从线性模型到深度神经网络:TensorFlow中的非线性转换与优化策略
版权申诉
189 浏览量
更新于2024-08-08
收藏 230KB DOCX 举报
"这篇文档是关于使用TensorFlow进行深度学习的笔记,主要涵盖了从线性分类器到深度神经网络的概念和应用。"
在深度学习领域,TensorFlow是一个强大的开源库,它支持构建复杂的数学计算图,特别适用于训练大规模的神经网络。本笔记首先介绍了线性模型,线性模型在某些情况下是非常有用的,比如参数数量相对较少,如具有N个类别的K个特征的分类问题,需要调整的参数数量为(N+1)K。线性模型的优势在于计算效率高,因为GPU设计之初就是为了加速矩阵运算;同时,它们的输出稳定,对输入的微小变化反应有限,并且求导过程简单,易于优化。
然而,线性模型在处理非线性问题时显得力不从心。为了解决这个问题,人们引入了非线性变换,最常见的就是ReLU(Rectified Linear Unit)激活函数。ReLU将线性模型的输出转换为分段线性函数,增加了模型的表达能力,使得神经网络能够解决更复杂的问题。通过将多个包含ReLU的线性模型串联起来,可以构建神经网络,实现非线性组合。
神经网络的结构可以看作是多个层的堆叠,每个层包含多个线性模型(权重矩阵与偏置)和激活函数。链式法则(Chain Rule)在神经网络的反向传播(Backpropagation)过程中发挥关键作用,它允许我们有效地计算出网络中所有参数的梯度,以便于通过梯度下降等优化算法更新这些参数。反向传播在训练过程中,先正向传播计算损失,然后逆向计算梯度,其所需的计算资源是前向传播的两倍。
对于深度神经网络(Deep Neural Network),多层结构意味着信息在不同层次上逐步抽象和综合,使得模型能够捕捉到更复杂的模式。随着层数增加,参数数量可能会减少,但性能可能提升,因为高层可以捕获到低层无法获取的高级特征。然而,深度学习也面临过拟合的风险,即模型在训练数据上表现良好,但在未见过的数据上表现较差。
为了防止过拟合,有几种常见的策略:
1. 早停法(Early Termination):当模型在验证集上的性能开始下降时,提前结束训练。
2. 正则化(Regularization):如L2正则化,它在损失函数中添加了权重矩阵的L2范数,乘以一个超参数β来调整正则化的强度。L2正则化的梯度计算简单,有助于减少权重过大导致的过拟合。
3. Dropout:在训练过程中随机“丢弃”一部分神经元,以强制网络学习更鲁棒的表示。
