Hadoop MapReduce实战指南:处理大数据与云环境部署
需积分: 13 99 浏览量
更新于2024-07-19
收藏 2.82MB PDF 举报
《Hadoop MapReduce Cookbook》是一本专为IT专业人士设计的指南,旨在帮助读者掌握在大数据处理和分析领域中使用Apache Hadoop MapReduce技术的关键技能。本书从安装Hadoop YARN(Yet Another Resource Negotiator)和HDFS(Hadoop Distributed File System)等核心组件开始,引导读者逐步了解并实践各种令人兴奋的主题。
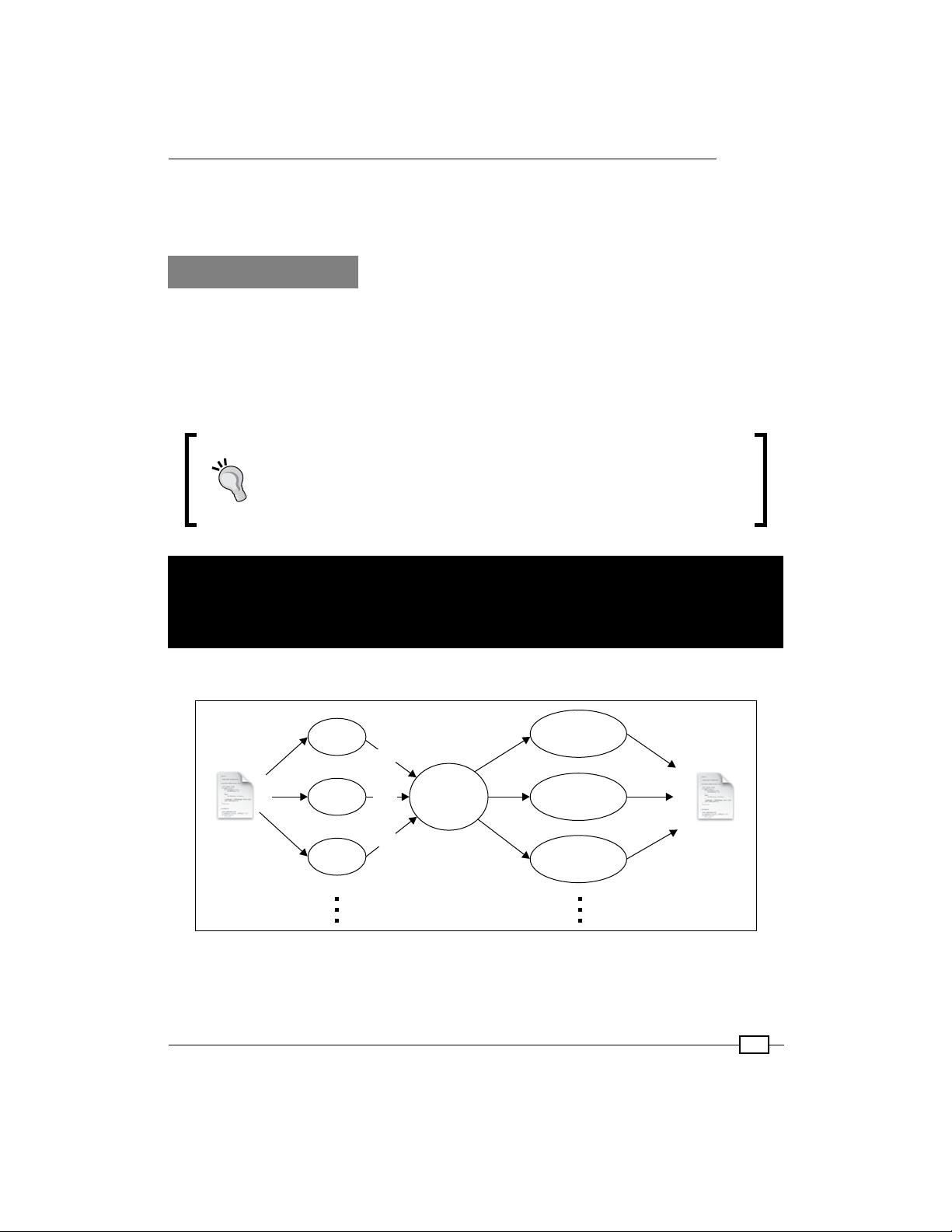
首先,书中详尽介绍了MapReduce模式,这是Hadoop处理大规模数据的基础架构,通过其分布式计算模型,可以高效地执行并行任务。MapReduce由两个主要阶段组成:Map阶段负责将输入数据划分为小块,进行本地处理;Reduce阶段则汇总Map阶段的结果,生成最终输出。读者会学习如何优化这些步骤,提高性能和效率。
在数据分析方面,作者将指导读者如何利用Hadoop解决各种实际问题,如统计分析、分类、在线营销策略优化以及个性化推荐系统的设计。这些应用展示了Hadoop在商业场景中的广泛实用性,帮助企业挖掘隐藏在海量数据背后的宝贵信息。
此外,书中的内容还将扩展到Hadoop生态系统中的其他关键项目。例如,Hive是一个SQL查询语言,用于在Hadoop上进行大规模数据仓库操作;HBase是一种NoSQL数据库,适合存储半结构化和非结构化数据;Pig是数据流语言,便于用户以接近自然语言的方式编写复杂的数据转换脚本;Mahout是机器学习库,用于构建复杂的预测模型;Nutch是开源的网络抓取工具,用于大规模网页抓取;而Giraph则是专门用于大规模图处理的框架。
对于云计算环境部署,本书也提供了实践经验,教会读者如何将Hadoop集群部署到云端,如Amazon Web Services (AWS)或Google Cloud Platform (GCP),以实现弹性扩展和成本效益。
值得注意的是,尽管本书力求提供准确的信息,但版权和使用限制必须遵守,未经出版社许可,不能复制、存储或传输书中的内容。所有内容都是在尊重知识产权的前提下提供的,同时强调了没有保证信息的绝对准确性的事实,因为技术更新迅速,可能存在一定的时效性差异。
《Hadoop MapReduce Cookbook》是一本实用且全面的资源,无论你是初学者还是经验丰富的开发人员,都能从中获取宝贵的实战技巧和理论知识,提升在大数据处理领域的专业能力。通过跟随书中的步骤和案例,读者可以更好地理解和掌握这个强大的数据处理平台,适应不断发展的大数据时代需求。

