非任务型多轮对话系统:检索式聊天机器人解析
版权申诉
181 浏览量
更新于2024-08-04
收藏 1.25MB PDF 举报
"多轮对话与检索式聊天机器人(chatbot)综述.pdf"
本文主要探讨的是非任务型对话,特别是检索式聊天机器人的工作原理和应用。聊天机器人,尤其是近年来在业界广泛应用的检索式chatbot,已经成为自然语言处理(NLP)领域的一个热门话题。随着科技巨头如微软、百度、阿里巴巴、腾讯和搜狗等公司推出各自的对话系统,如小冰、DuerOS、UNIT、小蜜和汪仔,多轮对话技术在智能客服和人机交互中的重要性日益凸显。
首先,我们需要理解对话系统的分类。文本对话系统主要分为任务型和非任务型。任务型对话旨在帮助用户完成特定任务,如设置闹钟或发送短信,而非任务型对话则更接近人类之间的日常闲聊。本文重点介绍非任务型对话,特别是多轮对话,它涉及更复杂的上下文理解和持续性。
检索式对话模型是实现这种对话的一种方法。该模型的基础是建立一个大规模的知识库,包含大量的query-response对,这些对可以从社交媒体平台如豆瓣、贴吧等获取。当用户发起一个新的对话轮次时,系统会将前一次的回复作为查询(query),利用信息检索技术,如倒排索引和TF-IDF或BM25算法,来从知识库中找到最匹配的响应(response)。
检索式模型的优势在于其效率和准确性,因为它可以直接从已有的响应库中选择最适合的回答,而不需生成全新的内容。然而,这种方法的局限性在于,如果知识库中没有与当前对话情境完全匹配的响应,chatbot可能无法提供非常自然或具有创造性的回答。
为了改善检索式模型的局限性,研究人员提出结合生成式模型的方法。生成式模型通过训练学习对话的历史,然后生成新的回应。这种方式可以提供更为个性化和灵活的对话体验,但可能会面临生成内容的质量控制和一致性挑战。
此外,还有混合型模型,它们结合了检索和生成的特点,例如使用生成模型来重新排名检索结果,或者生成新的响应以扩展知识库。这些方法试图平衡检索式模型的效率和生成式模型的灵活性。
检索式聊天机器人在当前的聊天bot领域占据着重要位置,但随着人工智能技术的发展,生成式和混合型模型有望进一步提升对话系统的自然度和用户体验。未来的研究将继续探索如何更好地模拟人类对话,包括理解上下文、处理模糊性和进行个性化的交互,以推动聊天机器人的智能化水平。
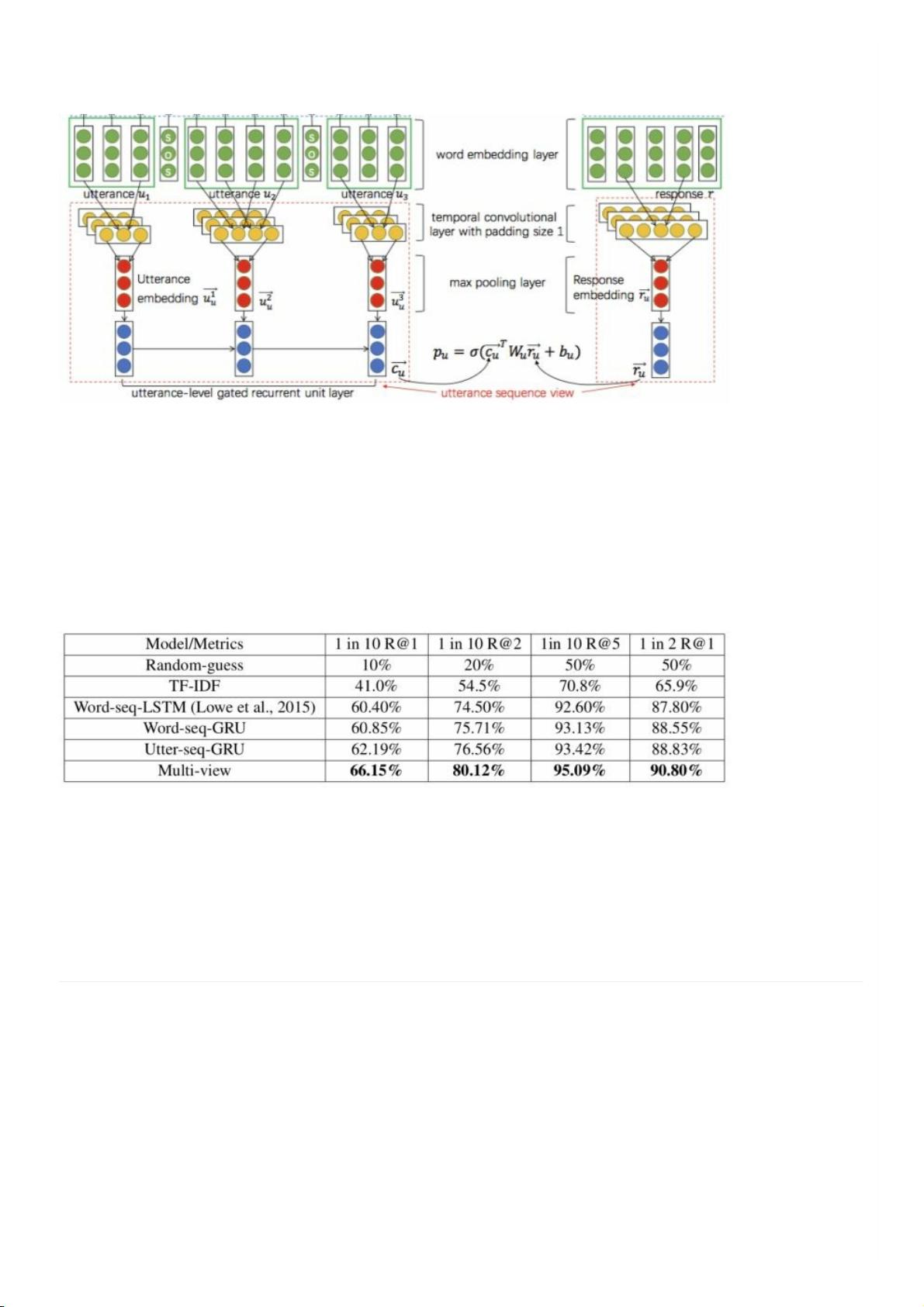
聪明的童鞋肯定可以想到,显然这种将⻓⻓的word embedding sequence直接塞进⽹络得到整个多轮对话的表⽰(context
embedding)的做法未免太看得起神经⽹络对⽂本的表⽰能⼒了,因此作者提出,不仅要在这个word-level上进⾏匹配,⽽
且还要在⼀个更⾼的level上进⾏匹配,这个level称为utterance-level(即把对话中的每条⽂本(utterance)看作word)。
如上图的绿⾊->⻩⾊->红⾊的部分,⾸先得到对话的每条⽂本(utterance)的向量表⽰(这⾥⽤的14年Kim提出的那个经典
CNN),这样历史的多轮对话就变成了⼀个utterance embedding sequence。之后再通过⼀层Gated RNN(GRU、LSTM
