深度探索Spark Structured Streaming中的状态化流处理
需积分: 9 4 浏览量
更新于2024-07-18
1
收藏 6.29MB PDF 举报
深入探讨Spark Streaming中的有状态流处理
在2018年的Spark Summit上,Tathagata Das(@tathadas)在5月5日于旧金山的一场演讲中对Spark Streaming的有状态流处理进行了深度剖析。Spark Streaming作为Spark SQL引擎上的流处理框架,提供了快速、可扩展且容错的特性,它的设计旨在简化复杂数据和工作负载的处理,通过统一、高级的API接口,让开发者无需过多关注底层细节即可编写简单的查询。
Spark Streaming的核心理念是将流视为无限表,数据流相当于一个无界的输入表,新数据的到来就等于向这个无限表中追加新的行。这种设计使得开发人员可以轻松地处理持续的数据流,就像处理静态数据一样,只需要写入简单的SQL查询,而Spark会持续更新结果。
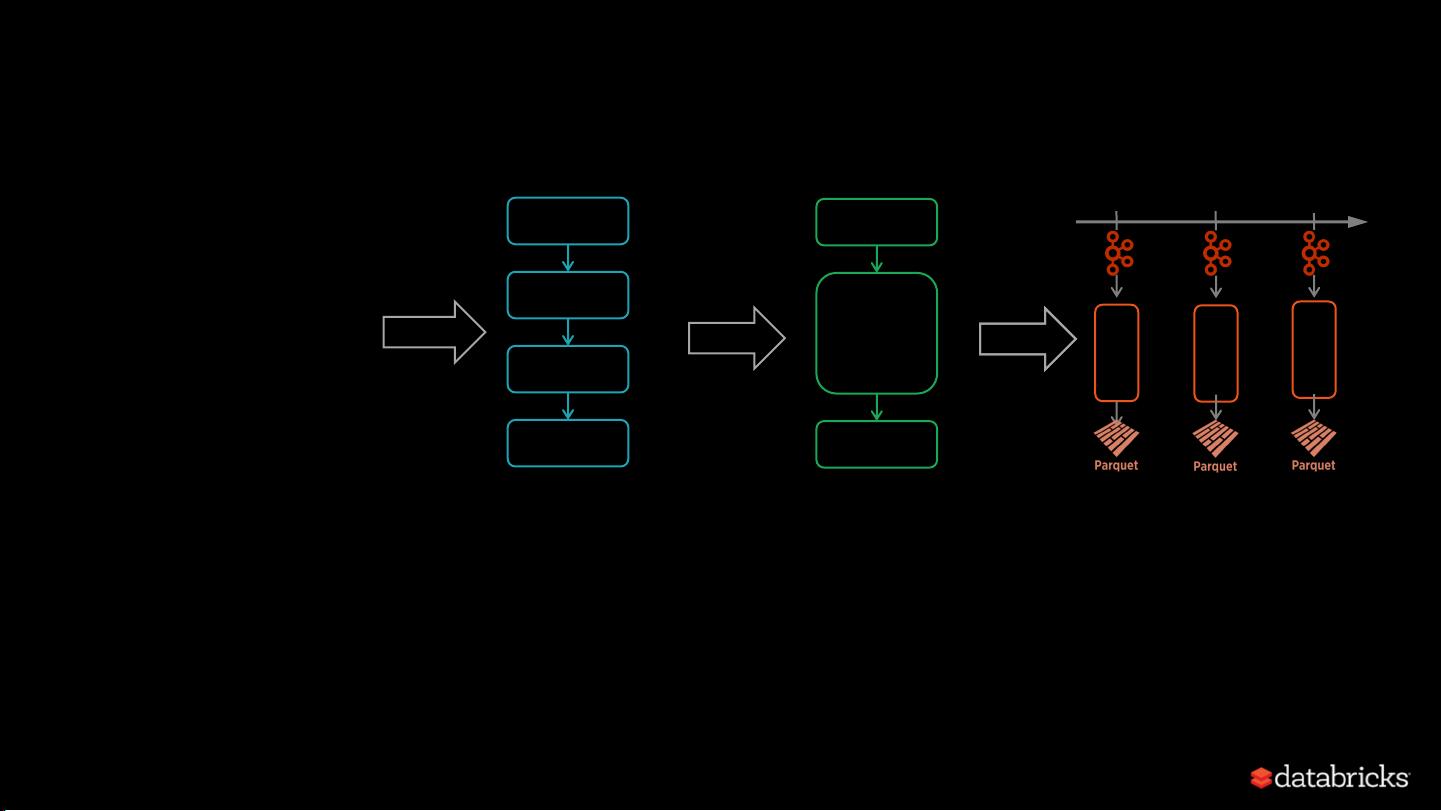
一个典型的Spark Streaming查询包含了以下几个步骤:
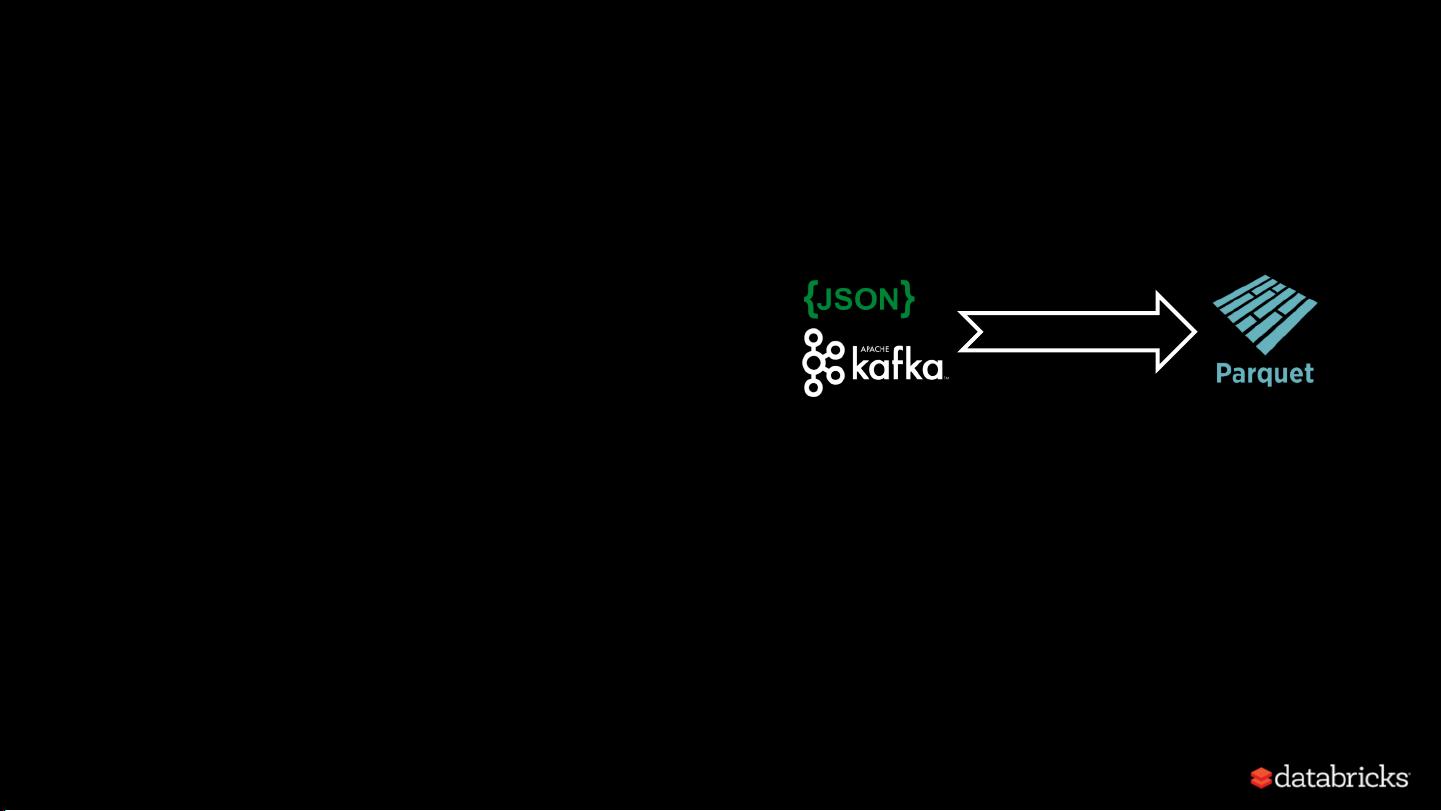
1. **读取数据源**:使用`spark.readStream.format()`方法指定数据源,例如从Kafka读取JSON数据。该API支持内置的文件系统(如本地文件)和Kafka、Kinesis等外部数据源。在Databricks Runtime中,还可以利用这些内置支持处理不同类型的数据源,如多个Kafka主题的联合或合并。
