电商日志数据处理:Spark SQL与Hive对比分析
需积分: 37 180 浏览量
更新于2024-07-18
1
收藏 946KB PDF 举报
"基于电商日志数据的Spark SQL开发"这一主题主要关注于在大数据处理领域中,Apache Spark框架如何与Hadoop MapReduce进行协作,特别是通过其内置模块Spark SQL来实现结构化数据的高效分析。Spark SQL是Spark生态系统中的一个重要组件,它为开发者提供了一种编程抽象——DataFrame,这使得数据操作更加直观和易于管理。
Spark SQL的设计目标是作为一个分布式的SQL查询引擎,它允许用户在大规模数据集上执行SQL查询,同时利用Spark的内存计算优势,显著提高了查询性能。相比于Hive,Spark SQL的优势在于它不仅支持SQL查询,还能够利用Scala或Python编程语言编写更复杂的ETL(提取、转换、加载)任务,并且可以直接操作Spark的RDD(弹性分布式数据集),这在处理实时数据流时显得尤为高效。
Hive架构在Spark SQL中起到了桥梁的作用,Hive本身是基于Hadoop MapReduce的,但Spark SQL能够将Hive的数据仓库模型无缝地整合到Spark的内存计算中。Spark SQL架构包括了数据源接口(如Hive表)、DataFrame API以及对SQL标准的支持,这让用户能够在Spark环境下享受到类似Hive的易用性,同时享受Spark的高性能计算能力。
数据类型是Spark SQL中的关键概念,它包括了数值类型(如整数、浮点数、二进制等)、字符串类型、布尔类型以及日期和时间类型。其中,TimestampType特别指出,它表示包含年、月、日、小时、分钟和秒的复合值,而DateType则专指日期部分,这些都是数据处理和分析过程中必不可少的元素。
基于电商日志数据的Spark SQL开发涉及到了如何利用Spark的高效分布式计算、DataFrame API和SQL查询能力,以及处理不同类型数据的技巧。通过理解和掌握这些知识点,开发者可以有效地在大数据环境中进行复杂的数据分析和处理,提升业务决策的效率和精度。
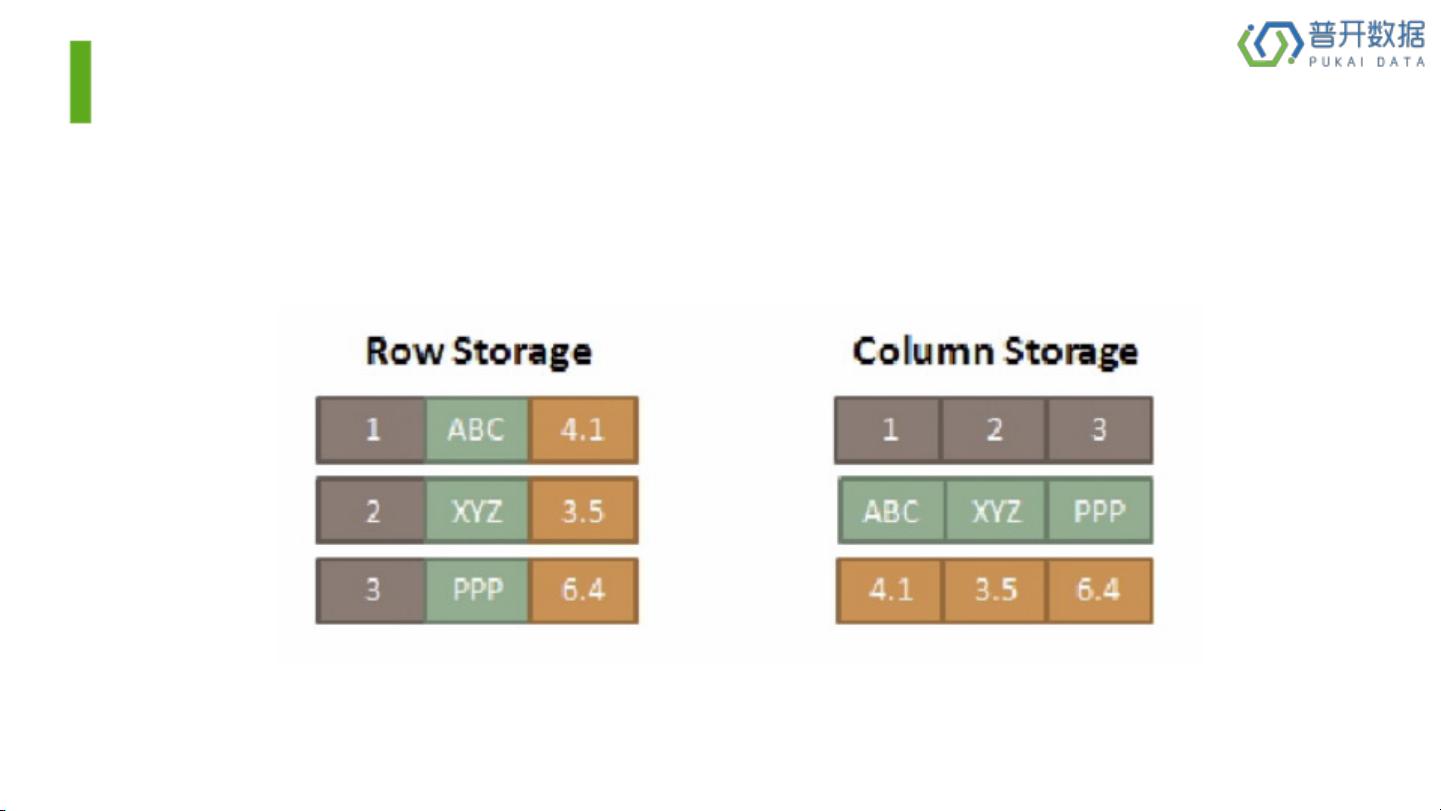
为什么快速
内存列式存储
剩余36页未读,继续阅读
2023-12-28 上传
2021-02-28 上传
2023-11-04 上传
点击了解资源详情
2021-11-24 上传
2024-04-02 上传
2019-03-13 上传
2023-07-31 上传
2022-12-10 上传

雨信康
- 粉丝: 3
- 资源: 34
 我的内容管理
展开
我的内容管理
展开







最新资源
- MATLAB实现小波阈值去噪:Visushrink硬软算法对比
- 易语言实现画板图像缩放功能教程
- 大模型推荐系统: 优化算法与模型压缩技术
- Stancy: 静态文件驱动的简单RESTful API与前端框架集成
- 掌握Java全文搜索:深入Apache Lucene开源系统
- 19计应19田超的Python7-1试题整理
- 易语言实现多线程网络时间同步源码解析
- 人工智能大模型学习与实践指南
- 掌握Markdown:从基础到高级技巧解析
- JS-PizzaStore: JS应用程序模拟披萨递送服务
- CAMV开源XML编辑器:编辑、验证、设计及架构工具集
- 医学免疫学情景化自动生成考题系统
- 易语言实现多语言界面编程教程
- MATLAB实现16种回归算法在数据挖掘中的应用
- ***内容构建指南:深入HTML与LaTeX
- Python实现维基百科“历史上的今天”数据抓取教程
