




感知机详解:基础、损失函数与学习算法
需积分: 8 95 浏览量
更新于2024-07-15
收藏 158KB DOCX 举报
"本资源是一份关于李航统计机器学习的公司推导和简介版知识的缩略版Word文档,作者通过读书笔记的形式整理了机器学习中的一个重要概念——感知机。感知机是一种基础的判别模型,其目标是找到能够最大化区分训练数据的分离超平面。学习策略的核心是定义经验损失函数,即误分类点到超平面的距离总和,并通过最小化这个函数来优化模型参数w和b。
感知机模型的求解过程涉及梯度下降法,即随机选取一个误分类点,每次更新w和b以使其朝着错误方向移动,直到没有误分类点为止。算法的初始步骤包括随机选择初值,然后检查每个实例点,如果被误分类,就调整权重。算法保证了在训练数据线性可分的情况下,误分类次数k与超平面数量R的关系为K≤R。
感知机的学习算法特别关注0范数、1范数和2范数的定义,这些是衡量向量特征的重要方式。0范数计数非零元素,1范数为绝对值之和,而2范数即欧几里得范数,表示向量的模。算法的收敛性分析证明了当数据线性可分时,误分类次数是有上限的。
此外,文档还提到了感知机算法的对偶形式,这是一种不同的优化视角,虽然原始形式主要关注w和b的修改,但对偶形式可能会提供更高效的学习策略。对偶形式通常用于解决凸优化问题,有助于理解感知机算法在更广泛优化理论背景下的位置。
这份文档提供了深入浅出的感知机学习基础,包括其模型构建、优化方法、收敛性分析以及对偶形式的介绍,对于理解和实践统计机器学习具有一定的参考价值。"
选择大的值,相当于在较大的邻域内进行预测,减小了学习的估计误差,但是近似误
差会增大。
3. 分类决策规则-多数表决规则
4. k 近邻的实现:kd 树
原因:实现 k 近邻时候主要考虑如何实现快速 k 近邻搜索
最简单的方法是线性扫描,这时需要计算输入实例和每一个训练实例的距离,训练集大时
不可取,为了提高 k 近邻搜索的效率,可以考虑使用特殊的结构存储数据,以减少计算距
离的次数。
Kd 树是一种对 k 维空间的实例点进行存储,以便其进行快速检索的树形存储结构,kd 树是
一颗二叉树,表示对二维空间的一个划分
构造 kd 树时候选择训练实例点子选定坐标轴上的中位数为切分点,这样选择的 kd 树是平