```scala
val stream = spark.readStream.format("kafka")
.option("kafka.bootstrap.servers", "your_servers")
.option("subscribe", "your_topic")
.load()
```
2. **解析数据**:对于读取的JSON数据,可能需要进行解析,比如处理嵌套的JSON结构,这通常通过Spark SQL的内置函数或自定义UDF(用户定义函数)来完成。
3. **存储结果**:处理后的数据被存储在结构化的Parquet表中,这样可以方便后续的数据分析和查询。
4. **确保故障恢复**:Spark Streaming提供端到端的故障恢复保证,即使在处理过程中发生错误,系统也能自动检测并重新计算丢失的数据,从而确保查询结果的准确性。
在这个架构中,有状态流处理允许在数据流上执行类似ETL(提取、转换、加载)的过程,但更加实时和高效。开发人员不必担心底层的并发控制和消息处理机制,只需关注业务逻辑的编写,这极大地提高了开发效率和系统的可维护性。
Spark Streaming作为Spark生态系统的一部分,以其强大的功能和易用性,简化了流处理任务的开发和部署,为现代大数据处理提供了强大而灵活的工具。无论是数据科学家还是应用开发者,都可以通过学习和实践这一技术来应对不断增长的数据挑战。
DataFrames,
Datasets, SQL
Logical
