Python爬虫入门:避开法律风险,掌握通用与聚焦爬虫
需积分: 10 45 浏览量
更新于2024-08-26
收藏 522KB DOCX 举报
本资源是一份针对Python爬虫入门的教学文档,于2021年4月15日更新。文档旨在引导学习者了解和掌握爬虫的基本概念和技术,以及在实际应用中需要注意的问题。爬虫是一种通过编程技术模拟浏览器行为,从互联网上抓取数据的过程,它在信息检索、数据分析等领域有广泛应用。
文档首先介绍了爬虫的动机,比如满足个人需求,如获取特定信息或学习资料。爬虫的价值在于帮助人们获取网络上的信息,但同时也存在潜在风险,如合法性问题。合法的爬虫并不违反法律,但若使用不当,例如大规模侵犯网站隐私或破坏网站运营,就可能触犯法律。因此,学习者需要理解如何在合规的前提下使用爬虫,如优化代码减少干扰,审查数据内容并确保不侵犯版权和隐私。
接下来,文档详细讨论了爬虫的分类:
1. 通用爬虫:适用于广泛抓取网站上的信息,是基础架构。
2. 聚焦爬虫:专门针对特定页面或部分内容,增强抓取的精准度。
3. 增量式爬虫:监控数据更新,仅抓取新出现的内容,节省资源。
文档还提到了爬虫面临的挑战,即网站通常会采用反爬机制来防止被非法抓取,如设置Robots.txt协议来指定可爬取内容。学习者需要了解如何解读和应对这些限制。同时,文档介绍了HTTP和HTTPS协议的基本概念,包括请求头和响应头信息,强调了HTTPS的安全特性及其加密方式,如对称密钥加密、非对称密钥加密和证书密钥加密。
最后,作者提醒,虽然爬虫技术看似简单,但课程内容深入浅出,适合用Python进行实践,仅20多个课时的内容就足以建立起坚实的基础。因此,对于希望学习Python爬虫的读者来说,这是一份实用且富有指导性的教学材料。
爬虫入门-2021-4-15
前戏:
1,你是否在夜深人静的时候,想看一些会让你更睡不着的图片....
2,你是否在考试或者面试前夕,想看一些具有针对性的题目和面试题.
3,你是否想在杂乱的网络世界中获取你想要的数据...
什么是爬虫:
—通过编写程序,模拟浏览器上网,然后,让其去互联网抓取数据的过程。
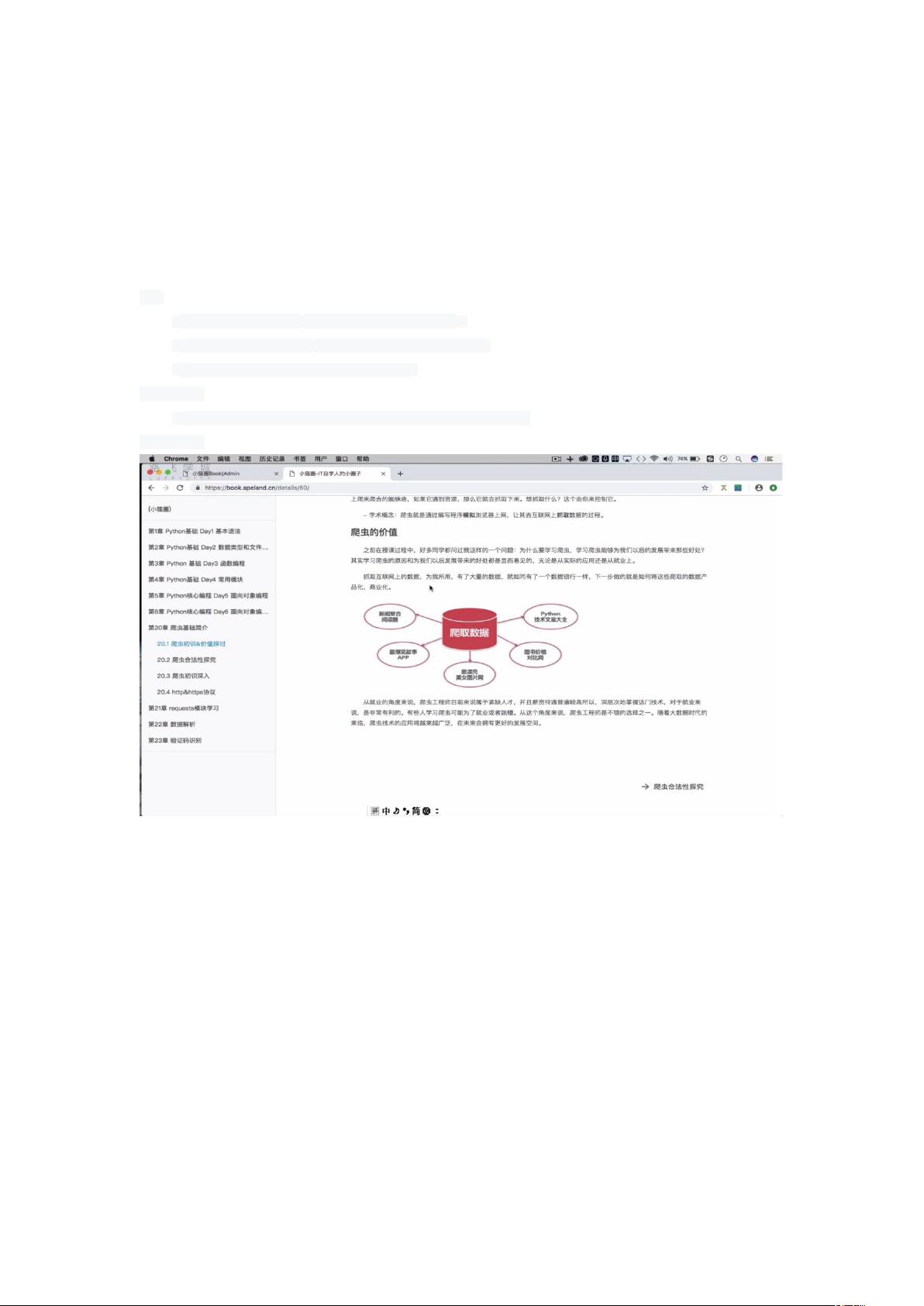
爬虫的价值:
实际应用:就业
爬虫究竟是合法还是违法的?
