互联网架构实践:相辅相成的存储系统解析
需积分: 10 166 浏览量
更新于2024-09-02
收藏 667KB PDF 举报
"朱晔的互联网架构实践心得分享,主要探讨了相辅相成的存储五件套,包括关系型数据库、索引型数据库、时序型数据库、文档型数据库和缓存型数据库在架构设计中的角色和应用。"
在互联网架构中,存储系统的多样性是关键,以应对不同业务场景的需求。这五种类型的数据库各有所长,能够协同工作,提供高效、稳定的数据存储和访问。
1. **关系型数据库**:如MySQL,是强事务性和数据一致性的保证,适合处理结构化数据。在高并发和大数据量的情况下,可通过Sharding技术进行数据切片,分散到多个集群,减轻单点压力。然而,Sharding带来的查询复杂性可以通过创建Index数据表来缓解,将常用查询字段存储在一个未分片的表中,提高查询效率。
2. **索引型数据库**:如Elasticsearch,用于快速全文检索和数据分析。在上述例子中,异步写服务会将数据更新推送到索引型数据库,便于进行复杂查询和分析,但不适用于实时更新。
3. **时序型数据库**:如InfluxDB或OpenTSDB,专门处理按时间序列排列的数据,常用于监控和日志记录。数据聚合服务会将次要数据源的数据聚合到这里,供监控查询服务查询历史趋势。
4. **文档型数据库**:如MongoDB,适合存储非结构化或半结构化数据,提供灵活的数据模型。异步写服务也会更新文档型数据库,以备不时之需,例如用于报告或备份。
5. **缓存型数据库**:如Redis,提供高速的数据读取和临时存储,常用于减少对后端数据库的压力。同步写服务会将重要数据即时落地并放入缓存,提高读取速度。
这种架构设计考虑了数据的实时性、一致性、可扩展性和查询性能。通过组合使用这些数据库,可以实现数据的高效管理和灵活访问,满足各种业务需求。例如,读写服务可以根据数据的重要性和实时性选择不同的数据库,而数据查询服务则根据需求动态路由,选择最适合的数据源。
理解并合理运用这些存储技术是构建高性能、高可用互联网架构的关键。它们不仅各自承担特定职责,还能通过适当的设计和协调,共同优化整个系统的性能和稳定性。在实际操作中,需要根据业务特性和性能指标,灵活调整和优化这些组件,以实现最佳的系统效能。
朱晔的互联网架构实践心得 S1E3:相辅相成的存储五件套
【下载本文 PDF 进行阅读】