Plan
Read from
Kafka
Project
device, signal
Filter
signal > 15
Write to
Parquet
Spark automatically streamifies!
Spark SQL converts batch-like query to a series of incremental
execution plans operating on new micro-batches of data
Kafka
Source
Optimized
Operator
codegen, off-
heap, etc.
Parquet
Sink
Optimized
Plan
spark.readStream.format("kafka")
.option("kafka.boostrap.servers",...)
.option("subscribe", "topic")
.load()
.selectExpr("cast (value as string) as json")
.select(from_json("json", schema).as("data"))
.writeStream
.format("parquet")
.option("path", "/parquetTable/")
.trigger("1 minute")
.option("checkpointLocation", "…")
.start()
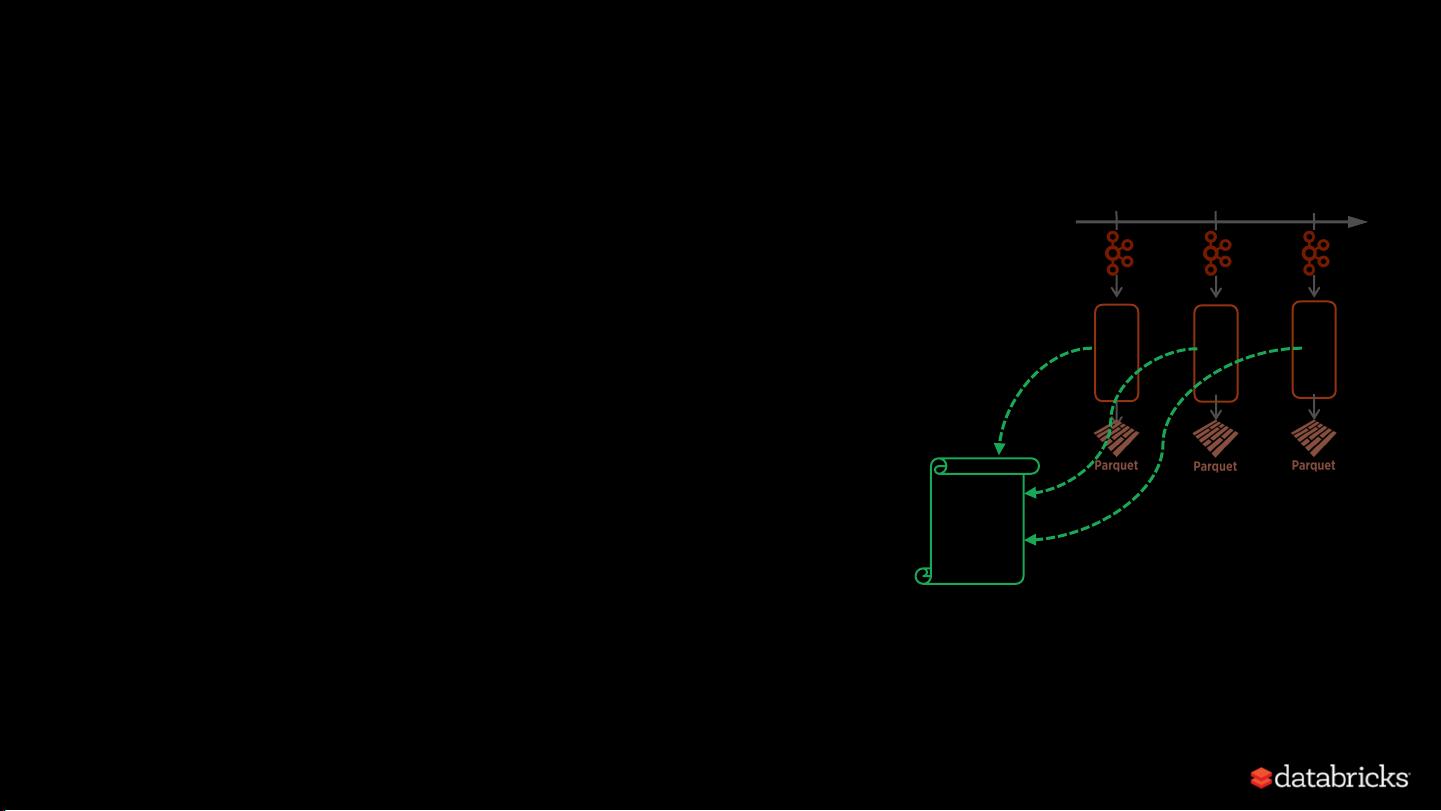