Preface
3
Any command-line input or output is written as follows:
>tar -zxvf hadoop-1.x.x.tar.gz
New terms and important words are shown in bold. Words that you see on the screen, in
menus or dialog boxes for example, appear in the text like this: "Create a S3 bucket to upload
the input data by clicking on Create Bucket".
Warnings or important notes appear in a box like this.
Tips and tricks appear like this.
Reader feedback
Feedback from our readers is always welcome. Let us know what you think about this
book—what you liked or may have disliked. Reader feedback is important for us to
develop titles that you really get the most out of.
To send us general feedback, simply send an e-mail to
feedback@packtpub.com, and
mention the book title via the subject of your message.
If there is a topic that you have expertise in and you are interested in either writing or
contributing to a book, see our author guide on www.packtpub.com/authors.
Customer support
Now that you are the proud owner of a Packt book, we have a number of things to help you to
get the most from your purchase.
Downloading the example code
You can download the example code les for all Packt books you have purchased from your
account at http://www.PacktPub.com. If you purchased this book elsewhere, you can
visit http://www.PacktPub.com/support and register to have the les e-mailed directly
to you.


剩余299页未读,继续阅读
2015-09-07 上传
2023-05-14 上传
2023-06-12 上传
2023-06-10 上传
2023-06-01 上传
2023-02-22 上传
2023-05-25 上传
2023-03-16 上传

北怀瑾
- 粉丝: 2
- 资源: 12
 我的内容管理
展开
我的内容管理
展开







最新资源
- 俄罗斯RTSD数据集实现交通标志实时检测
- 易语言开发的文件批量改名工具使用Ex_Dui美化界面
- 爱心援助动态网页教程:前端开发实战指南
- 复旦微电子数字电路课件4章同步时序电路详解
- Dylan Manley的编程投资组合登录页面设计介绍
- Python实现H3K4me3与H3K27ac表观遗传标记域长度分析
- 易语言开源播放器项目:简易界面与强大的音频支持
- 介绍rxtx2.2全系统环境下的Java版本使用
- ZStack-CC2530 半开源协议栈使用与安装指南
- 易语言实现的八斗平台与淘宝评论采集软件开发
- Christiano响应式网站项目设计与技术特点
- QT图形框架中QGraphicRectItem的插入与缩放技术
- 组合逻辑电路深入解析与习题教程
- Vue+ECharts实现中国地图3D展示与交互功能
- MiSTer_MAME_SCRIPTS:自动下载MAME与HBMAME脚本指南
- 前端技术精髓:构建响应式盆栽展示网站
