优化Hadoop TeraSort的垃圾回收调优策略
需积分: 0 52 浏览量
更新于2024-07-23
收藏 1.16MB PDF 举报
本文主要探讨了在Apache Hadoop框架上运行的TeraSort工作负载的垃圾收集(GC)特性及其调优指南。TeraSort是Hadoop分布式计算平台中用于对大量数据进行排序的标准示例应用程序,特别适用于处理TB级别的数据。作者Shrinivas Joshi和Vasileios Liaskovitis作为软件性能工程师,深入研究了Hadoop环境下,特别是针对TeraSort任务,如何通过调整Java虚拟机(JVM)参数来优化GC行为,从而提高性能。
首先,文章回顾了Java GC的基本特征,包括不同类型的垃圾收集器(如Serial、Parallel、CMS、G1等),它们的工作原理、优缺点以及在大规模数据处理场景中的影响。对于TeraSort而言,由于其高度并行化和数据密集型的特性,选择正确的GC策略至关重要。
针对Hadoop TeraSort工作负载,作者提供了一些调优建议,重点在于如何设置JVM参数,如堆大小(-Xmx和-Xms)、新生代和老年代的大小、是否启用分代收集器、以及是否使用G1垃圾收集器等。他们分享了通过调整这些参数在实验集群上的实际应用案例,结果显示通过GC调优,性能得到了7%的提升。
文章还专门讨论了Map和Reduce任务JVM的GC特性与优化策略。Map任务通常涉及小数据块的处理,而Reduce任务则处理合并和排序的结果,因此两者的GC需求可能会有所不同。作者强调了对这两个阶段进行个性化配置的重要性,以确保整体系统的稳定性和效率。
此外,文中还提到了与本文主题相关的其他技术和术语,如内存管理、并发性模型、暂停时间等,帮助读者更好地理解GC在Hadoop TeraSort工作负载中的作用。对于那些对分布式计算、Hadoop和GC有深厚背景的读者,本文将是一个深入学习和实战经验的重要参考。
本文是一篇关于如何针对Hadoop TeraSort特定工作负载进行Java垃圾收集器优化的实用指南,为Hadoop用户提供了关键的性能调优技巧,以提升大数据处理的效率和稳定性。
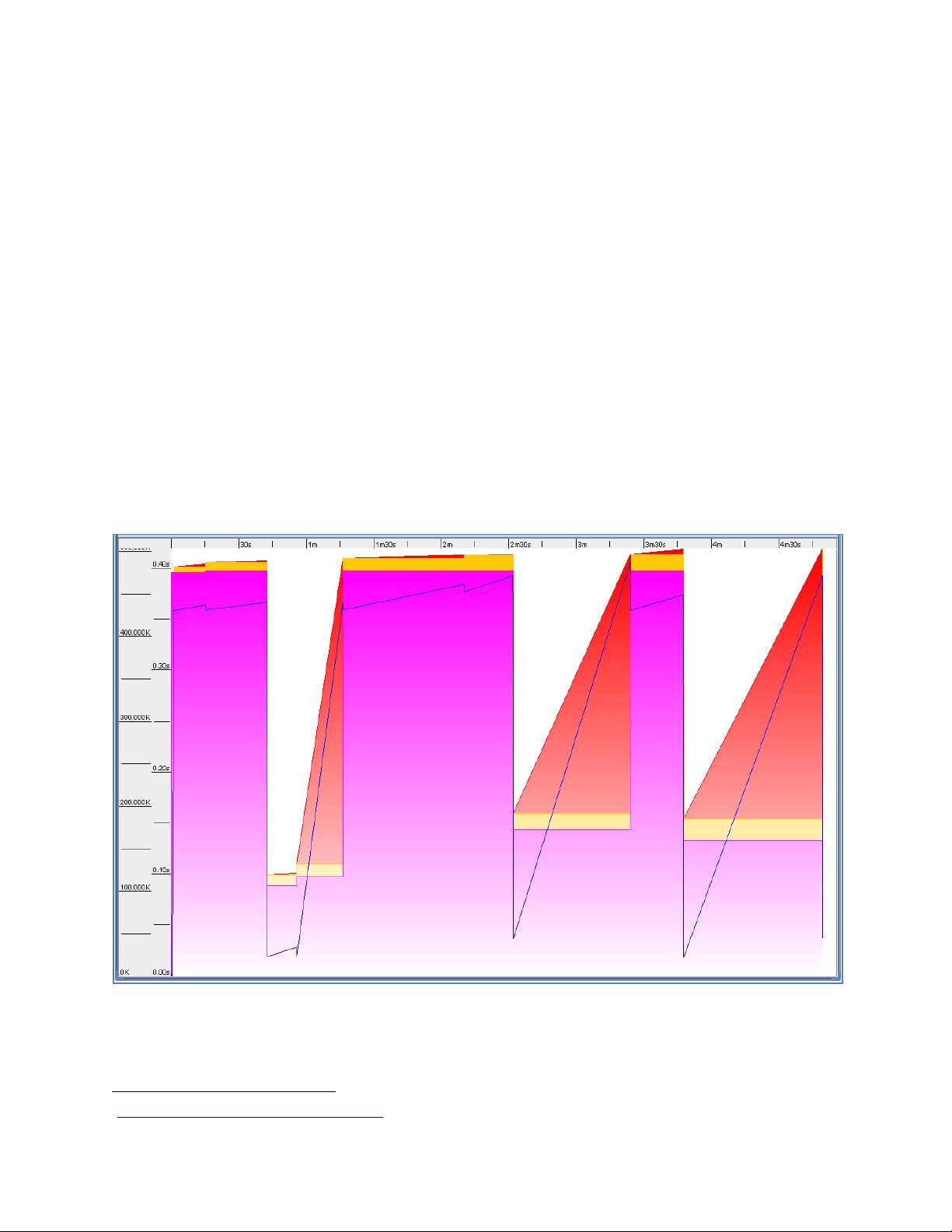
Within the first few seconds of the Map JVM run, the old generation occupancy goes up to the
range of approximately 420M to 440M. Also, this huge chunk of data gets allocated directly into
the old generation; perhaps a huge array or a collection object backed by an array gets allocated
that cannot fit into the young generation.
No collections happen for approximately the next 20 to 40 seconds. After this, a major collection
collects almost everything from the old generation. Somewhere between 2M and 22M data is