超参数是预先设定的控制模型学习过程的参数,如学习率、批次大小和正则化强度等,它们通常需要通过实验来调整。如今,有了更好的正则化技术,我们能够训练更深、更复杂的神经网络,以适应各种不同的问题。在处理大数据时,更大的网络规模往往能带来更好的性能,但同时需要有效的正则化手段来避免过拟合。
Limit of Linear Model
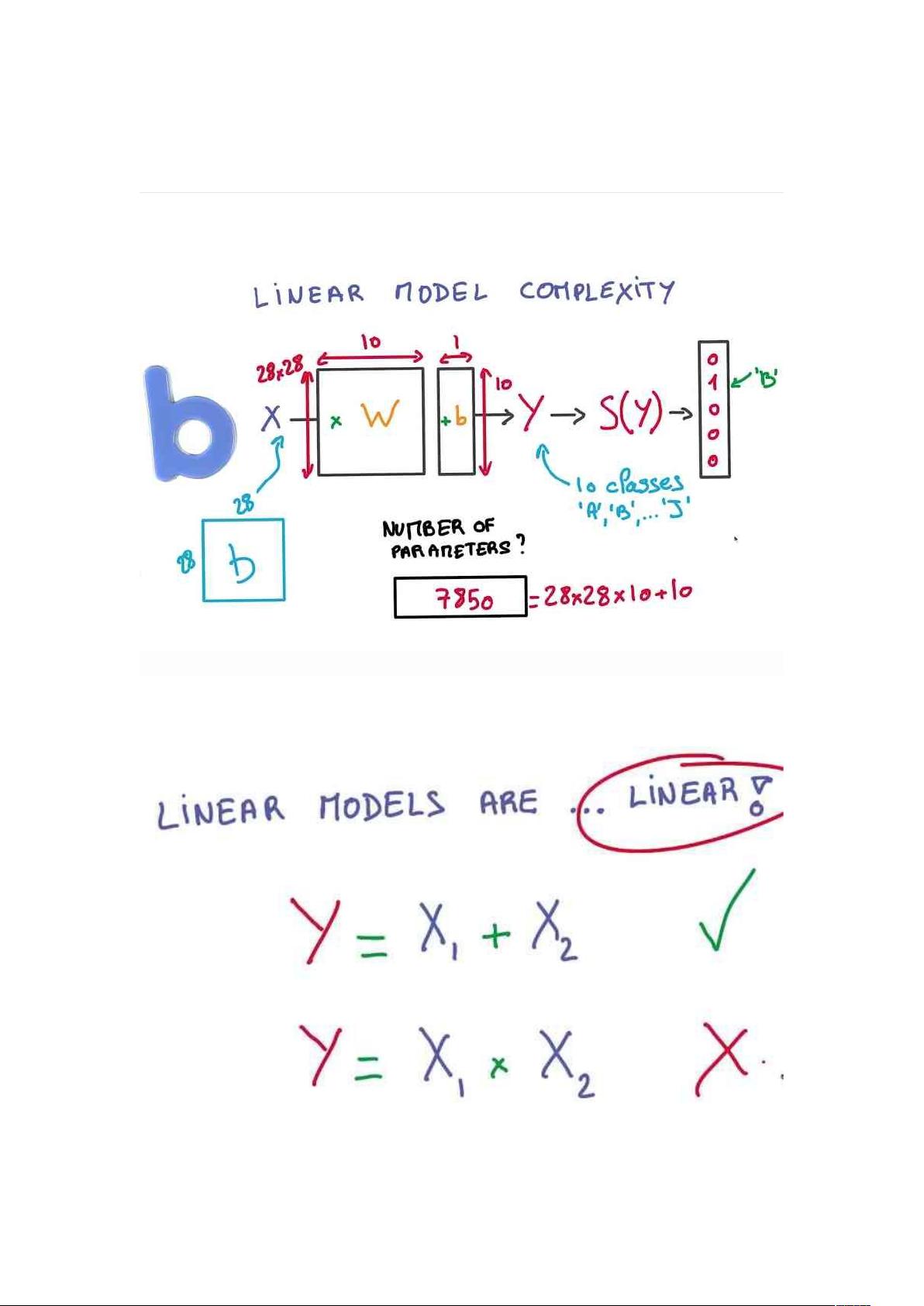
实际要调整的参数很多
如果有 N 个 Class,K 个 Label,需要调整的参数就有(N+1)K 个
Linear Model 不能应对非线性的问题
Linear Model 的好处
下载后可阅读完整内容,剩余8页未读,立即下载
点击了解资源详情
点击了解资源详情
159 浏览量
2024-02-04 上传
2021-03-17 上传
119 浏览量
218 浏览量
119 浏览量
102 浏览量

码农.one
- 粉丝: 7
- 资源: 345
 我的内容管理
展开
我的内容管理
展开







最新资源
- 晨光暖通计算工具 CGTools3.00官方版.7z
- Proy1_LenguajesFormales:事实
- Analysis-Sensors-Expo:6月26日至28日在圣何塞举行的2018 Sensors ExpoConference会议上的内容和发言人的分析
- LOVE主题电子产品网页模板
- Hotel-website
- java源码查看-plone-groupdocs-viewer-java-source:PloneGroupDocsViewerforJava
- 个人品牌建设——中层经理人培训ppt模板.rar
- 一款功能强大、配置灵活、带有全链路异常回调、内存优化、异常状态管理的高性能异步编排框架(多线程管理)。
- hadoop.rar
- 数据结构课设,包括五个实验,亲测可用
- fitness-tracker-json:用于为某些Fitness Tracker(版本<9)生成JSON数据
- 带有科技感的数据分析数据统计商务背景图片PPT模板
- 绿色生态远航网页模板
- java源码查看-dnn-groupdocs-viewer-java-source:DotNetNukeGroupDocsViewerJava
- Quick Terrain Reader.rar
- 两套配色方案简约精美iOS封面设计ppt模板.rar