— 在法律中是不被禁止
— 具有违法风险——利用黑客技术攻击别人后台,窃取别人数据。
— 善意爬虫 恶意爬虫——大量攻击 12306(购票网站)
爬虫带来的风险可以体现在如下 2 方面:
— 爬虫干扰了被访问网站的正常运营
— 爬虫抓取了收到法律保护的特定类型的数据或信息
如何在使用编写爬虫的过程中避免进入局子子的厄运?
— 时常的优化自己的程序,避免干扰被访问网站的正常运行
— 在使用,传播爬取到的数据时,审查抓取到的内容,如果发现了涉及到用户因此
商机机密等敏感内容需要及时爬取或传播。
下载后可阅读完整内容,剩余4页未读,立即下载
2024-02-07 上传
2021-12-16 上传
2022-01-08 上传
2022-06-11 上传
2022-10-14 上传
2021-07-05 上传
2022-07-08 上传
2023-06-12 上传
2022-05-29 上传

九鼎科技-Leo
- 粉丝: 273
- 资源: 2
 我的内容管理
展开
我的内容管理
展开







最新资源
- 平尾装配工作平台运输支撑系统设计与应用
- MAX-MIN Ant System:用MATLAB解决旅行商问题
- Flutter状态管理新秀:sealed_flutter_bloc包整合seal_unions
- Pong²开源游戏:双人对战图形化的经典竞技体验
- jQuery spriteAnimator插件:创建精灵动画的利器
- 广播媒体对象传输方法与设备的技术分析
- MATLAB HDF5数据提取工具:深层结构化数据处理
- 适用于arm64的Valgrind交叉编译包发布
- 基于canvas和Java后端的小程序“飞翔的小鸟”完整示例
- 全面升级STM32F7 Discovery LCD BSP驱动程序
- React Router v4 入门教程与示例代码解析
- 下载OpenCV各版本安装包,全面覆盖2.4至4.5
- 手写笔画分割技术的新突破:智能分割方法与装置
- 基于Koplowitz & Bruckstein算法的MATLAB周长估计方法
- Modbus4j-3.0.3版本免费下载指南
- PoqetPresenter:Sharp Zaurus上的开源OpenOffice演示查看器
