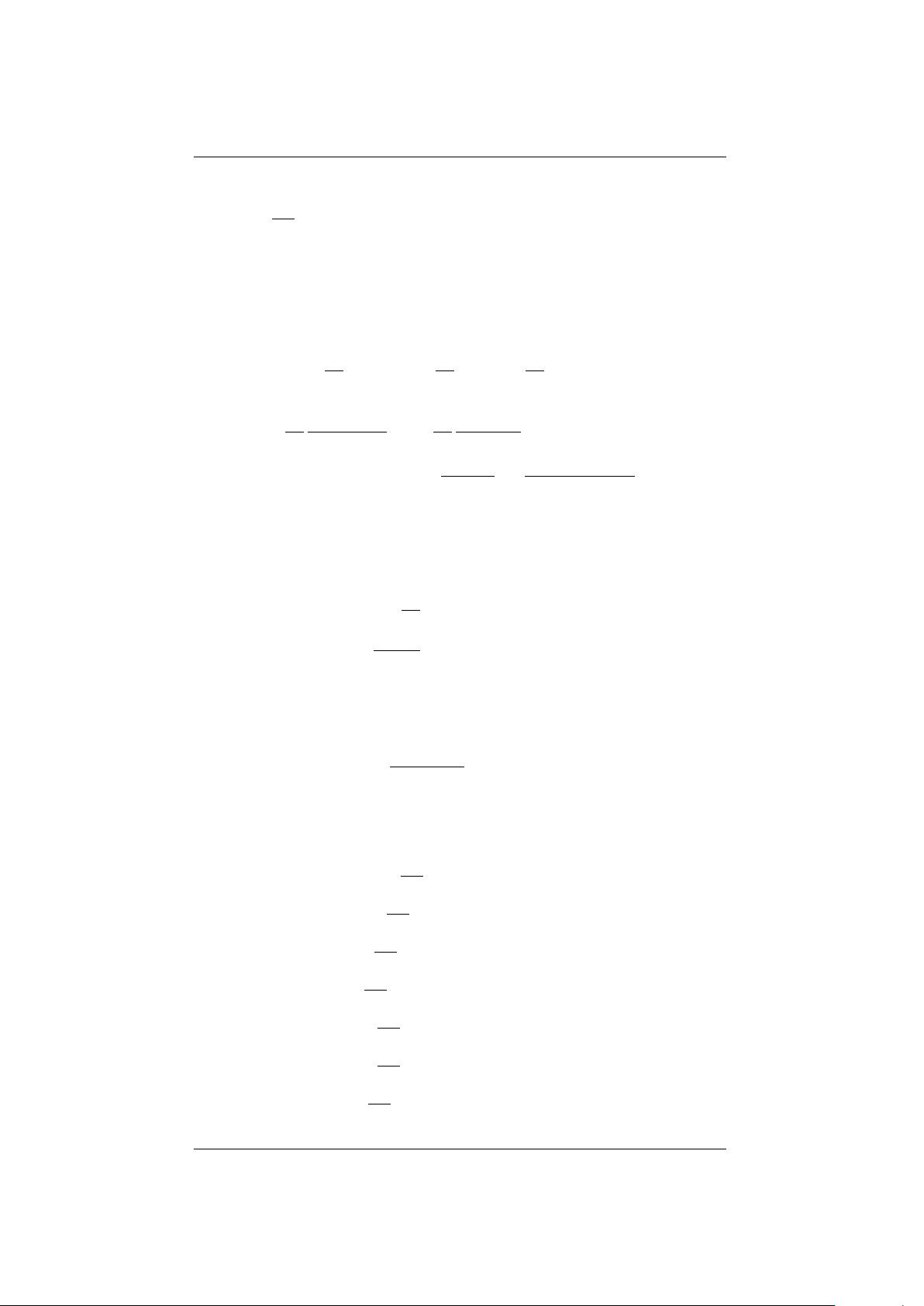
2.5 Derivatives of Traces 2 DERIVATIVES
∂
∂X
a
T
(X
n
)
T
X
n
b =
n−1
X
r=0
h
X
n−1−r
ab
T
(X
n
)
T
X
r
+(X
r
)
T
X
n
ab
T
(X
n−1−r
)
T
i
(92)
See B.1.3 for a proof.
Assume s and r are functions of x, i.e. s = s(x), r = r(x), and that A is a
constant, then
∂
∂x
s
T
Ar =
∂s
∂x
T
Ar +
∂r
∂x
T
A
T
s (93)
∂
∂x
(Ax)
T
(Ax)
(Bx)
T
(Bx)
=
∂
∂x
x
T
A
T
Ax
x
T
B
T
Bx
(94)
= 2
A
T
Ax
x
T
BBx
− 2
x
T
A
T
AxB
T
Bx
(x
T
B
T
Bx)
2
(95)
2.4.4 Gradient and Hessian
Using the above we have for the gradient and the Hessian
f = x
T
Ax + b
T
x (96)
∇
x
f =
∂f
∂x
= (A + A
T
)x + b (97)
∂
2
f
∂x∂x
T
= A + A
T
(98)
2.5 Derivatives of Traces
Assume F (X) to be a differentiable function of each of the elements of X. It
then holds that
∂Tr(F (X))
∂X
= f(X)
T
where f (·) is the scalar derivative of F (·).
2.5.1 First Order
∂
∂X
Tr(X) = I (99)
∂
∂X
Tr(XA) = A
T
(100)
∂
∂X
Tr(AXB) = A
T
B
T
(101)
∂
∂X
Tr(AX
T
B) = BA (102)
∂
∂X
Tr(X
T
A) = A (103)
∂
∂X
Tr(AX
T
) = A (104)
∂
∂X
Tr(A ⊗ X) = Tr(A)I (105)
Petersen & Pedersen, The Matrix Cookbook, Version: November 15, 2012, Page 12



剩余71页未读,继续阅读
2020-08-23 上传
2019-09-06 上传
2011-08-26 上传
2018-02-08 上传
2021-09-29 上传
2020-01-30 上传
点击了解资源详情

空荡心痕
- 粉丝: 0
- 资源: 2
 我的内容管理
展开
我的内容管理
展开







最新资源
- Java集合ArrayList实现字符串管理及效果展示
- 实现2D3D相机拾取射线的关键技术
- LiveLy-公寓管理门户:创新体验与技术实现
- 易语言打造的快捷禁止程序运行小工具
- Microgateway核心:实现配置和插件的主端口转发
- 掌握Java基本操作:增删查改入门代码详解
- Apache Tomcat 7.0.109 Windows版下载指南
- Qt实现文件系统浏览器界面设计与功能开发
- ReactJS新手实验:搭建与运行教程
- 探索生成艺术:几个月创意Processing实验
- Django框架下Cisco IOx平台实战开发案例源码解析
- 在Linux环境下配置Java版VTK开发环境
- 29街网上城市公司网站系统v1.0:企业建站全面解决方案
- WordPress CMB2插件的Suggest字段类型使用教程
- TCP协议实现的Java桌面聊天客户端应用
- ANR-WatchDog: 检测Android应用无响应并报告异常