这里所说的五件套是指关系型数据库、索引型数据库、时序型数据库、文档型数据库和缓存型
数据库。
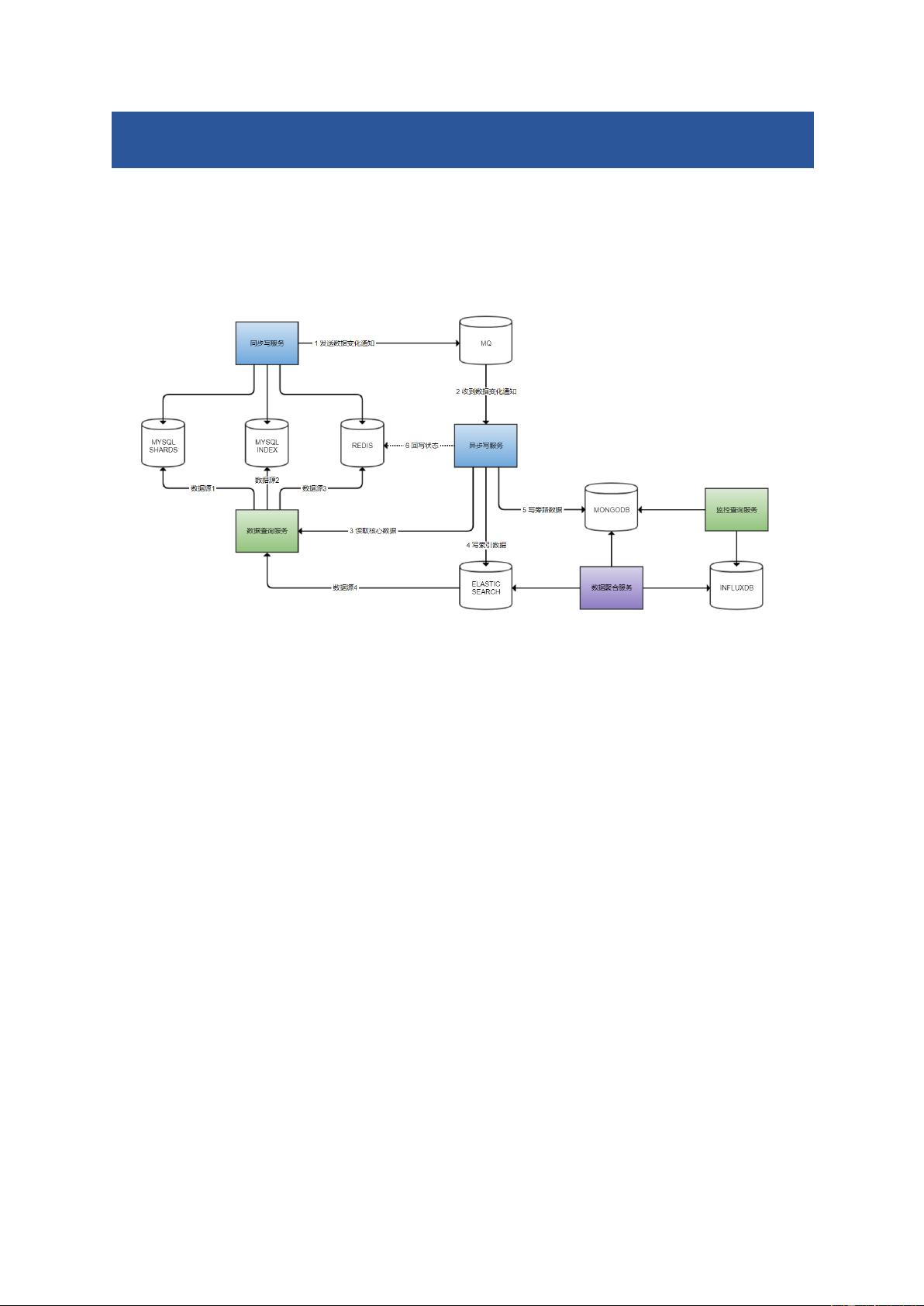
上图显示了一套读写服务搭配这五种类型数据库的例子:
1. 这里只是说明了我们可以这么来搭配这些类型的数据库,不是说我们所有的应用都需
要用到这些类型的数据库。
2. 同步写服务负责第一时间把重要的数据落地和落缓存。
3. 异步写服务通过监听 MQ 来感知数据的变化,然后重新读取最新的数据来把数据写入
其它次要数据源,比如文档性数据库和索引型数据库,需要的话可以在缓存中回写一
个状态。
4. 由一个专门的数据查询服务来根据需求做数据路由,根据需求和性能因素,从不同的
数据源读取数据。
5. 数据聚合服务根据需求从次要数据源进一步读取数据以时间维度进行聚合,聚合到时
间序列数据库,供监控查询服务查询。
下面我们来具体说说这些存储系统。
下载后可阅读完整内容,剩余5页未读,立即下载
142 浏览量
2021-12-25 上传
2022-12-24 上传
2021-09-06 上传
2021-09-20 上传
2019-09-26 上传
2021-07-12 上传
2021-09-04 上传

凌哥在奔跑
- 粉丝: 2
- 资源: 2
 我的内容管理
展开
我的内容管理
展开







最新资源
- WordPress作为新闻管理面板的实现指南
- NPC_Generator:使用Ruby打造的游戏角色生成器
- MATLAB实现变邻域搜索算法源码解析
- 探索C++并行编程:使用INTEL TBB的项目实践
- 玫枫跟打器:网页版五笔打字工具,提升macOS打字效率
- 萨尔塔·阿萨尔·希塔斯:SATINDER项目解析
- 掌握变邻域搜索算法:MATLAB代码实践
- saaraansh: 简化法律文档,打破语言障碍的智能应用
- 探索牛角交友盲盒系统:PHP开源交友平台的新选择
- 探索Nullfactory-SSRSExtensions: 强化SQL Server报告服务
- Lotide:一套JavaScript实用工具库的深度解析
- 利用Aurelia 2脚手架搭建新项目的快速指南
- 变邻域搜索算法Matlab实现教程
- 实战指南:构建高效ES+Redis+MySQL架构解决方案
- GitHub Pages入门模板快速启动指南
- NeonClock遗产版:包名更迭与应用更新