衡的,但是注意平衡的 kd 树未必是最优的;
对深度为 j 的结点,选择
x
(l)
为切分的坐标轴,l=j(modk)+1
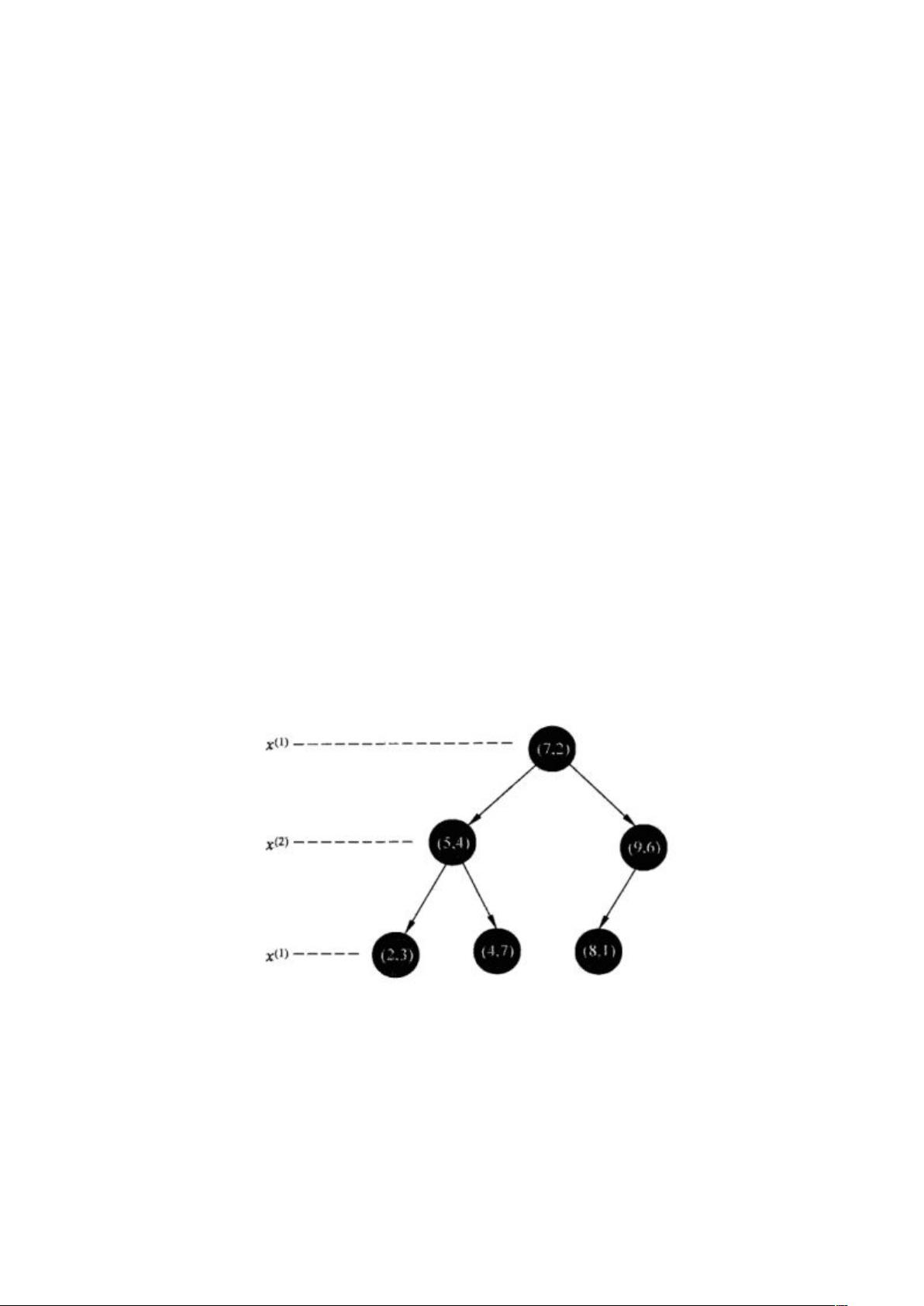
例:kd 树的划分方法:实例 T={(2,3),(5,4),(9,6),(4,7),(8,1),(7,2)}
按照第一维数据排序:23 47 54 72 81 96 节点选择为 72
72 将数据划分为两个点 23 47 54 和 81 96 选择第二个维度划分
23 47 57 排序为 23 54 47 结点是 54 左子树是 23 右子树是 47 96 左子树是 81
5. kd 树的搜索
例子一下为 kd 树,另外输入一个目标点 S,求 S 得最近邻
下载后可阅读完整内容,剩余33页未读,立即下载
2022-02-16 上传
2021-11-05 上传
2021-11-05 上传
606 浏览量
755 浏览量
640 浏览量
586 浏览量
552 浏览量
721 浏览量

wantyoutellmewhy
- 粉丝: 112
 我的内容管理
展开
我的内容管理
展开







最新资源
- Android应用-Goldcard-Helper使用教程
- 探索iOS静态库中集成XIB文件的实现方法
- 51单片机实现1602液晶显示秒表的设计与实现
- LPC1768 EasyWEB网络开发与测试指南
- WebGIS地图开发实用代码示例与压缩技术
- ColorCols:挑战色彩匹配的开源平台游戏
- C++实现公司工资管理系统:增删改查与链表文件存储
- Android应用崩溃模拟工具Krasha介绍
- UDF编程心得:经验总结与推荐
- Craters.js:轻量级HTML5游戏引擎的构建与特性介绍
- 基于信息技术的学生考勤签到系统设计
- Golden Software Surfer 11.0.642汉化教程与win7兼容性
- 深入剖析Android热修复技术原理及应用
- 王晓东编著《数据结构与STL框架》PPT解析
- 51单片机实现可调占空比PWM方波输出教程
- C语言高精度加法算法实现与应用






