Series of Incremental
Execution Plans
process
new data
t = 1 t = 2
t = 3
process
new data
process
new data
剩余66页未读,继续阅读
2019-01-10 上传
2018-07-18 上传
2014-05-29 上传
2018-06-11 上传
2014-03-30 上传
2018-12-14 上传

过往记忆
- 粉丝: 4373
- 资源: 275
 我的内容管理
展开
我的内容管理
展开







最新资源
- 高清艺术文字图标资源,PNG和ICO格式免费下载
- mui框架HTML5应用界面组件使用示例教程
- Vue.js开发利器:chrome-vue-devtools插件解析
- 掌握ElectronBrowserJS:打造跨平台电子应用
- 前端导师教程:构建与部署社交证明页面
- Java多线程与线程安全在断点续传中的实现
- 免Root一键卸载安卓预装应用教程
- 易语言实现高级表格滚动条完美控制技巧
- 超声波测距尺的源码实现
- 数据可视化与交互:构建易用的数据界面
- 实现Discourse外聘回复自动标记的简易插件
- 链表的头插法与尾插法实现及长度计算
- Playwright与Typescript及Mocha集成:自动化UI测试实践指南
- 128x128像素线性工具图标下载集合
- 易语言安装包程序增强版:智能导入与重复库过滤
- 利用AJAX与Spotify API在Google地图中探索世界音乐排行榜