等)把⽆⽤的utterances中的噪声滤掉,进⽽取最后⼀个时刻的隐状态得到整个多轮对话(context)的context embedding
啦。
拿到context embedding后,就可以跟之前word-level中的做法⼀样,得到对话与candidate response的匹配概率啦。最后,
将word-level得到的匹配概率与utterance-level得到的匹配概率加起来就是最终的结果。
实验结果如下
可以看到utterance-level确实是明显⽐word-level work的,⽽且集成⼀下提升效果更显著。因此从这篇论⽂后的⼤部分论⽂
也follow了这种对每条utterance分别进⾏处理(表⽰或交互),⽽后对utterance embedding sequence⽤Gated RNN进⾏过
滤和得到context embedding的思路。
⽽到了2017年,⽂本匹配的研究明显变得更加成(花)熟(哨),各种花式attention带来了匹配效果的⼤幅度提升,这也
标志着检索式多轮对话这⽅⾯的玩法也将变得丰(⿇)富(烦)。
⼀次⼤⼤的进化:SMN model
如果说Multi-view模型在检索式多轮对话领域开了个好头,那么SMN则是将这个⼤框架往前推进了⼀⼤步。虽然表⾯上看
Multi-view模型与SMN模型相去甚远,但是熟悉⽂本匹配的⼩伙伴应该有注意到,16年左右,基于交互的匹配模型开始代替
基于表⽰的匹配模型成为主流[6],因此在Multi-view中内嵌的匹配模型是基于表⽰的,⽽到了17年的这个SMN模型则使⽤了
前沿的基于交互的匹配⽅法。另外除了改变⽂本匹配的“派系”之外,SMN还有⼀个⽐较亮的操作是在做⽂本匹配的时候考虑
了⽂本的不同粒度 (granularity) 之间的匹配,这个操作也成为了后续⼀些paper的follow的点。
对⽂本匹配⽐较熟悉的同学应该在AAAI2016看过这么⼀篇paper:
剩余10页未读,继续阅读
2023-10-18 上传
2021-07-23 上传
2021-08-14 上传
2023-03-07 上传
2021-07-21 上传
2024-05-30 上传
373 浏览量
2019-07-19 上传
2021-09-26 上传

地理探险家
- 粉丝: 1257
- 资源: 5610
 我的内容管理
展开
我的内容管理
展开







最新资源
- C++ Qt影院票务系统源码发布,代码稳定,高分毕业设计首选
- 纯CSS3实现逼真火焰手提灯动画效果
- Java编程基础课后练习答案解析
- typescript-atomizer: Atom 插件实现 TypeScript 语言与工具支持
- 51单片机项目源码分享:课程设计与毕设实践
- Qt画图程序实战:多文档与单文档示例解析
- 全屏H5圆圈缩放矩阵动画背景特效实现
- C#实现的手机触摸板服务端应用
- 数据结构与算法学习资源压缩包介绍
- stream-notifier: 简化Node.js流错误与成功通知方案
- 网页表格选择导出Excel的jQuery实例教程
- Prj19购物车系统项目压缩包解析
- 数据结构与算法学习实践指南
- Qt5实现A*寻路算法:结合C++和GUI
- terser-brunch:现代JavaScript文件压缩工具
- 掌握Power BI导出明细数据的操作指南