left live in the old generation after this major collection.
Old generation occupancy stays in this low-20M range for about 20 to 80 seconds longer. After
this, another huge allocation happens in the old generation. Old generation occupancy goes
back up to the 420M-to-440M range.
Old generation occupancy stays in this 420-440M range for approximately 30 to 120 seconds
longer. After this, another major collection happens, and old generation occupancy returns to
the 2-20M range.
This pattern repeats throughout the run of Map JVMs. We think this repetitive GC pattern
coincides with multiple Map tasks being scheduled on the same JVM throughout the execution.
Fig. 1 contains a graph generated using the GCViewer
4
tool that shows the observed GC behavior for one
of the indicative Map JVMs running on one of the nodes.
Figure 1: Occupancy of different generations of Java heap over the period of an indicative Map JVM run.
4
http://www.tagtraum.com/gcviewer.html
剩余15页未读,继续阅读
2024-10-16 上传
2024-10-16 上传

blue_in_blue
- 粉丝: 0
- 资源: 3
 我的内容管理
展开
我的内容管理
展开







最新资源
- 新型智能电加热器:触摸感应与自动温控技术
- 社区物流信息管理系统的毕业设计实现
- VB门诊管理系统设计与实现(附论文与源代码)
- 剪叉式高空作业平台稳定性研究与创新设计
- DAMA CDGA考试必备:真题模拟及章节重点解析
- TaskExplorer:全新升级的系统监控与任务管理工具
- 新型碎纸机进纸间隙调整技术解析
- 有腿移动机器人动作教学与技术存储介质的研究
- 基于遗传算法优化的RBF神经网络分析工具
- Visual Basic入门教程完整版PDF下载
- 海洋岸滩保洁与垃圾清运服务招标文件公示
- 触摸屏测量仪器与粘度测定方法
- PSO多目标优化问题求解代码详解
- 有机硅组合物及差异剥离纸或膜技术分析
- Win10快速关机技巧:去除关机阻止功能
- 创新打印机设计:速释打印头与压纸辊安装拆卸便捷性
